Documentation Index
Fetch the complete documentation index at: https://translations.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
_W&B Inference_는 W&B Weave 및 OpenAI 호환 API를 통해 주요 오픈소스 파운데이션 모델에 대한 액세스를 제공합니다. W&B Inference를 사용하면 다음을 수행할 수 있습니다:
- 호스팅 제공업체에 가입하거나 모델을 직접 호스팅하지 않고도 AI 애플리케이션과 에이전트를 개발할 수 있습니다.
- 지원되는 모델을 W&B Weave Playground에서 시험해 볼 수 있습니다.
W&B Inference 크레딧은 한시적으로 Free, Pro, Academic 요금제에 포함되어 제공됩니다. Enterprise의 경우 제공 여부가 달라질 수 있습니다. 크레딧을 모두 사용하면 다음이 적용됩니다:
- Free 계정은 Inference 사용을 계속하려면 Pro 요금제로 업그레이드해야 합니다.
- Pro 요금제 사용자는 모델별 요금에 따라 매월 Inference 초과 사용량에 대해 청구됩니다.
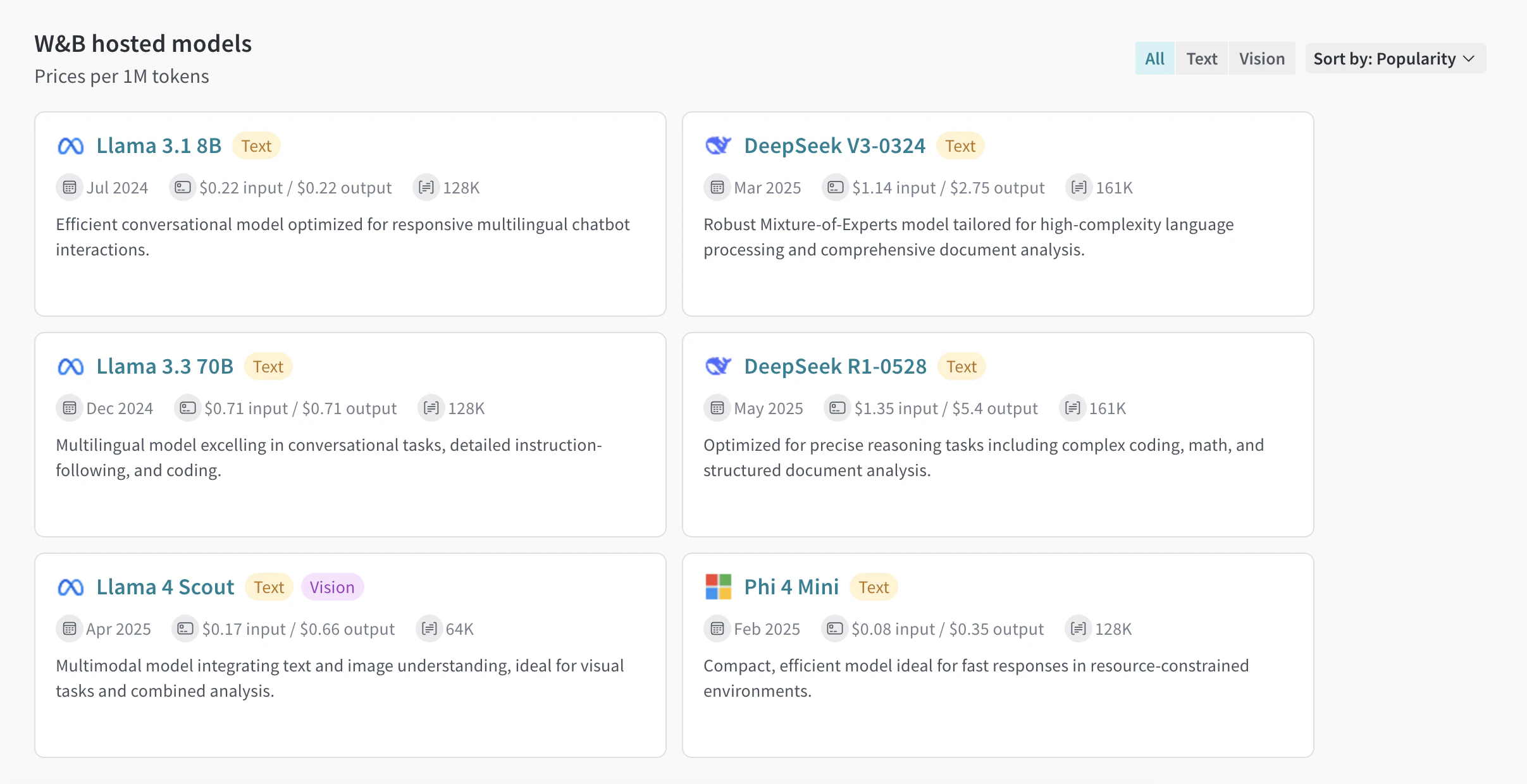
자세한 내용은 요금제(pricing) 페이지와 W&B Inference 모델 비용을 참조하세요. | Model | Model ID (for API usage) | Type(s) | Context Window | Parameters | Description |
|---|
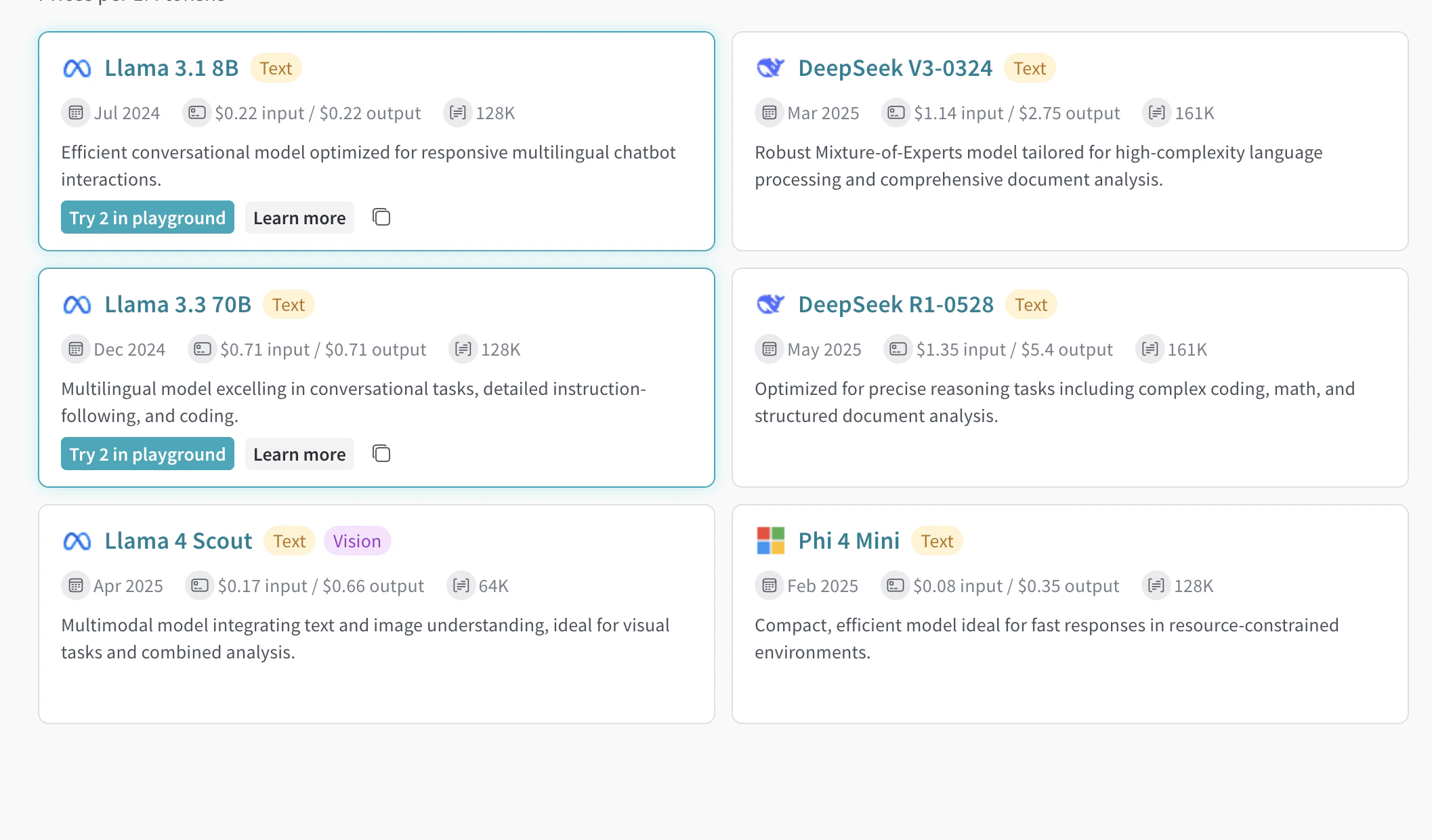
