Colab에서 실행해 보기 이 튜토리얼에서는 MONAI를 사용해 다중 레이블 3D 뇌종양 분할 작업을 위한 학습 워크플로를 구성하고, W&B의 실험 추적 및 데이터 시각화 기능을 사용하는 방법을 설명합니다. 이 튜토리얼에서는 다음과 같은 내용을 다룹니다:Documentation Index
Fetch the complete documentation index at: https://translations.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
- W&B 실행을 초기화하고, 재현성을 위해 해당 실행과 연관된 모든 설정(config)을 동기화합니다.
- MONAI transform API:
- 딕셔너리 형식 데이터용 MONAI transform.
- MONAI
transformsAPI에 따라 새 transform을 정의하는 방법. - 데이터 증강을 위해 강도를 무작위로 조정하는 방법.
- 데이터 로딩 및 시각화:
- 메타데이터가 포함된
Nifti이미지를 로드하고, 이미지 목록을 로드한 뒤 스택하는 방법. - 학습 및 검증을 가속화하기 위해 입출력(I/O)과 transform을 캐시하는 방법.
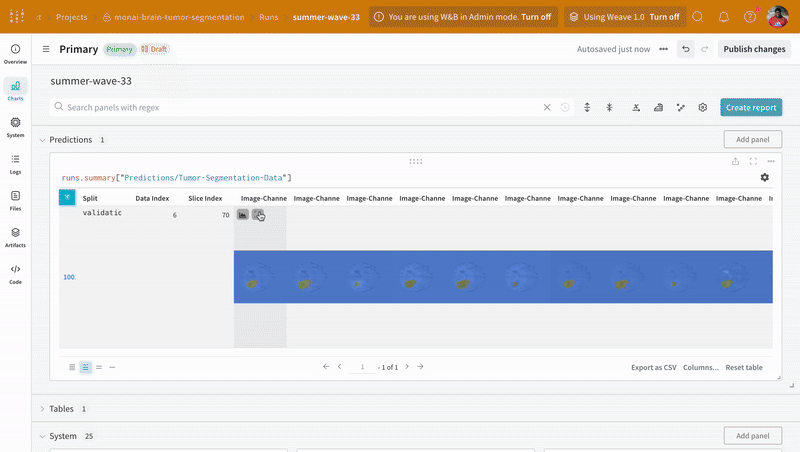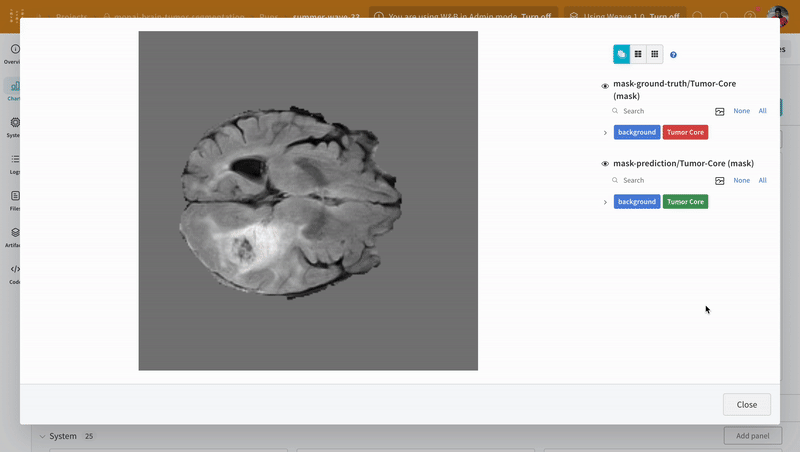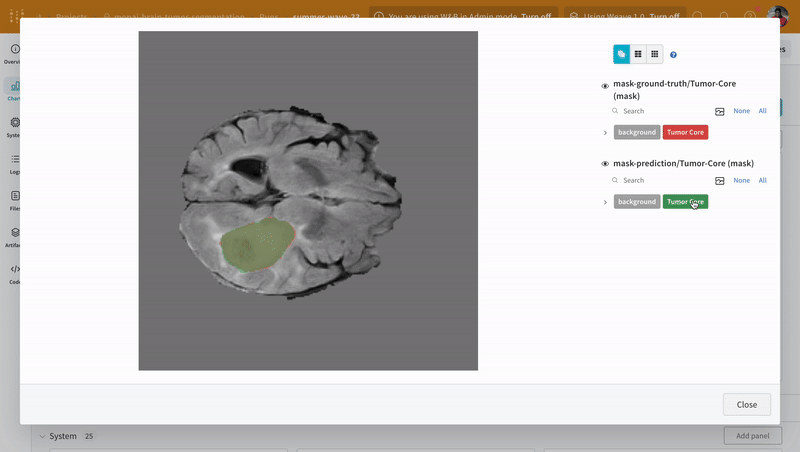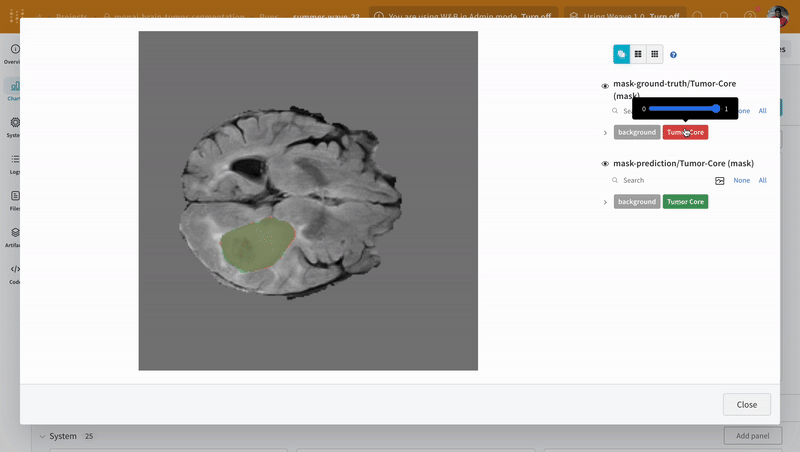
wandb.Table과 W&B의 대화형 세그멘테이션 오버레이를 사용하여 데이터를 시각화합니다.
- 메타데이터가 포함된
- 3D
SegResNet모델 학습- MONAI의
networks,losses,metricsAPI를 사용하는 방법. - PyTorch 학습 루프를 사용하여 3D
SegResNet모델을 학습하는 방법. - W&B를 사용하여 학습 실험을 추적합니다.
