Documentation Index
Fetch the complete documentation index at: https://translations.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
이 노트북은 대화형입니다. 로컬에서 실행하거나 아래 링크를 통해 열 수 있습니다:  Chain of Density(CoD)는 점진적으로 더 간결하고 정보 밀도가 높은 요약을 생성하는 반복적인 요약 기법입니다. 이 기법은 다음과 같이 동작합니다:
Chain of Density(CoD)는 점진적으로 더 간결하고 정보 밀도가 높은 요약을 생성하는 반복적인 요약 기법입니다. 이 기법은 다음과 같이 동작합니다:
- 초기 요약을 작성합니다
- 핵심 정보를 유지하면서 요약을 반복적으로 정제해 더 간결하게 만듭니다
- 각 반복마다 엔티티와 기술적 세부 정보의 밀도를 높입니다
이 방식은 세부 정보를 보존하는 것이 중요한 과학 논문이나 기술 문서를 요약할 때 특히 유용합니다.
이 튜토리얼에서는 Weave를 사용해 arXiv 논문에 대한 Chain of Density 요약 파이프라인을 구현하고 평가합니다. 이 과정을 통해 다음을 배우게 됩니다:
- LLM 파이프라인 추적: Weave를 사용해 요약 과정의 입력, 출력, 중간 단계를 자동으로 기록합니다.
- LLM 출력 평가: Weave의 내장 도구를 사용해 요약 결과를 엄밀하고 동일 조건에서 비교 가능하게 평가합니다.
- 조합 가능한 연산 구성: 요약 파이프라인의 여러 부분에서 Weave 연산을 결합해 재사용합니다.
- 원활한 통합: 최소한의 오버헤드로 기존 Python 코드에 Weave를 통합합니다.
이 튜토리얼을 마치면, 모델 서빙, 평가, 결과 추적에 Weave의 기능을 활용하는 CoD 요약 파이프라인을 구축하게 됩니다.
먼저 환경을 설정하고 필요한 라이브러리를 임포트합니다:
!pip install -qU anthropic weave pydantic requests PyPDF2 set-env-colab-kaggle-dotenv
Anthropic API key를 발급받으려면:
- https://www.anthropic.com 에서 계정을 생성합니다.
- 계정 설정의 API 섹션으로 이동합니다.
- 새 API key를 생성합니다.
- 생성한 API key를
.env 파일에 안전하게 저장합니다.
import io
import os
from datetime import datetime, timezone
import anthropic