| DeepSeek R1-0528 | deepseek-ai/DeepSeek-R1-0528 | Text | 161K | 37B - 680B (Active - Total) | 복잡한 코딩, 수학, 구조화된 문서 분석을 포함한 정교한 추론 작업에 최적화된 모델입니다. |
| DeepSeek V3-0324 | deepseek-ai/DeepSeek-V3-0324 | Text | 161K | 37B - 680B (Active - Total) | 고난도 언어 처리와 포괄적인 문서 분석을 위해 설계된 강력한 Mixture-of-Experts 모델입니다. |
| Llama 3.1 8B | meta-llama/Llama-3.1-8B-Instruct | Text | 128K | 8B (Total) | 반응성이 뛰어난 다국어 챗봇 상호작용에 최적화된 효율적인 대화형 모델입니다. |
| Llama 3.3 70B | meta-llama/Llama-3.3-70B-Instruct | Text | 128K | 70B (Total) | 대화형 작업, 세밀한 지시사항 준수, 코딩에서 우수한 성능을 보이는 다국어 모델입니다. |
| Llama 4 Scout | meta-llama/Llama-4-Scout-17B-16E-Instruct | Text, Vision | 64K | 17B - 109B (Active - Total) | 텍스트와 이미지를 함께 이해하는 멀티모달 모델로, 시각 작업 및 결합 분석에 적합합니다. |
| Phi 4 Mini | microsoft/Phi-4-mini-instruct | Text | 128K | 3.8B (Active - Total) | 리소스가 제한된 환경에서 빠른 응답에 적합한 컴팩트하고 효율적인 모델입니다. |
- W&B 계정. 여기에서 가입합니다.
