Use this file to discover all available pages before exploring further.
Colab에서 실행해 보기PyTorch Lightning은 PyTorch 코드를 체계적으로 구성하고, 분산 학습이나 16비트 정밀도와 같은 고급 기능을 쉽게 추가할 수 있도록 하는 경량 래퍼를 제공합니다. W&B는 ML 실험을 기록하기 위한 경량 래퍼를 제공합니다. 하지만 이 둘을 직접 결합할 필요는 없습니다. W&B는 WandbLogger를 통해 PyTorch Lightning 라이브러리에 직접 통합되어 있습니다.
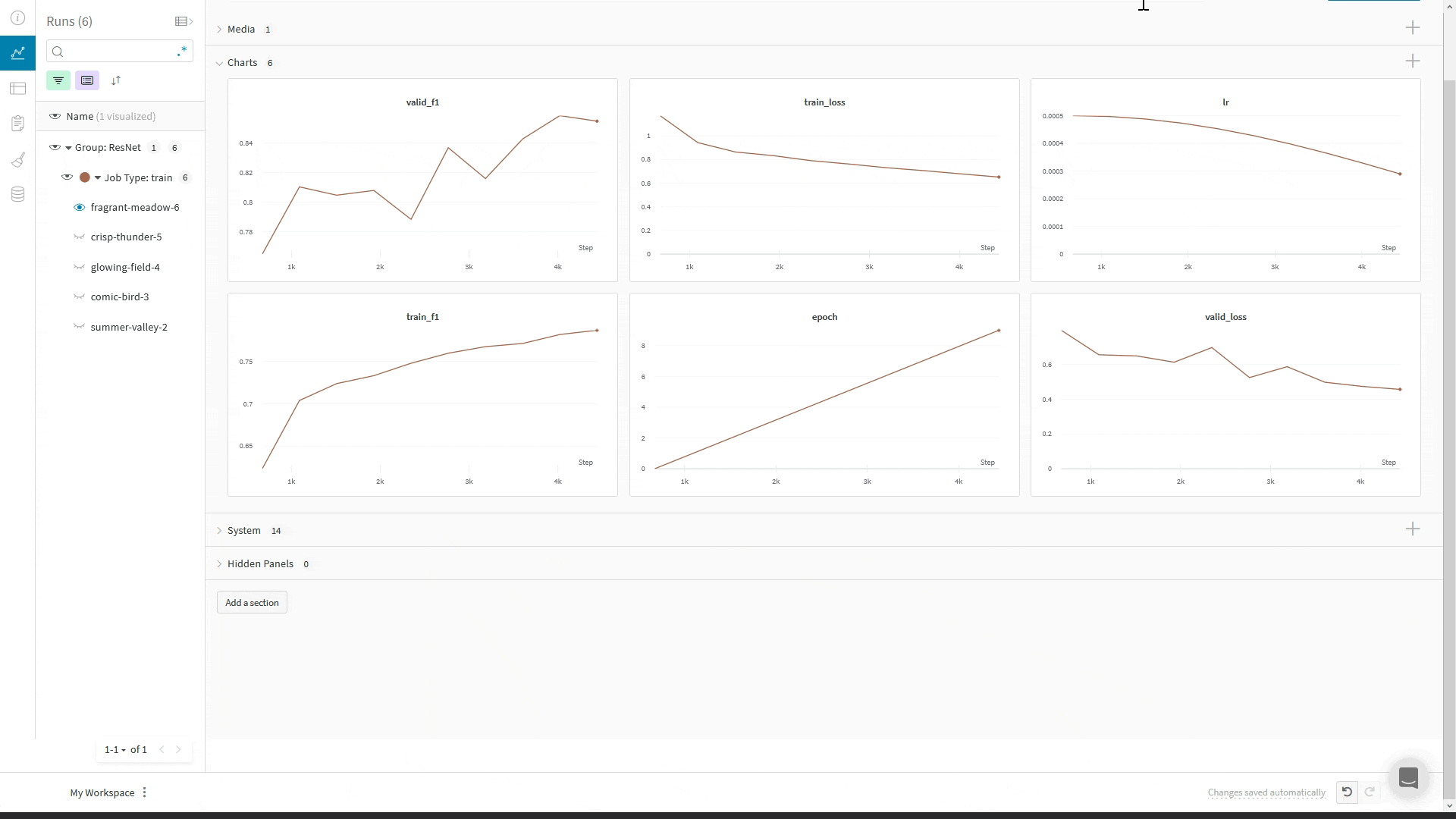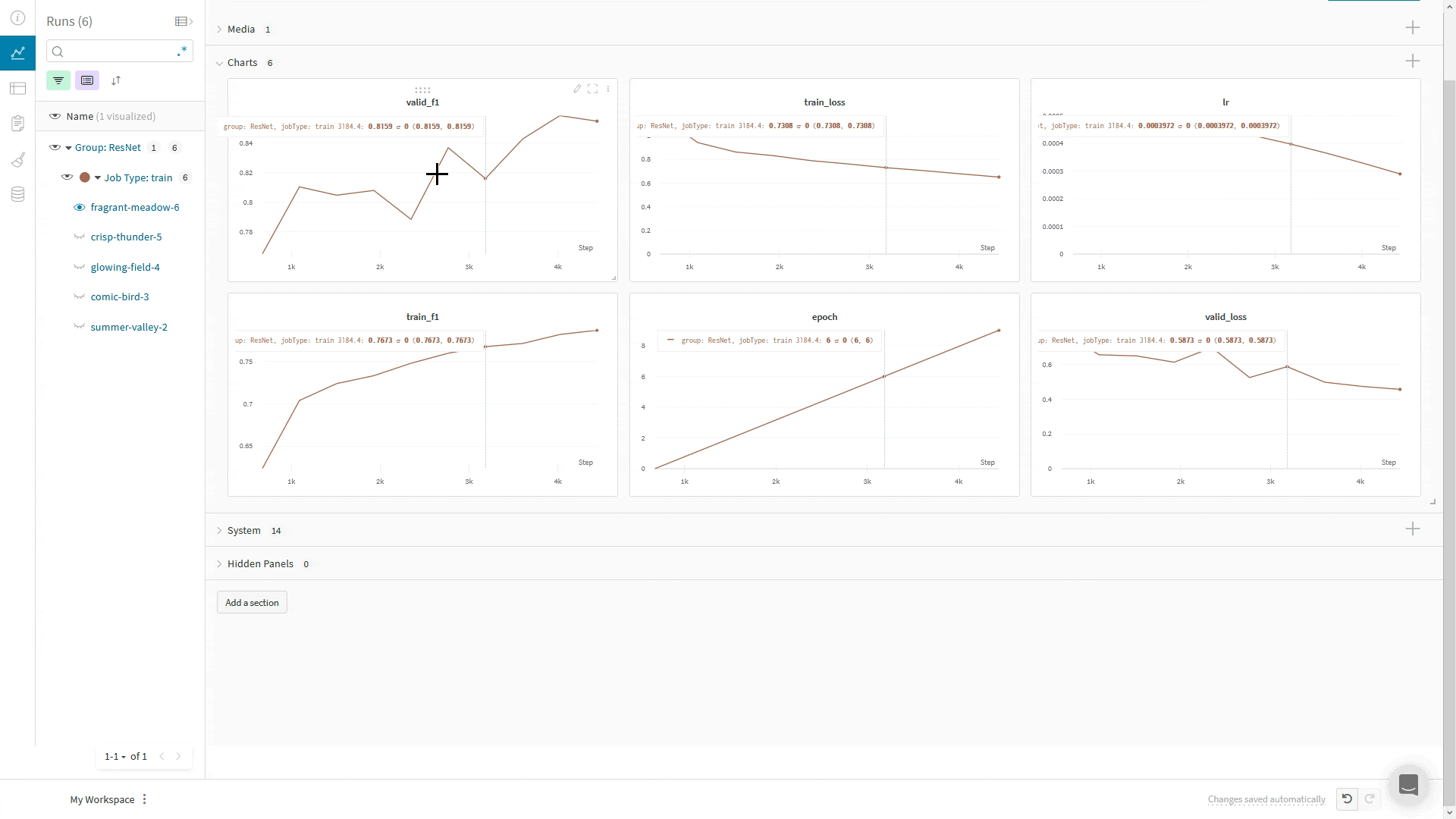