import requests
from pydantic import BaseModel
from PyPDF2 import PdfReader
from set_env import set_env
import weave
set_env("WANDB_API_KEY")
set_env("ANTHROPIC_API_KEY")
weave.init("summarization-chain-of-density-cookbook")
anthropic_client = anthropic.Anthropic(api_key=os.getenv("ANTHROPIC_API_KEY"))
weave.init(<project name>) 호출은 요약 작업을 위한 새로운 Weave 프로젝트를 생성합니다.
데이터를 표현하기 위해 간단한 ArxivPaper 클래스를 생성하겠습니다:
# ArxivPaper 모델 정의
class ArxivPaper(BaseModel):
entry_id: str
updated: datetime
published: datetime
title: str
authors: list[str]
summary: str
pdf_url: str
# 샘플 ArxivPaper 생성
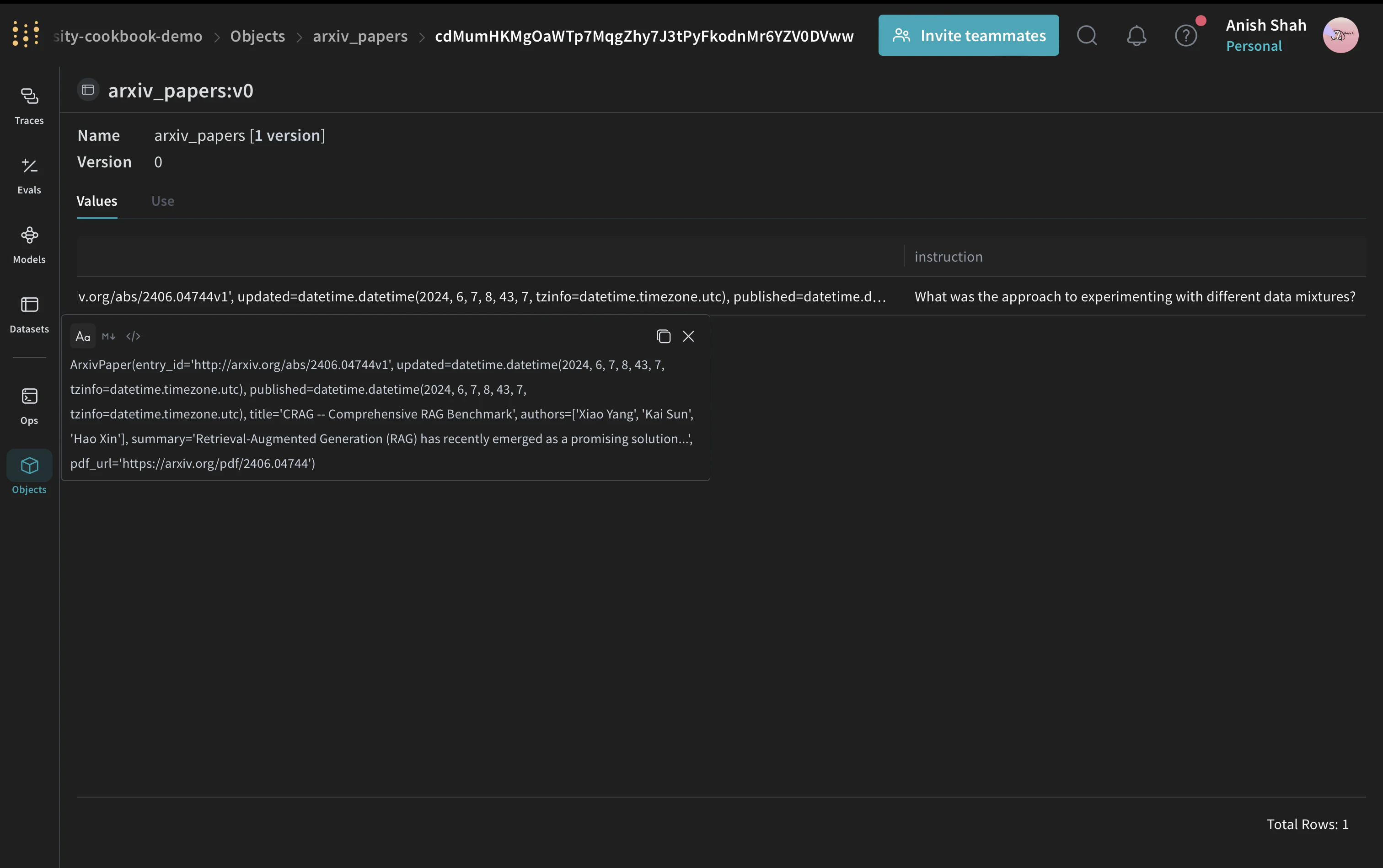
arxiv_paper = ArxivPaper(
entry_id="http://arxiv.org/abs/2406.04744v1",
updated=datetime(2024, 6, 7, 8, 43, 7, tzinfo=timezone.utc),
published=datetime(2024, 6, 7, 8, 43, 7, tzinfo=timezone.utc),
title="CRAG -- Comprehensive RAG Benchmark",
authors=["Xiao Yang", "Kai Sun", "Hao Xin"], # 간결성을 위해 생략
summary="Retrieval-Augmented Generation (RAG) has recently emerged as a promising solution...", # 생략
pdf_url="https://arxiv.org/pdf/2406.04744",
)
@weave.op()
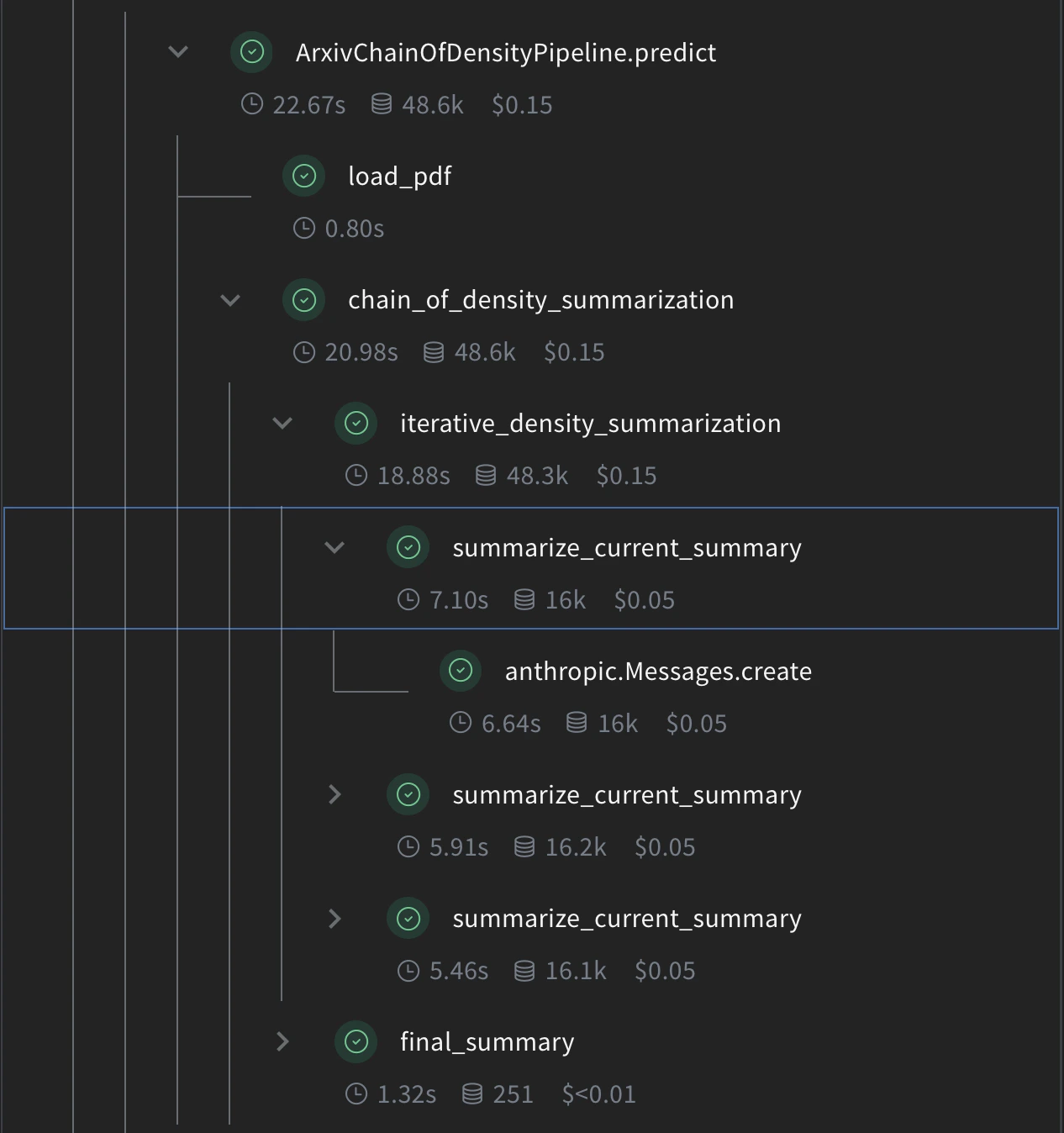
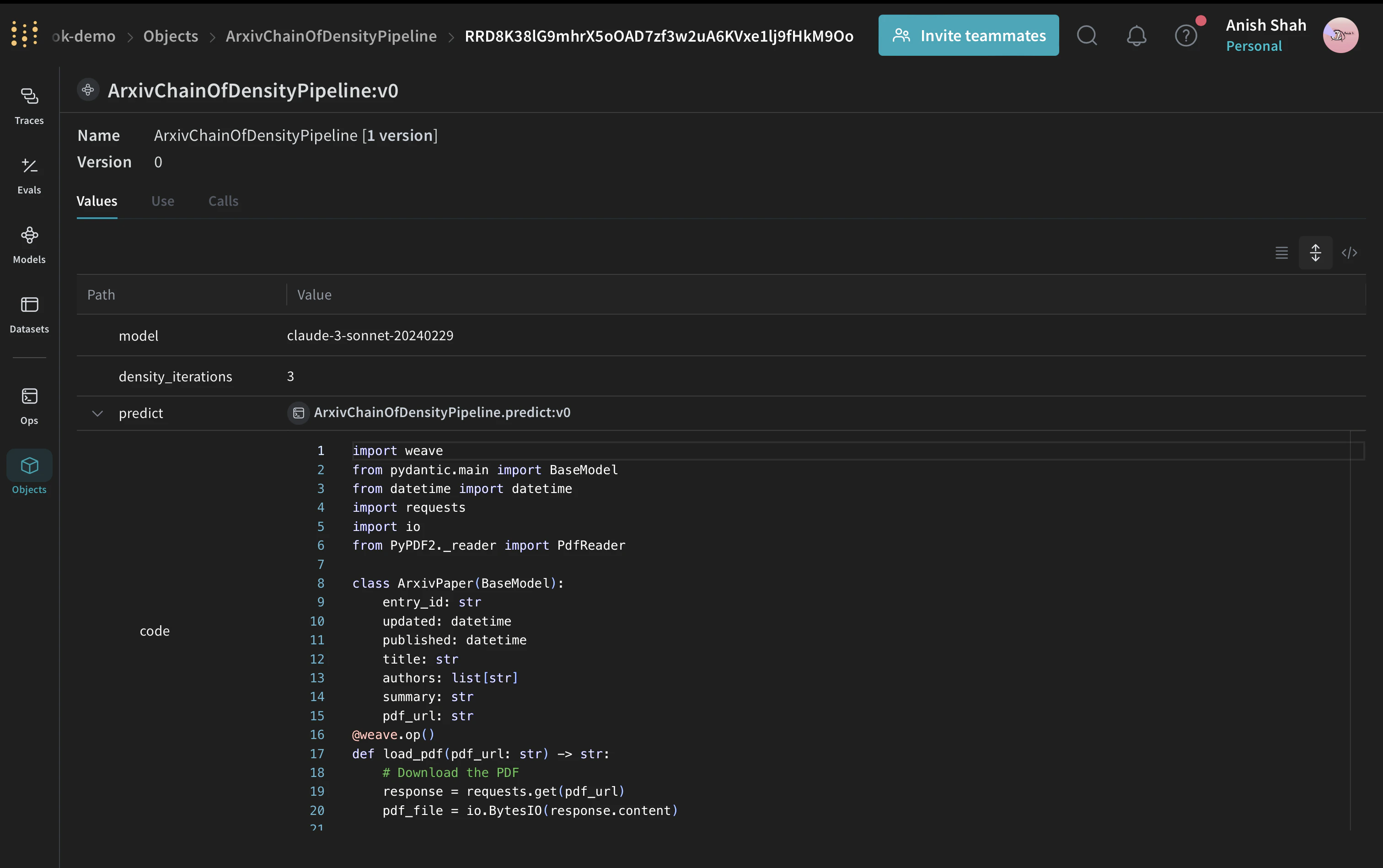
def load_pdf(pdf_url: str) -> str:
# PDF 다운로드
response = requests.get(pdf_url)