- W&B API key. User Settings에서 API key를 생성합니다.
- W&B 프로젝트.
- Python을 통해 Inference 서비스를 사용하는 경우, Python을 통해 API를 사용하기 위한 추가 사전 준비 사항을 확인하십시오.
Python을 통한 API 사용을 위한 추가 사전 요구 사항
openai 및 weave 라이브러리를 설치하세요.
LLM 애플리케이션 추적에 Weave를 사용하는 경우에만 weave 라이브러리가 필요합니다. Weave를 시작하려면 Weave 빠른 시작을 참조하세요.Weave와 함께 W&B Inference 서비스를 사용하는 방법을 보여 주는 예제는 API 사용 예제를 참조하세요. https://api.inference.wandb.ai/v1
이 엔드포인트에 액세스하려면 Inference 서비스 크레딧이 할당된 W&B 계정, 유효한 W&B API key, 그리고 W&B 엔터티(“team”이라고도 함)와 프로젝트가 필요합니다. 이 가이드의 코드 예제에서는 엔터티(팀)와 프로젝트를 <your-team>\<your-project>로 표기합니다.
/chat/completions이며, 지원되는 모델에 메시지를 보내고 completion 응답을 받기 위한 OpenAI 호환 요청 형식을 지원합니다. Weave와 함께 W&B Inference 서비스를 사용하는 방법에 대한 예시는 API 사용 예제를 참조하세요.
채팅 completion을 생성하려면 다음이 필요합니다:
- Inference 서비스 기본 URL
https://api.inference.wandb.ai/v1
- W&B API key
<your-api-key>
- W&B 엔터티 및 프로젝트 이름
<your-team>/<your-project>
- 사용하려는 모델의 ID (다음 중 하나):
meta-llama/Llama-3.1-8B-Instructdeepseek-ai/DeepSeek-V3-0324meta-llama/Llama-3.3-70B-Instructdeepseek-ai/DeepSeek-R1-0528meta-llama/Llama-4-Scout-17B-16E-Instructmicrosoft/Phi-4-mini-instruct
curl https://api.inference.wandb.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <your-api-key>" \
-H "OpenAI-Project: <your-team>/<your-project>" \
-d '{
"model": "<model-id>",
"messages": [
{ "role": "system", "content": "You are a helpful assistant." },
{ "role": "user", "content": "Tell me a joke." }
]
}'
import openai
client = openai.OpenAI(