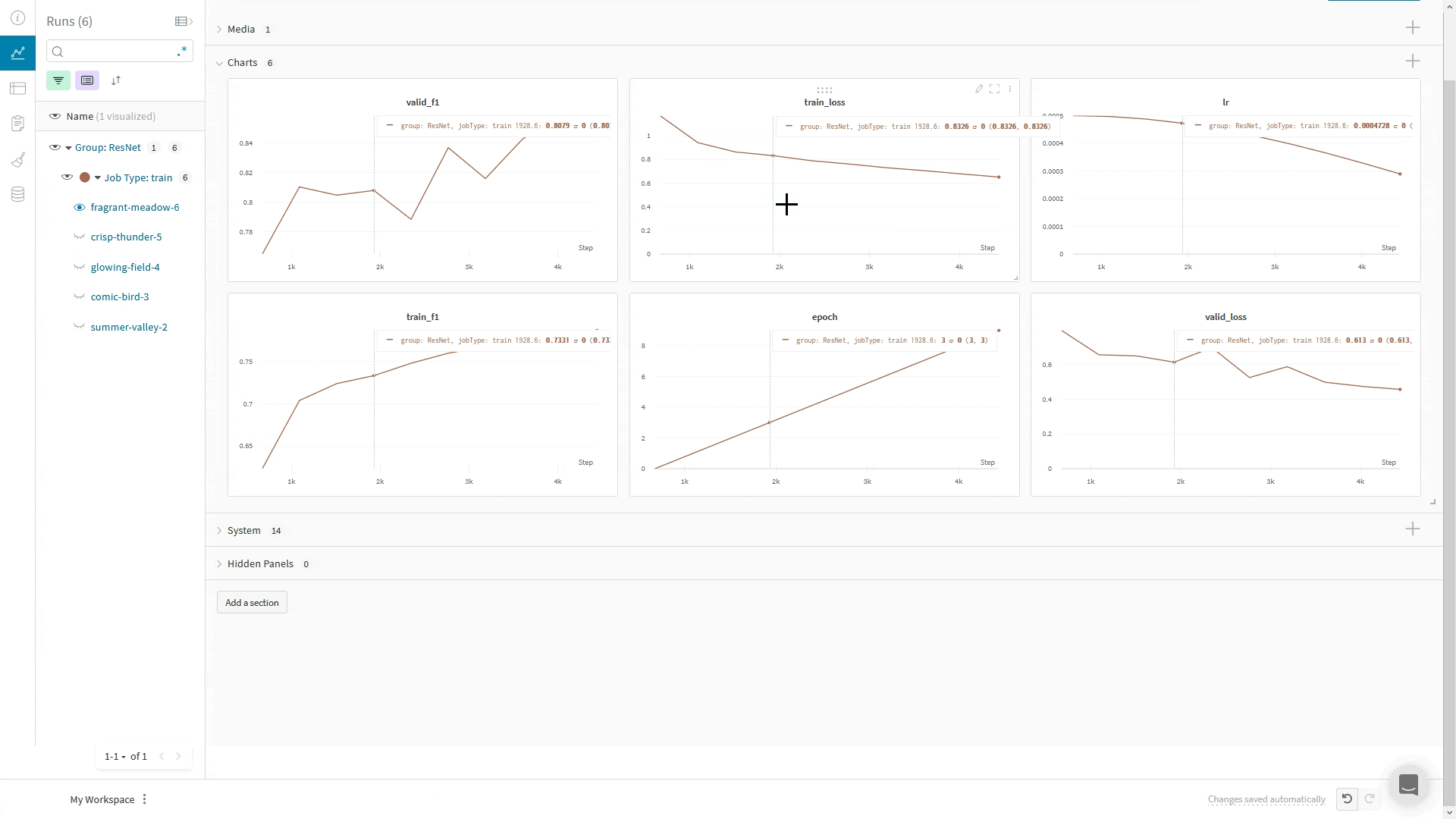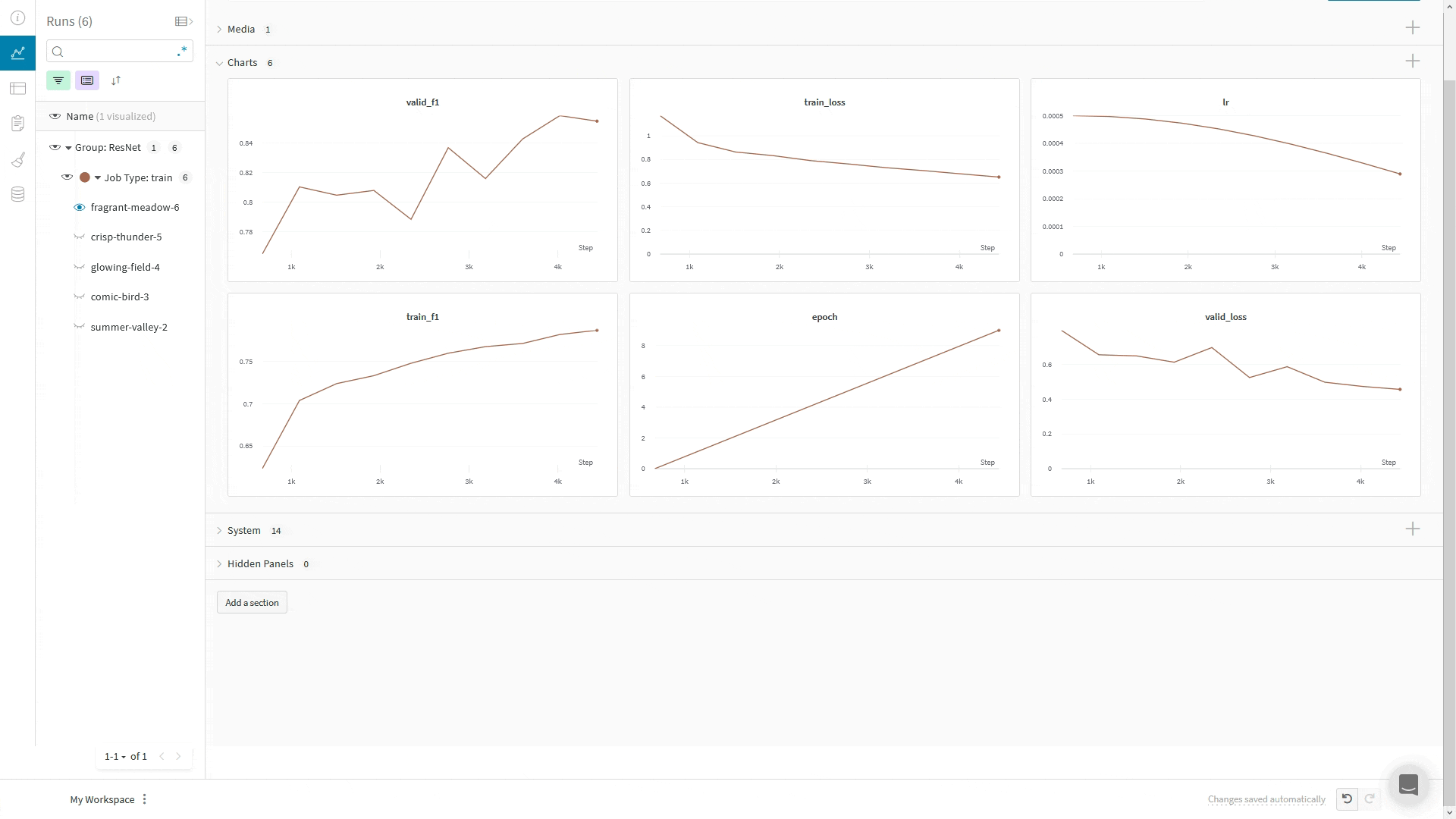
wandb.log() 사용:WandbLogger는 Trainer의 global_step을 사용해 W&B에 로그를 기록합니다. 코드에서 추가로 wandb.log를 직접 호출하는 경우, wandb.log()에서 step 인자를 사용하지 마십시오.대신, 다른 지표와 마찬가지로 Trainer의 global_step을 함께 기록하십시오:
LightningModule 안에서, 예를 들어 training_step 또는 validation_step 메서드에서 self.log('my_metric_name', metric_vale)를 호출하여 WandbLogger를 사용할 때 메트릭을 W&B에 로깅할 수 있습니다.