pdf_file = io.BytesIO(response.content)
# PDF 읽기
pdf_reader = PdfReader(pdf_file)
# 모든 페이지에서 텍스트 추출
text = ""
for page in pdf_reader.pages:
text += page.extract_text()
return text
# Chain of Density Summarization
@weave.op()
def summarize_current_summary(
document: str,
instruction: str,
current_summary: str = "",
iteration: int = 1,
model: str = "claude-3-sonnet-20240229",
):
prompt = f"""
Document: {document}
Current summary: {current_summary}
Instruction to focus on: {instruction}
Iteration: {iteration}
Generate an increasingly concise, entity-dense, and highly technical summary from the provided document that specifically addresses the given instruction.
"""
response = anthropic_client.messages.create(
model=model, max_tokens=4096, messages=[{"role": "user", "content": prompt}]
)
return response.content[0].text
@weave.op()
def iterative_density_summarization(
document: str,
instruction: str,
current_summary: str,
density_iterations: int,
model: str = "claude-3-sonnet-20240229",
):
iteration_summaries = []
for iteration in range(1, density_iterations + 1):
current_summary = summarize_current_summary(
document, instruction, current_summary, iteration, model
)
iteration_summaries.append(current_summary)
return current_summary, iteration_summaries
@weave.op()
def final_summary(
instruction: str, current_summary: str, model: str = "claude-3-sonnet-20240229"
):
prompt = f"""
Given this summary: {current_summary}
And this instruction to focus on: {instruction}
Create an extremely dense, final summary that captures all key technical information in the most concise form possible, while specifically addressing the given instruction.
"""
return (
anthropic_client.messages.create(
model=model, max_tokens=4096, messages=[{"role": "user", "content": prompt}]
)
.content[0]
.text
)
@weave.op()
def chain_of_density_summarization(
document: str,
instruction: str,
current_summary: str = "",
model: str = "claude-3-sonnet-20240229",
density_iterations: int = 2,
):
current_summary, iteration_summaries = iterative_density_summarization(
document, instruction, current_summary, density_iterations, model
)
final_summary_text = final_summary(instruction, current_summary, model)
return {
"final_summary": final_summary_text,
"accumulated_summary": current_summary,
"iteration_summaries": iteration_summaries,
}
summarize_current_summary: 현재 상태를 기반으로 한 번의 요약 단계를 생성합니다.iterative_density_summarization: summarize_current_summary를 여러 번 호출하여 CoD 기법을 적용합니다.chain_of_density_summarization: 전체 요약 프로세스를 총괄하고 결과를 반환합니다.