# 커스텀 base URL은 W&B Inference를 가리킵니다
base_url='https://api.inference.wandb.ai/v1',
# https://wandb.ai/settings 에서 API key를 생성합니다
# 보안을 위해 환경 변수 OPENAI_API_KEY에 설정하는 것을 고려하세요
api_key="<your-api-key>",
# 사용량 추적을 위해 팀과 프로젝트가 필요합니다
project="<your-team>/<your-project>",
)
# <model-id>를 다음 값 중 하나로 바꾸세요:
# meta-llama/Llama-3.1-8B-Instruct
# deepseek-ai/DeepSeek-V3-0324
# meta-llama/Llama-3.3-70B-Instruct
# deepseek-ai/DeepSeek-R1-0528
# meta-llama/Llama-4-Scout-17B-16E-Instruct
# microsoft/Phi-4-mini-instruct
response = client.chat.completions.create(
model="<model-id>",
messages=[
{"role": "system", "content": "<your-system-prompt>"},
{"role": "user", "content": "<your-prompt>"}
],
)
print(response.choices[0].message.content)
curl https://api.inference.wandb.ai/v1/models \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <your-api-key>" \
-H "OpenAI-Project: <your-team>/<your-project>" \
import openai
client = openai.OpenAI(
base_url="https://api.inference.wandb.ai/v1",
api_key="<your-api-key>",
project="<your-team>/<your-project>"
)
response = client.models.list()
for model in response.data:
print(model.id)
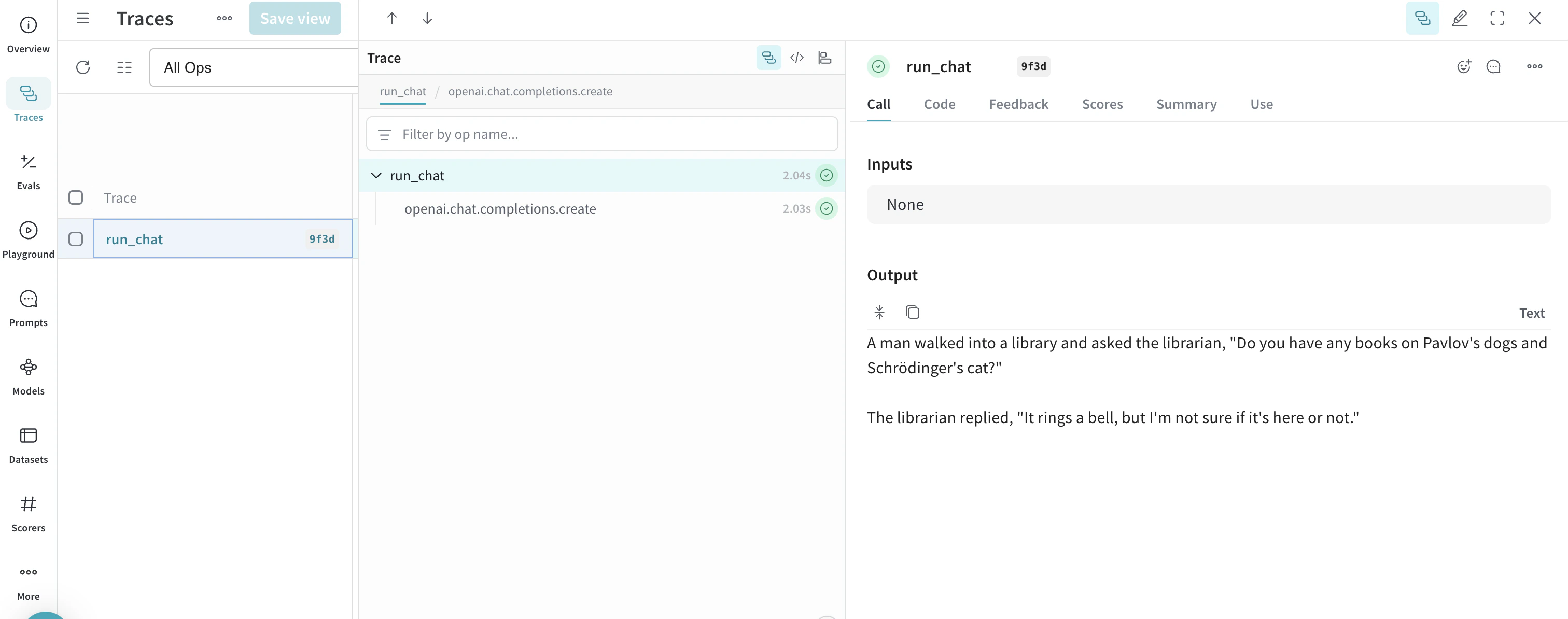
기본 예시: Weave로 Llama 3.1 8B 트레이스하기
- OpenAI 호환 클라이언트를 사용해 chat completion 요청을 보내는
run_chat 함수를 정의하고, 이를 @weave.op() 데코레이터로 감쌉니다.
- 트레이스는 W&B 엔터티와 프로젝트
project="<your-team>/<your-project>에 기록되고 연결됩니다.
- 이 함수는 Weave에 의해 자동으로 트레이스되므로, 입력, 출력, 지연 시간, 메타데이터(예: 모델 ID)가 모두 로그로 남습니다.
- 결과는 터미널에 출력되며, 지정한 프로젝트의 https://wandb.ai 내 Traces 탭에 해당 트레이스가 표시됩니다.