아래 코드 스니펫은 메트릭과 LightningModule 하이퍼파라미터를 로깅할 수 있도록 LightningModule을 정의하는 방법을 보여줍니다. 이 예제에서는 메트릭을 계산하기 위해 torchmetrics 라이브러리를 사용합니다.
wandb의 define_metric 함수를 사용하면 W&B Summary 메트릭에 해당 메트릭의 최소값, 최대값, 평균값 또는 최적값 중 어떤 값을 표시할지 정의할 수 있습니다. define_metric _ 을 사용하지 않으면 마지막으로 로깅된 값이 Summary 메트릭에 표시됩니다. 자세한 내용은 define_metric레퍼런스 문서와 가이드를 참고하세요.W&B Summary 메트릭에서 검증 정확도(val_accuracy)의 최대값을 추적하려면, 학습 시작 시점에 단 한 번만 wandb.define_metric을 호출하세요:
로그한 모델 체크포인트는 W&B 아티팩트 UI에서 확인할 수 있으며, 전체 모델 계보 정보가 포함됩니다 (UI에서 모델 체크포인트 예시는 여기에서 볼 수 있습니다).최고의 모델 체크포인트를 북마크하고 팀 전체에서 한 곳에 모아 관리하려면, 이를 W&B Model Registry에 연결하면 됩니다.여기에서 작업별로 최상의 모델을 구성하고, 모델 수명주기를 관리하며, ML 수명주기 전반에 걸친 손쉬운 추적과 감사를 지원하고, 웹훅 또는 잡을 사용해 하위 단계 작업을 자동화할 수 있습니다.