@weave.op() 데코레이터를 사용하면 Weave가 이 함수들의 입력, 출력, 실행을 추적할 수 있습니다.
이제 요약 파이프라인을 Weave 모델로 래핑해 보겠습니다:
# Weave Model
class ArxivChainOfDensityPipeline(weave.Model):
model: str = "claude-3-sonnet-20240229"
density_iterations: int = 3
@weave.op()
def predict(self, paper: ArxivPaper, instruction: str) -> dict:
text = load_pdf(paper.pdf_url)
result = chain_of_density_summarization(
text,
instruction,
model=self.model,
density_iterations=self.density_iterations,
)
return result
ArxivChainOfDensityPipeline 클래스는 요약 로직을 Weave Model로 캡슐화하며, 다음과 같은 주요 이점을 제공합니다:
- 자동 실험 추적: Weave는 모델의 각 실행에 대해 입력, 출력, 파라미터를 자동으로 기록합니다.
- 버전 관리: 모델의 속성이나 코드 변경 사항이 자동으로 버전 관리되어, 요약 파이프라인이 시간이 지남에 따라 어떻게 발전해 왔는지 명확한 이력을 제공합니다.
- 재현성: 버전 관리와 추적으로 인해 요약 파이프라인의 이전 결과나 설정을 손쉽게 재현할 수 있습니다.
- 하이퍼파라미터 관리:
model과 density_iterations 같은 모델 속성이 명확하게 정의되고 여러 실행 전반에 걸쳐 추적되므로, 다양한 실험을 수행하기가 수월합니다.
- Weave 생태계와의 통합:
weave.Model을 사용하면 평가 및 서빙 기능과 같은 다른 Weave 도구와 매끄럽게 통합할 수 있습니다.
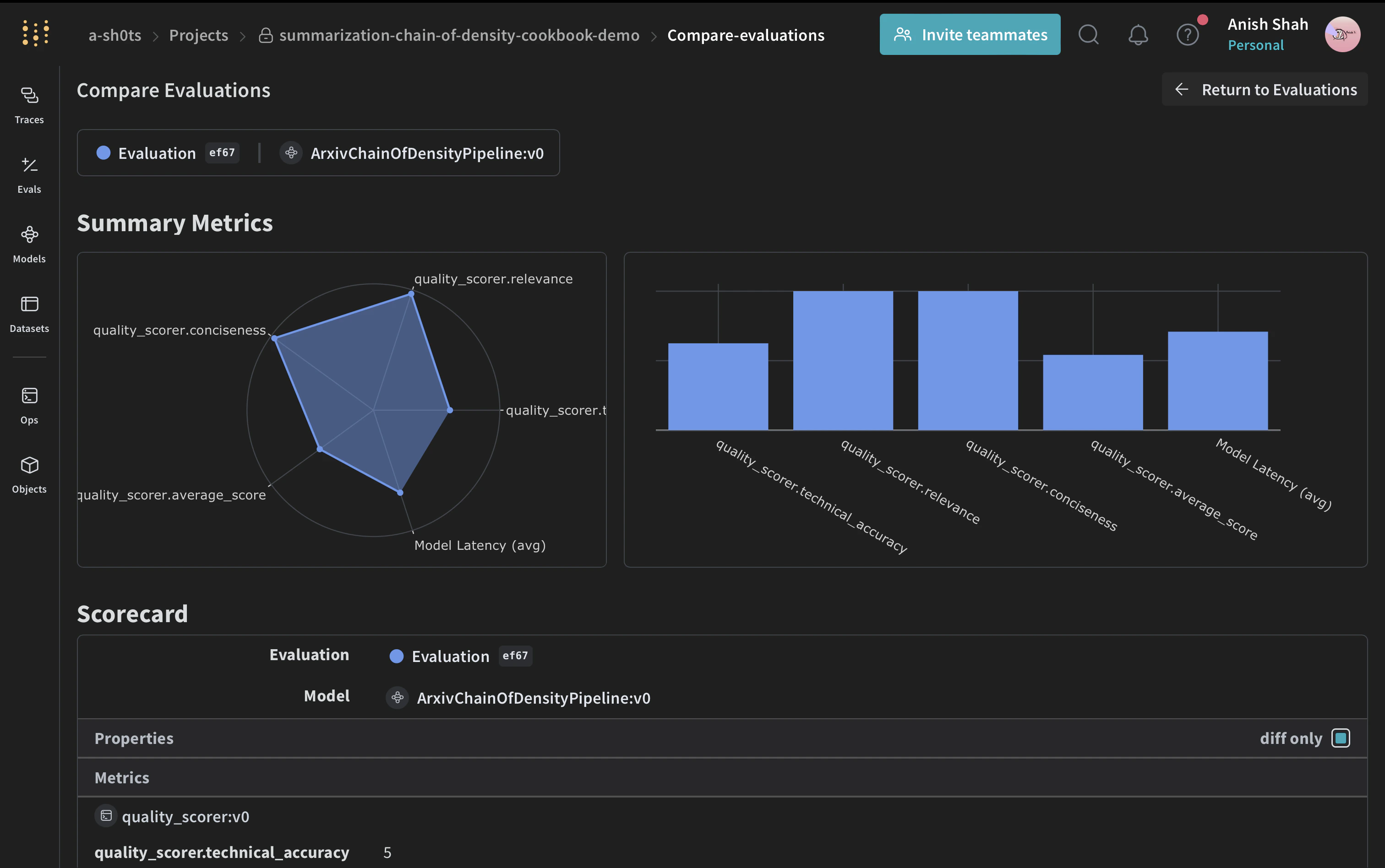
요약의 품질을 평가하기 위해 간단한 평가 지표를 구현해 보겠습니다:
import json
@weave.op()
def evaluate_summary(
summary: str, instruction: str, model: str = "claude-3-sonnet-20240229"
) -> dict:
prompt = f"""
Summary: {summary}
Instruction: {instruction}
Evaluate the summary based on the following criteria:
1. Relevance (1-5): How well does the summary address the given instruction?
2. Conciseness (1-5): How concise is the summary while retaining key information?
3. Technical Accuracy (1-5): How accurately does the summary convey technical details?
Your response MUST be in the following JSON format:
{{
"relevance": {{
"score": <int>,
"explanation": "<string>"
}},
"conciseness": {{