이 예시를 사용하려면 일반 사전 요구 사항과 Python을 통해 API를 사용할 때의 추가 사전 요구 사항을 완료해야 합니다.
import weave
import openai
# 추적을 위한 Weave 팀 및 프로젝트 설정
weave.init("<your-team>/<your-project>")
client = openai.OpenAI(
base_url='https://api.inference.wandb.ai/v1',
# https://wandb.ai/settings 에서 API key 생성
api_key="<your-api-key>",
# W&B 추론 사용량 추적에 필요
project="wandb/inference-demo",
)
# Weave에서 모델 호출 추적
@weave.op()
def run_chat():
response = client.chat.completions.create(
model="meta-llama/Llama-3.1-8B-Instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me a joke."}
],
)
return response.choices[0].message.content
# 추적된 호출 실행 및 로깅
output = run_chat()
print(output)
https://wandb.ai/<your-team>/<your-project>/r/call/01977f8f-839d-7dda-b0c2-27292ef0e04g)를 클릭해 Weave에서 트레이스를 확인하거나, 다음 단계를 따르세요:
- https://wandb.ai로 이동합니다.
- Traces 탭을 선택해 Weave 트레이스를 확인합니다.
다음으로 고급 예제를 시도해 보세요.
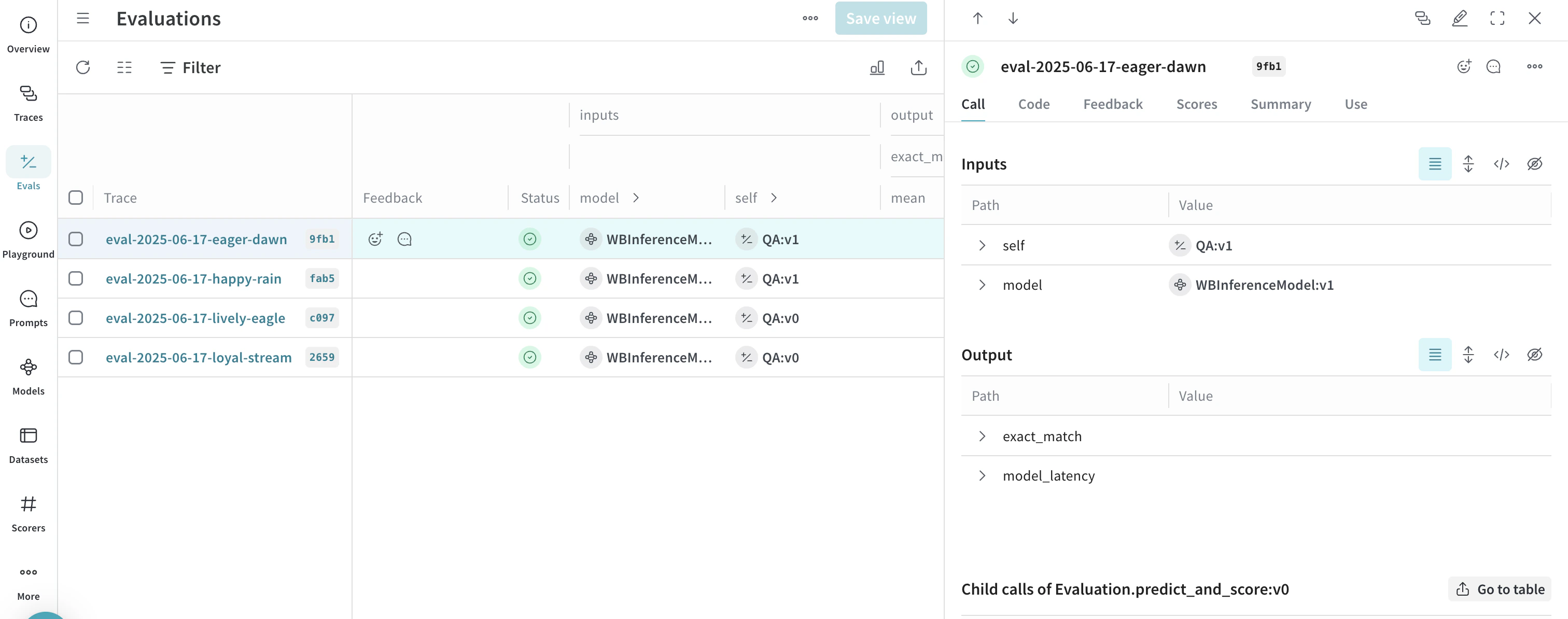
고급 예제: Inference 서비스에서 Weave Evaluations와 리더보드 사용하기
import os
import asyncio
import openai
import weave
from weave.flow import leaderboard
from weave.trace.ref_util import get_ref
# 추적을 위한 Weave 팀 및 프로젝트 설정
weave.init("<your-team>/<your-project>")
dataset = [
{"input": "What is 2 + 2?", "target": "4"},
{"input": "Name a primary color.", "target": "red"},
]
@weave.op
def exact_match(target: str, output: str) -> float:
return float(target.strip().lower() == output.strip().lower())
class WBInferenceModel(weave.Model):
model: str
@weave.op
def predict(self, prompt: str) -> str:
client = openai.OpenAI(
base_url="https://api.inference.wandb.ai/v1",
# https://wandb.ai/settings 에서 API key 생성
api_key="<your-api-key>",
# W&B inference 사용량 추적에 필요
project="<your-team>/<your-project>",
)
resp = client.chat.completions.create(
model=self.model,
messages=[{"role": "user", "content": prompt}],
)
return resp.choices[0].message.content
llama = WBInferenceModel(model="meta-llama/Llama-3.1-8B-Instruct")
deepseek = WBInferenceModel(model="deepseek-ai/DeepSeek-V3-0324")
def preprocess_model_input(example):
return {"prompt": example["input"]}
evaluation = weave.Evaluation(
name="QA",
dataset=dataset,
scorers=[exact_match],
preprocess_model_input=preprocess_model_input,
)
async def run_eval():
await evaluation.evaluate(llama)
await evaluation.evaluate(deepseek)
asyncio.run(run_eval())
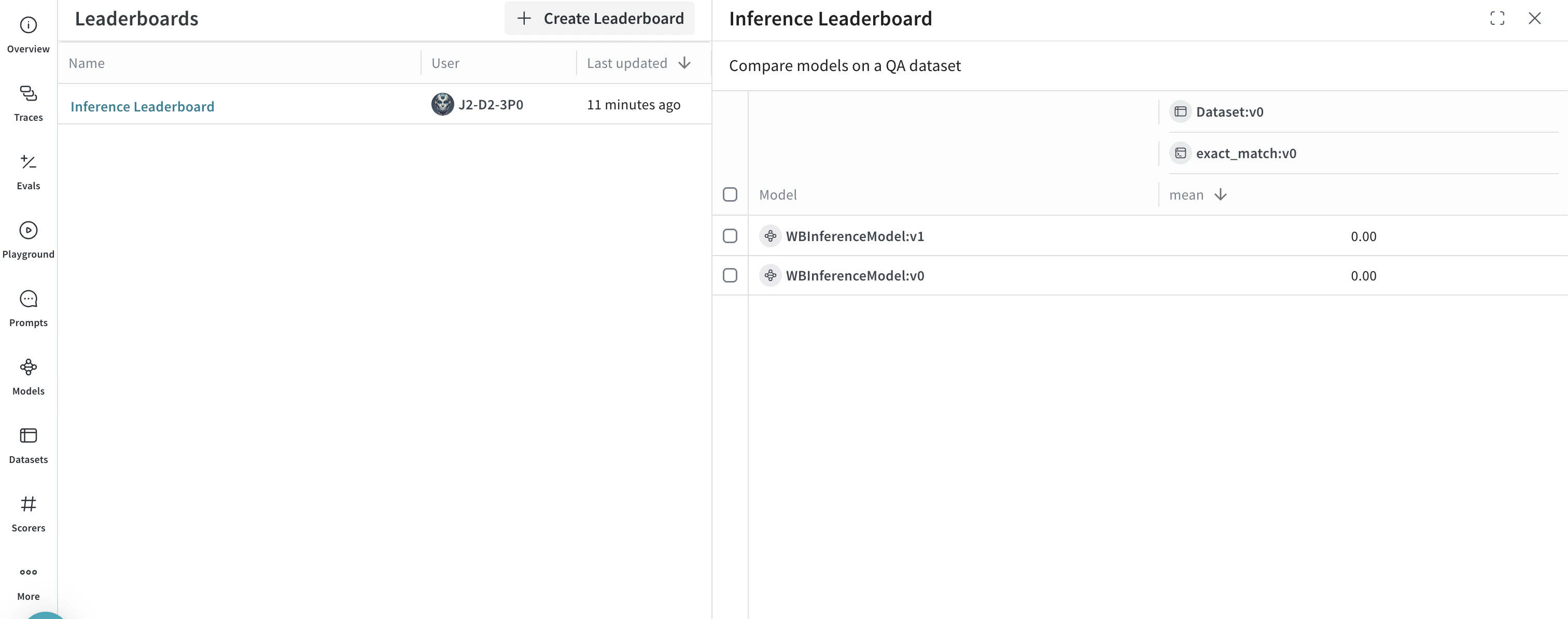
spec = leaderboard.Leaderboard(
name="Inference Leaderboard",
description="Compare models on a QA dataset",
columns=[
leaderboard.LeaderboardColumn(
evaluation_object_ref=get_ref(evaluation).uri(),
scorer_name="exact_match",
summary_metric_path="mean",
)
],
)
weave.publish(spec)
- https://wandb.ai/에서 W&B 계정에 접속합니다.