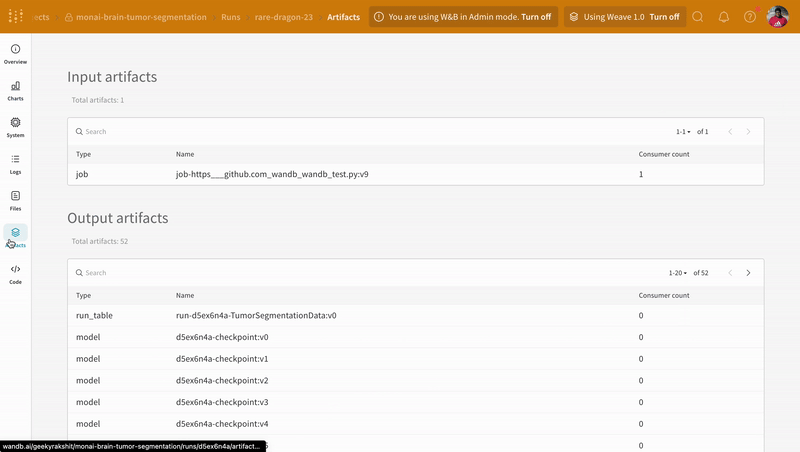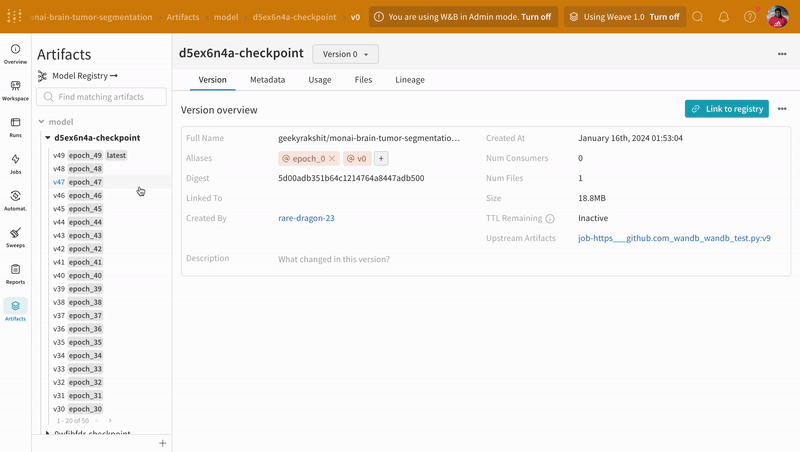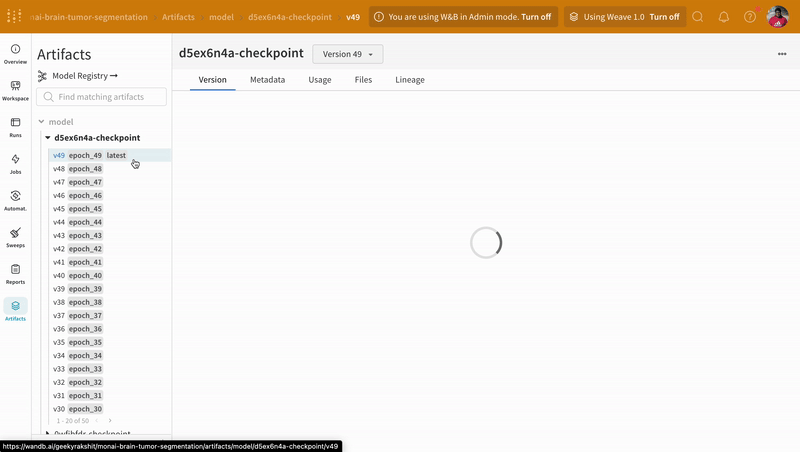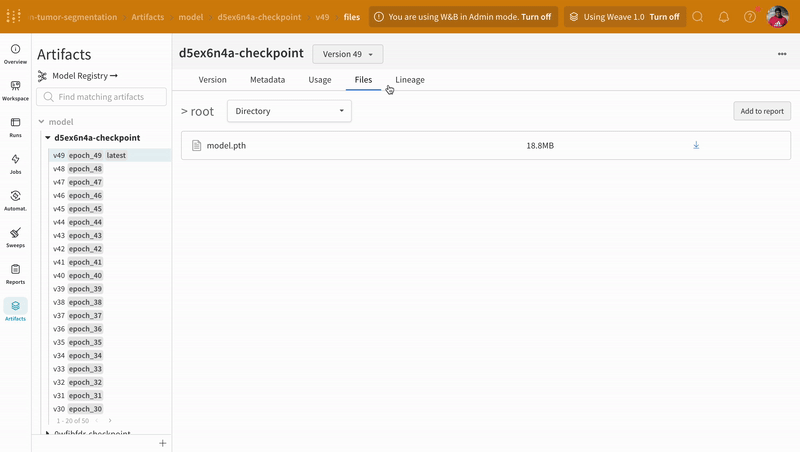
- 모델 체크포인트를 W&B에서 모델 아티팩트로 로깅하고 버전 관리합니다.
- MONAI의
wandb.Table과 W&B의 대화형 세그멘테이션 오버레이를 사용하여 검증 데이터셋에 대한 예측을 시각화하고 비교합니다.
설정 및 설치
W&B 실행 초기화
데이터 로딩 및 변환
monai.transforms API를 사용해 다중 클래스 레이블을 원-핫 형식의 멀티 라벨 세그멘테이션 태스크에 맞는 레이블로 변환하는 커스텀 변환을 생성합니다.
데이터셋
DecathlonDataset을 사용해 데이터셋을 자동으로 다운로드하고 압축을 해제하십시오. 이 클래스는 MONAI의 CacheDataset을 상속하며, 이를 통해 학습 시 cache_num=N으로 설정해 N개의 항목을 캐싱할 수 있고, 검증 시에는 기본 인수를 사용해 메모리 크기에 따라 모든 항목을 캐싱할 수 있습니다.