"score": <int>,
"explanation": "<string>"
}},
"technical_accuracy": {{
"score": <int>,
"explanation": "<string>"
}}
}}
Ensure that the scores are integers between 1 and 5, and that the explanations are concise.
"""
response = anthropic_client.messages.create(
model=model, max_tokens=1000, messages=[{"role": "user", "content": prompt}]
)
print(response.content[0].text)
eval_dict = json.loads(response.content[0].text)
return {
"relevance": eval_dict["relevance"]["score"],
"conciseness": eval_dict["conciseness"]["score"],
"technical_accuracy": eval_dict["technical_accuracy"]["score"],
"average_score": sum(eval_dict[k]["score"] for k in eval_dict) / 3,
"evaluation_text": response.content[0].text,
}
# Weave Dataset 생성
dataset = weave.Dataset(
name="arxiv_papers",
rows=[
{
"paper": arxiv_paper,
"instruction": "What was the approach to experimenting with different data mixtures?",
},
],
)
weave.publish(dataset)

# 스코어러 함수 정의
@weave.op()
def quality_scorer(instruction: str, output: dict) -> dict:
result = evaluate_summary(output["final_summary"], instruction)
return result
python
# 평가 실행
evaluation = weave.Evaluation(dataset=dataset, scorers=[quality_scorer])
arxiv_chain_of_density_pipeline = ArxivChainOfDensityPipeline()
results = await evaluation.evaluate(arxiv_chain_of_density_pipeline)
- 요약 과정의 각 단계에 대해 Weave op를 생성
- 파이프라인을 Weave Model로 래핑해 손쉽게 추적하고 평가할 수 있도록 구성
- Weave op를 사용해 사용자 정의 평가 지표를 구현
- 데이터셋을 생성하고 파이프라인에 대한 평가를 실행
Weave의 매끄러운 통합을 통해 요약 과정 전반에 걸쳐 입력, 출력, 중간 단계를 모두 추적할 수 있으므로 LLM 애플리케이션을 디버깅하고, 최적화하며, 평가하기가 더 쉬워집니다.
이 예제를 확장해 더 큰 데이터셋을 처리하거나, 더 정교한 평가 지표를 구현하거나, 다른 LLM 워크플로우와 통합할 수 있습니다.
W&B에서 전체 리포트 보기