- 왼쪽 사이드바에서 Inference를 선택합니다. 사용 가능한 모델과 모델 정보가 표시된 페이지가 열립니다.
- 왼쪽 사이드바에서 Playground를 선택합니다. Playground 채팅 UI가 표시됩니다.
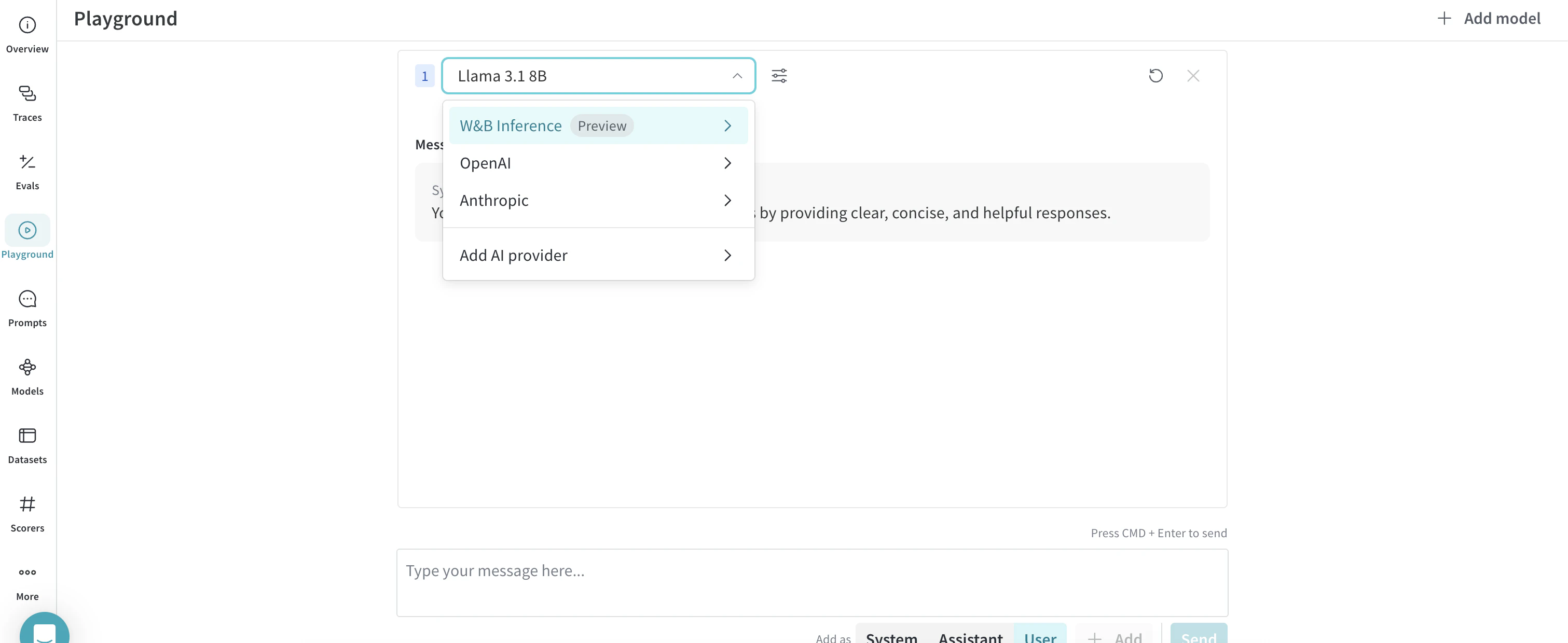
- LLM 드롭다운 목록에서 W&B Inference 위에 마우스를 올립니다. 오른쪽에 사용 가능한 W&B Inference 모델 드롭다운이 표시됩니다.
- W&B Inference 모델 드롭다운에서 다음을 수행할 수 있습니다:
액세스 옵션 중 하나를 사용해 모델을 선택한 후에는 Playground에서 해당 모델을 테스트할 수 있습니다. 다음 작업을 수행할 수 있습니다.
Playground에서 여러 Inference 모델을 비교할 수 있습니다. Compare 뷰는 두 가지 방법으로 열 수 있습니다:
Inference 탭에서 Compare 뷰 열기
- 왼쪽 사이드바에서 Inference를 선택합니다. 사용 가능한 모델과 모델 정보가 표시된 페이지가 열립니다.
- 비교할 모델을 선택하려면 모델 이름을 제외한 모델 카드의 아무 곳이나 클릭합니다. 선택된 모델 카드는 파란색 테두리로 강조 표시됩니다.
- 비교하려는 각 모델에 대해 2단계를 반복합니다.