WandbLogger에는 미디어를 로깅하기 위한 log_image, log_text, log_table 메서드가 있습니다.wandb.log 또는 trainer.logger.experiment.log를 직접 호출해서 오디오, 분자 구조(Molecules), 포인트 클라우드(Point Clouds), 3D 객체(3D Objects) 등의 다른 미디어 유형도 로깅할 수 있습니다.
이미지 로깅(Log Images)
텍스트 로깅(Log Text)
테이블 로깅(Log Tables)
# tensors, numpy 배열 또는 PIL 이미지를 사용wandb_logger.log_image(key="samples", images=[img1, img2])# 캡션 추가wandb_logger.log_image(key="samples", images=[img1, img2], caption=["tree", "person"])# 파일 경로 사용wandb_logger.log_image(key="samples", images=["img_1.jpg", "img_2.jpg"])# trainer에서 .log 사용trainer.logger.experiment.log( {"samples": [wandb.Image(img, caption=caption) for (img, caption) in my_images]}, step=current_trainer_global_step,)
PyTorch Lightning은 DDP 인터페이스를 통해 멀티 GPU를 지원합니다. 하지만 PyTorch Lightning의 설계 특성상 GPU를 초기화하는 방식에 주의를 기울여야 합니다.Lightning은 학습 루프에서 각 GPU(또는 rank)가 정확히 동일한 방식, 즉 동일한 초기 조건으로 초기화된다고 가정합니다. 그러나 rank 0 프로세스만 wandb.run 객체에 접근할 수 있고, 0이 아닌 rank 프로세스에서는 wandb.run = None입니다. 이로 인해 rank가 0이 아닌 프로세스가 실패할 수 있습니다. 이런 상황에서는 rank 0 프로세스가 이미 크래시된 rank 0이 아닌 프로세스가 조인하기를 계속 기다리게 되어 **데드락(교착 상태)**에 빠질 수 있습니다.이러한 이유로, 학습 코드를 설정하는 방식에 특히 주의해야 합니다. 권장되는 방법은 코드가 wandb.run 객체에 의존하지 않도록 구성하는 것입니다.
class MNISTClassifier(pl.LightningModule): def __init__(self): super(MNISTClassifier, self).__init__() self.model = nn.Sequential( nn.Flatten(), nn.Linear(28 * 28, 128), nn.ReLU(), nn.Linear(128, 10), ) self.loss = nn.CrossEntropyLoss() def forward(self, x): return self.model(x) def training_step(self, batch, batch_idx): x, y = batch y_hat = self.forward(x) loss = self.loss(y_hat, y) self.log("train/loss", loss) return {"train_loss": loss} def validation_step(self, batch, batch_idx): x, y = batch y_hat = self.forward(x) loss = self.loss(y_hat, y) self.log("val/loss", loss) return {"val_loss": loss} def configure_optimizers(self): return torch.optim.Adam(self.parameters(), lr=0.001)def main(): # 모든 랜덤 시드를 동일한 값으로 설정합니다. # 분산 학습 환경에서 중요한 설정입니다. # 각 rank는 고유한 초기 가중치를 갖게 됩니다. # 초기 가중치가 일치하지 않으면 그래디언트도 일치하지 않아 # 학습이 수렴하지 않을 수 있습니다. pl.seed_everything(1) train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True, num_workers=4) val_loader = DataLoader(val_dataset, batch_size=64, shuffle=False, num_workers=4) model = MNISTClassifier() wandb_logger = WandbLogger(project="<project_name>") callbacks = [ ModelCheckpoint( dirpath="checkpoints", every_n_train_steps=100, ), ] trainer = pl.Trainer( max_epochs=3, gpus=2, logger=wandb_logger, strategy="ddp", callbacks=callbacks ) trainer.fit(model, train_loader, val_loader)
모델 체크포인트를 W&B에 저장하므로, 이후 실행에서 사용할 수 있도록 확인하거나 다운로드할 수 있습니다. 또한 GPU 사용량과 네트워크 I/O 같은 system metrics, 하드웨어 및 OS 정보와 같은 환경 정보, git 커밋과 diff 패치, 노트북 내용 및 세션 이력을 포함한 code state, 그리고 표준 출력(stdout)에 출력되는 모든 내용을 수집합니다.