참고:
train_dataset에 train_transform을 적용하는 대신, 학습 및 검증 데이터셋 모두에 val_transform을 적용하세요. 이는 학습 전에 데이터셋의 두 분할(학습/검증) 모두에서 샘플을 시각화하기 때문입니다.데이터셋 시각화
wandb.Image 객체를 제공해야 합니다.
아래 의사코드 예제를 참고하십시오:
wandb.Table 객체와 관련 메타데이터를 입력으로 받아 W&B 대시보드에 로깅될 테이블의 행을 채우는 간단한 유틸리티 함수를 작성하세요.
wandb.Table 객체와 그 객체를 구성하는 열들을 정의합니다.
train_dataset과 val_dataset을 각각 순회하여 데이터 샘플에 대한 시각화를 생성하고, 대시보드에 로깅할 테이블의 각 행을 채웁니다.
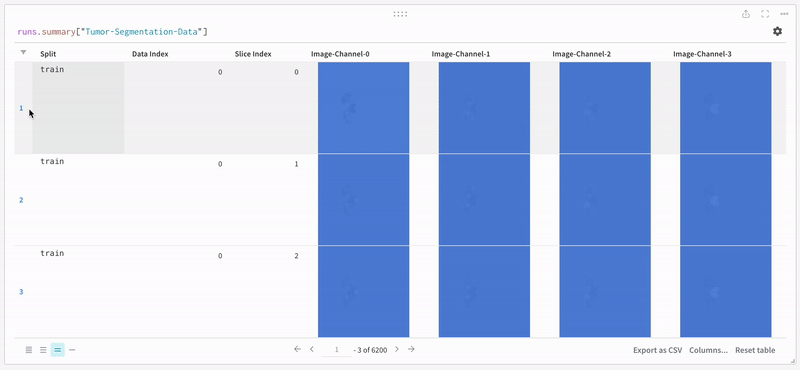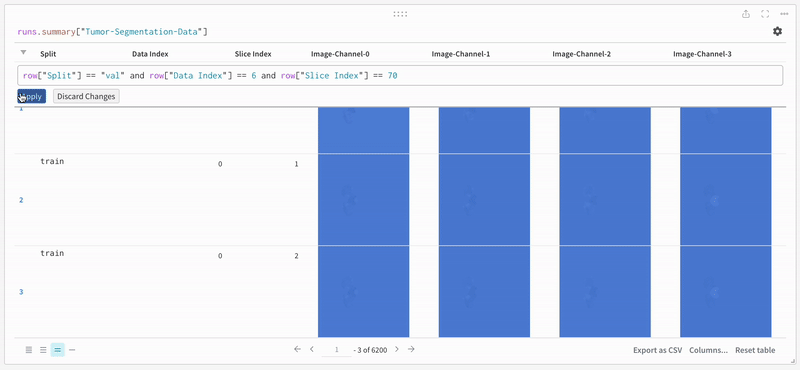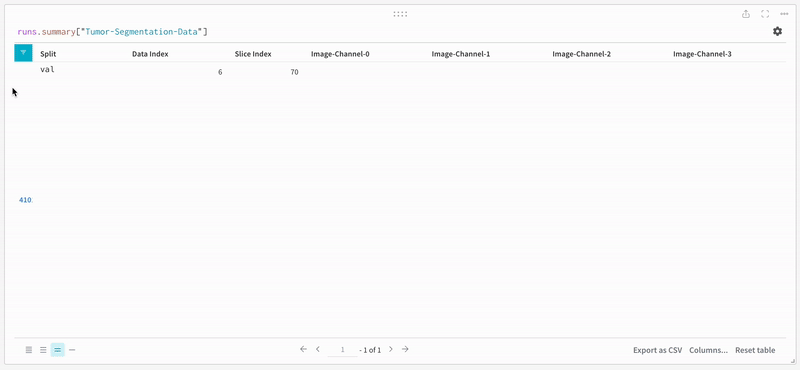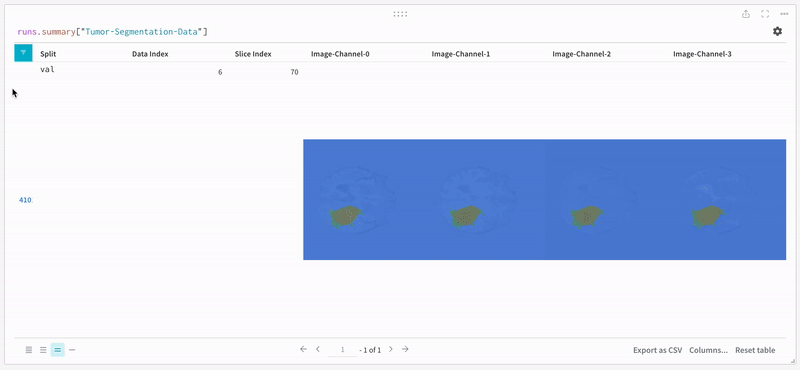
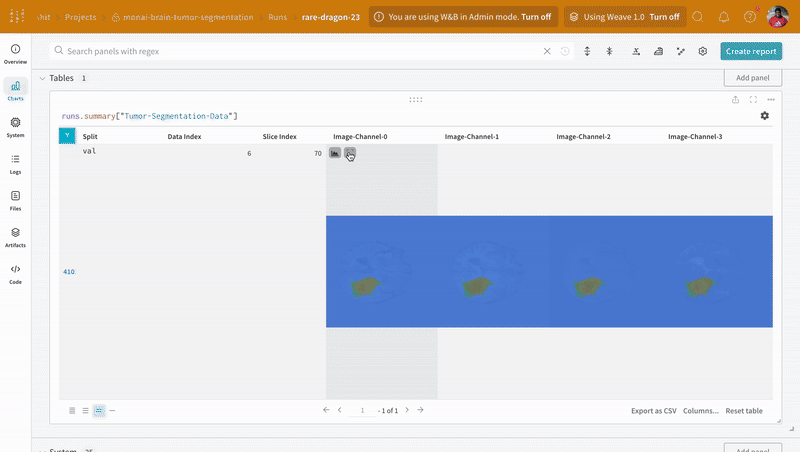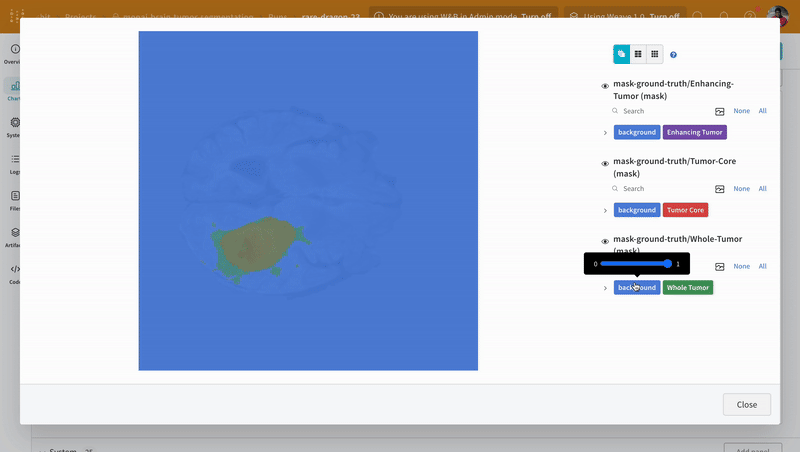