- 선택된 카드 중 하나에서 Compare N models in the Playground 버튼을 클릭합니다 (
N은 비교 중인 모델 수입니다. 예를 들어 3개의 모델이 선택된 경우 버튼에는 Compare 3 models in the Playground로 표시됩니다). 비교 뷰가 열립니다.
이제 Playground에서 모델을 비교하고, Try a model in the Playground에 설명된 모든 기능을 사용할 수 있습니다.
Playground 탭에서 비교 보기(Compare view)에 접근하기
- 왼쪽 사이드바에서 Playground를 선택합니다. Playground 채팅 UI가 표시됩니다.
- LLM 드롭다운 목록에서 W&B Inference에 마우스를 올립니다. 오른쪽에 사용 가능한 W&B Inference 모델이 포함된 드롭다운이 표시됩니다.
- 드롭다운에서 Compare를 선택합니다. Inference 탭이 표시됩니다.
- 비교할 모델을 선택하려면 (모델 이름을 제외한) 모델 카드의 아무 곳이나 클릭합니다. 선택되었음을 나타내기 위해 모델 카드의 테두리가 파란색으로 강조 표시됩니다.
- 비교하려는 각 모델에 대해 4단계를 반복합니다.
- 선택된 카드 중 하나에서 Compare N models in the Playground 버튼을 클릭합니다 (
N은 비교할 모델 수입니다. 예를 들어 3개의 모델을 선택하면 버튼은 Compare 3 models in the Playground로 표시됩니다). 비교 보기가 열립니다.
이제 Playground에서 모델을 비교하고, Playground에서 모델 사용해 보기에 설명된 기능을 모두 사용할 수 있습니다.
조직 관리자는 W&B UI에서 현재 Inference 크레딧 잔액, 사용 내역, 그리고 (해당되는 경우) 예정된 청구 정보를 직접 확인할 수 있습니다.
- W&B UI에서 W&B Billing 페이지로 이동합니다.
- 오른쪽 하단에 Inference 결제 정보 카드가 표시됩니다. 여기에서 다음 작업을 수행할 수 있습니다.
- Inference 결제 정보 카드에서 View usage 버튼을 클릭해 시간 경과에 따른 사용량을 확인합니다.
- 유료 요금제를 사용하는 경우, 예정된 Inference 청구 금액을 확인합니다.
다음 섹션에서는 중요한 사용 정보와 제한 사항을 설명합니다. 서비스를 사용하기 전에 이 내용을 반드시 숙지하세요.
Inference 서비스는 지원되는 지역에서만 이용할 수 있습니다. 자세한 내용은 이용 약관을 참조하세요.
공정한 사용과 안정적인 성능을 보장하기 위해 W&B Inference API는 사용자 및 프로젝트 수준에서 동시 처리 한도를 적용합니다. 이러한 한도는 다음을 돕습니다:
- 오남용을 방지하고 API 안정성을 보호
- 모든 사용자가 안정적으로 이용할 수 있도록 보장
- 인프라 부하를 효과적으로 관리
동시 처리 한도를 초과하면 API는 429 Concurrency limit reached for requests 응답을 반환합니다. 이 오류를 해결하려면 동시에 보내는 요청 수를 줄이십시오.
모델 가격 정보는 https://wandb.ai/site/pricing/inference에서 확인하세요.
| Error Code | Message | Cause | Solution |
|---|
| 401 | 잘못된 인증 | 잘못된 인증 자격 증명이거나 W&B 프로젝트 엔터티 및/또는 이름이 올바르지 않습니다. | 올바른 API key를 사용하고 있는지, W&B 프로젝트 이름과 엔터티가 정확한지 확인하세요. |
| 403 | 지원되지 않는 국가, 지역 또는 관할 구역입니다 | 지원되지 않는 위치에서 API에 접근했습니다. | 지리적 제한 사항을 참조하세요. |
| 429 | 요청에 대한 동시 처리 한도에 도달했습니다 | 동시 요청 수가 너무 많습니다. | 동시 요청 수를 줄이세요. |
| 429 | 현재 할당량을 초과했습니다. 요금제와 결제 세부 정보를 확인하세요 | 크레딧이 부족하거나 월간 지출 한도에 도달했습니다. | 더 많은 크레딧을 구매하거나 한도를 늘리세요. |
| 500 | 요청을 처리하는 동안 서버에서 오류가 발생했습니다 | 내부 서버 오류입니다. | 잠시 후 다시 시도하고, 문제가 지속되면 지원팀에 문의하세요. |
| 503 | 엔진이 현재 과부하 상태입니다. 나중에 다시 시도해주세요 | 서버에 높은 트래픽이 발생하고 있습니다. | 잠시 후 요청을 다시 시도하세요. |