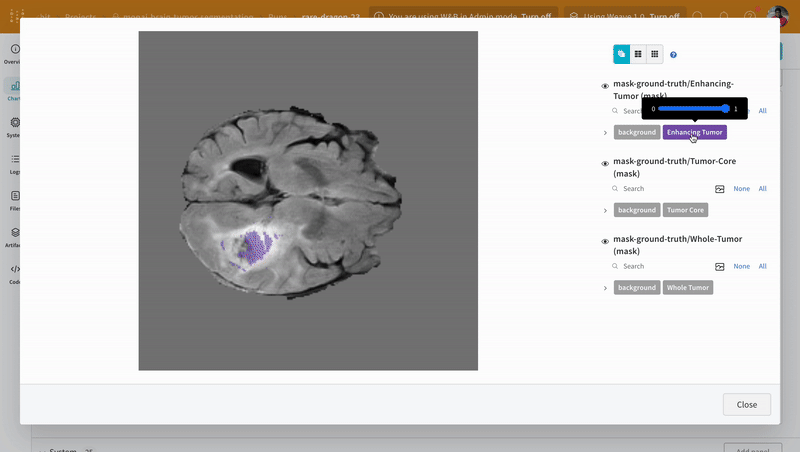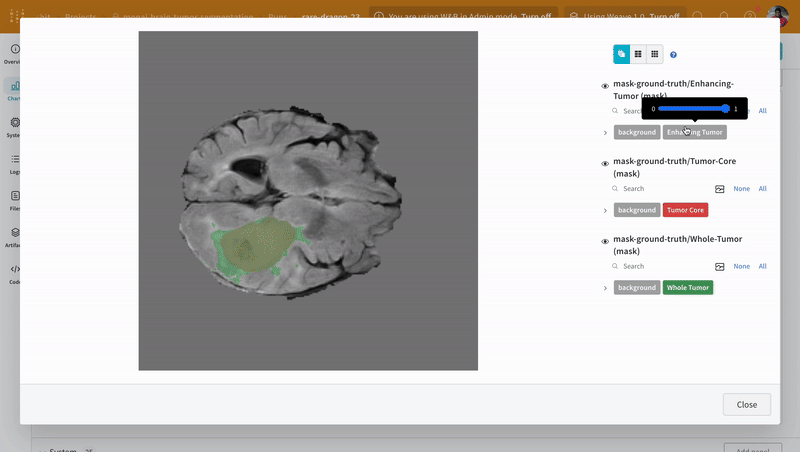
참고: 이 데이터셋의 레이블은 클래스 간에 서로 겹치지 않는 마스크로 구성됩니다. 오버레이는 레이블을 오버레이 내에서 개별 마스크로 로깅합니다.
데이터 불러오기
train_dataset의 transform을 train_transform으로 설정합니다.
모델, 손실 함수, 그리고 옵티마이저 생성
SegResNet 모델을 생성합니다. SegResNet 모델은 monai.networks API의 일부로 PyTorch 모듈 형태로 구현되어 있으며, 옵티마이저와 학습률 스케줄러도 함께 제공합니다.
monai.losses API를 사용해 손실 함수를 멀티레이블 DiceLoss로 정의하고, monai.metrics API를 사용해 이에 대응하는 Dice 지표를 정의합니다.
학습 및 검증
run.log()로 추적할 때 사용할 메트릭 속성을 정의합니다.
표준 PyTorch 학습 루프 실행
wandb.log으로 코드를 계측하면 학습 및 검증 과정과 관련된 모든 지표를 추적할 수 있을 뿐만 아니라, W&B 대시보드에서 시스템 지표(여기서는 CPU와 GPU)도 모두 기록할 수 있습니다.
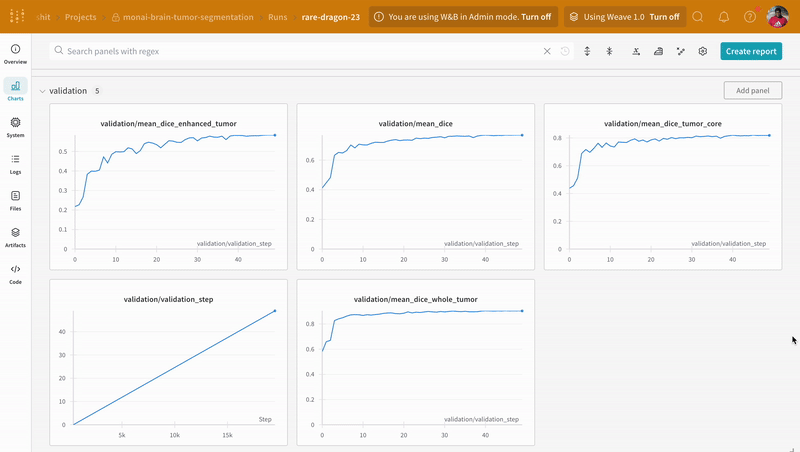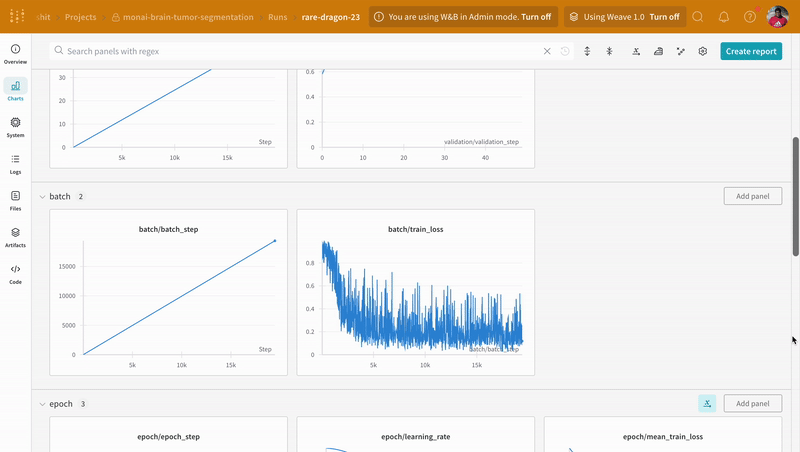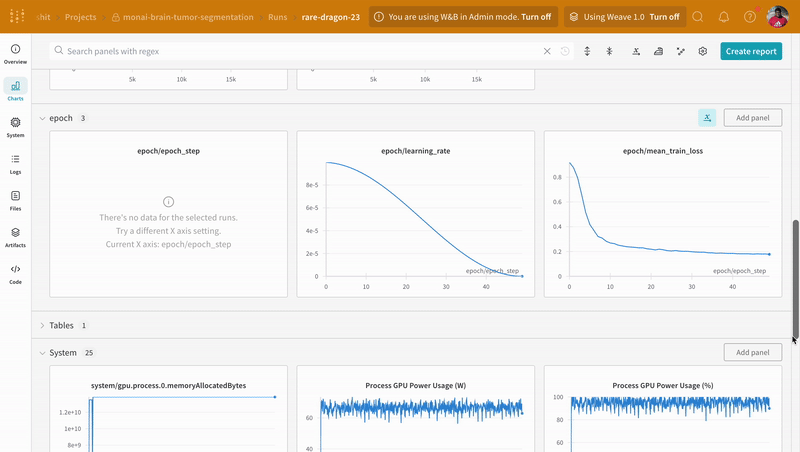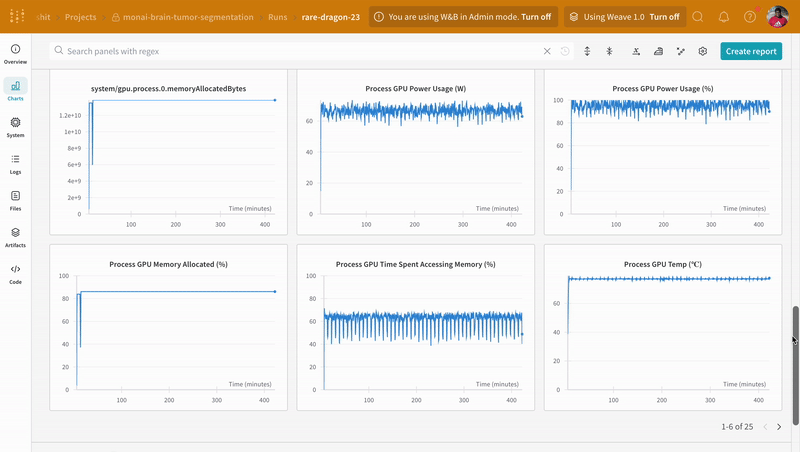
추론
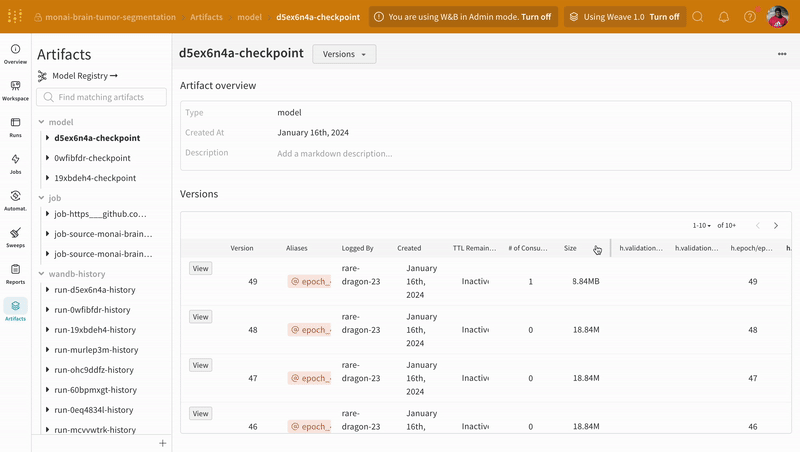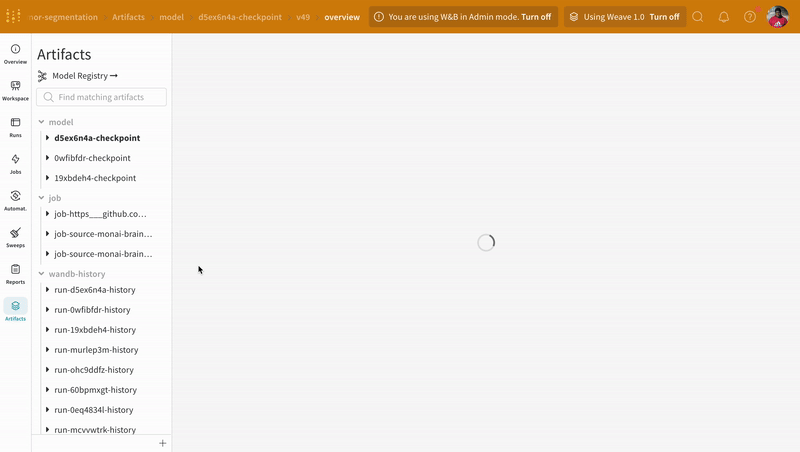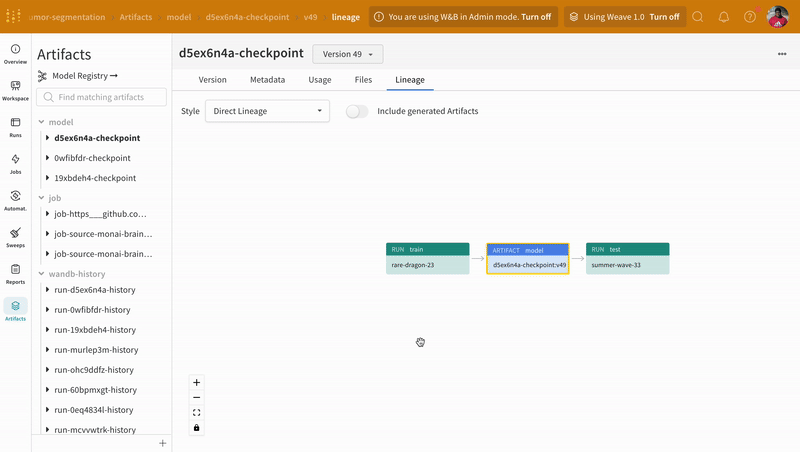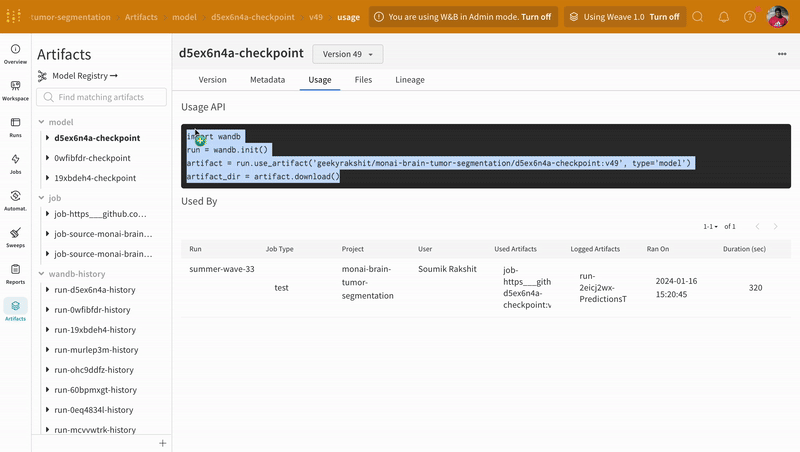
예측 시각화 및 정답 레이블과의 비교