Documentation Index
Fetch the complete documentation index at: https://translations.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
이 노트북은 인터랙티브 노트북입니다. 로컬에서 실행하거나 아래 링크를 사용해 실행할 수 있습니다: csv 또는 json 형식으로 제공되는 일이 흔합니다.
이 쿡북에서는 하위 수준 Weave Python API를 활용하여 CSV 파일에서 데이터를 추출하고, 이를 Weave로 가져와 인사이트를 도출하고 엄밀한 평가를 수행하는 방법을 살펴봅니다.
이 쿡북에서 사용하는 예제 데이터셋은 다음과 같은 구조를 갖습니다:
conversation_id,turn_index,start_time,user_input,ground_truth,answer_text
1234,1,2024-09-04 13:05:39,This is the beginning, ['This was the beginning'], That was the beginning
1235,1,2024-09-04 13:02:11,This is another trace,, That was another trace
1235,2,2024-09-04 13:04:19,This is the next turn,, That was the next turn
1236,1,2024-09-04 13:02:10,This is a 3 turn conversation,, Woah thats a lot of turns
1236,2,2024-09-04 13:02:30,This is the second turn, ['That was definitely the second turn'], You are correct
1236,3,2024-09-04 13:02:53,This is the end,, Well good riddance!
conversation_id를, 자식 식별자로는 turn_index를 사용합니다.
필요에 따라 변수를 수정하십시오.
필요한 모든 패키지를 설치하고 import합니다.
WANDB_API_KEY를 환경 변수에 설정해 두면 wandb.login()으로 쉽게 로그인할 수 있습니다(이 값은 Colab에 secret으로 제공해야 합니다).
Colab에 업로드할 파일 이름을 name_of_file에 설정하고, 로그를 기록할 W&B 프로젝트를 name_of_wandb_project에 설정합니다.
NOTE: 트레이스를 기록할 팀을 지정하려면 name_of_wandb_project를 {team_name}/{project_name} 형식으로 설정할 수도 있습니다.
그다음 weave.init()을 호출하여 Weave 클라이언트를 가져옵니다.
%pip install wandb weave pandas datetime --quiet
python
import os
import pandas as pd
import wandb
from google.colab import userdata
import weave
## Write samples file to disk
with open("/content/import_cookbook_data.csv", "w") as f:
f.write(
"conversation_id,turn_index,start_time,user_input,ground_truth,answer_text\n"
)
f.write(
'1234,1,2024-09-04 13:05:39,This is the beginning, ["This was the beginning"], That was the beginning\n'
)
f.write(
"1235,1,2024-09-04 13:02:11,This is another trace,, That was another trace\n"
)
f.write(
"1235,2,2024-09-04 13:04:19,This is the next turn,, That was the next turn\n"
)
f.write(
"1236,1,2024-09-04 13:02:10,This is a 3 turn conversation,, Woah thats a lot of turns\n"
)
f.write(
'1236,2,2024-09-04 13:02:30,This is the second turn, ["That was definitely the second turn"], You are correct\n'
)
f.write("1236,3,2024-09-04 13:02:53,This is the end,, Well good riddance!\n")
os.environ["WANDB_API_KEY"] = userdata.get("WANDB_API_KEY")
name_of_file = "/content/import_cookbook_data.csv"
name_of_wandb_project = "import-weave-traces-cookbook"
wandb.login()
python
weave_client = weave.init(name_of_wandb_project)
conversation_id와 turn_index 기준으로 정렬합니다.
이렇게 하면 conversation_data 열에 대화 턴이 배열 형태로 들어 있는, 두 개의 열을 가진 pandas 데이터프레임이 생성됩니다.
## 데이터 로드 및 형태 변환
df = pd.read_csv(name_of_file)
sorted_df = df.sort_values(["conversation_id", "turn_index"])
# 각 대화에 대한 딕셔너리 배열을 생성하는 함수
def create_conversation_dict_array(group):
return group.drop("conversation_id", axis=1).to_dict("records")
# conversation_id로 데이터프레임을 그룹화하고 집계 적용
result_df = (
sorted_df.groupby("conversation_id")
.apply(create_conversation_dict_array)
.reset_index()
)
result_df.columns = ["conversation_id", "conversation_data"]
# 집계 결과 확인
result_df.head()
- 각
conversation_id마다 상위 호출(parent call)을 생성합니다.
turn_index로 정렬된 턴 배열을 순회하면서 자식 호출(child call)을 생성합니다.
로우 레벨 Python API의 주요 개념:
- 하나의 Weave 호출은 하나의 Weave 트레이스와 동일하며, 이 호출에는 상위 호출이나 자식 호출이 연결될 수 있습니다.
- 하나의 Weave 호출에는 Feedback, Metadata 등 다른 정보도 연결될 수 있습니다. 여기서는 입력과 출력만 연결하지만, 데이터가 제공된다면 가져오기(import) 시에 이러한 정보도 추가할 수 있습니다.
- Weave 호출은 실시간 추적을 위한 것이므로
created와 finished 시점이 기록됩니다. 이번처럼 사후(import) 작업에서는 객체를 정의하고 서로 연결한 뒤에 한 번에 생성 및 완료로 처리합니다.
- 호출의
op 값은 Weave가 동일한 구조의 호출들을 분류하는 기준입니다. 이 예제에서는 모든 상위 호출이 Conversation 타입이고, 모든 자식 호출이 Turn 타입입니다. 필요에 따라 이 값을 변경할 수 있습니다.
- 호출은
inputs와 output을 가질 수 있습니다. inputs는 생성 시 정의하고, output은 호출이 완료될 때 정의합니다.
# Weave에 트레이스 기록
# 집계된 대화를 순회
for _, row in result_df.iterrows():
# 대화 부모를 정의,
# 이전에 정의한 weave_client로 "call"을 생성
parent_call = weave_client.create_call(
# Op 값은 이를 Weave op으로 등록하여 나중에 그룹으로 쉽게 조회할 수 있게 함
op="Conversation",
# 상위 레벨 대화의 입력을 그 아래의 모든 턴으로 설정
inputs={
"conversation_data": row["conversation_data"][:-1]
if len(row["conversation_data"]) > 1
else row["conversation_data"]
},
# Conversation 부모는 상위 부모가 없음
parent=None,
# 이 대화가 UI에 표시될 이름
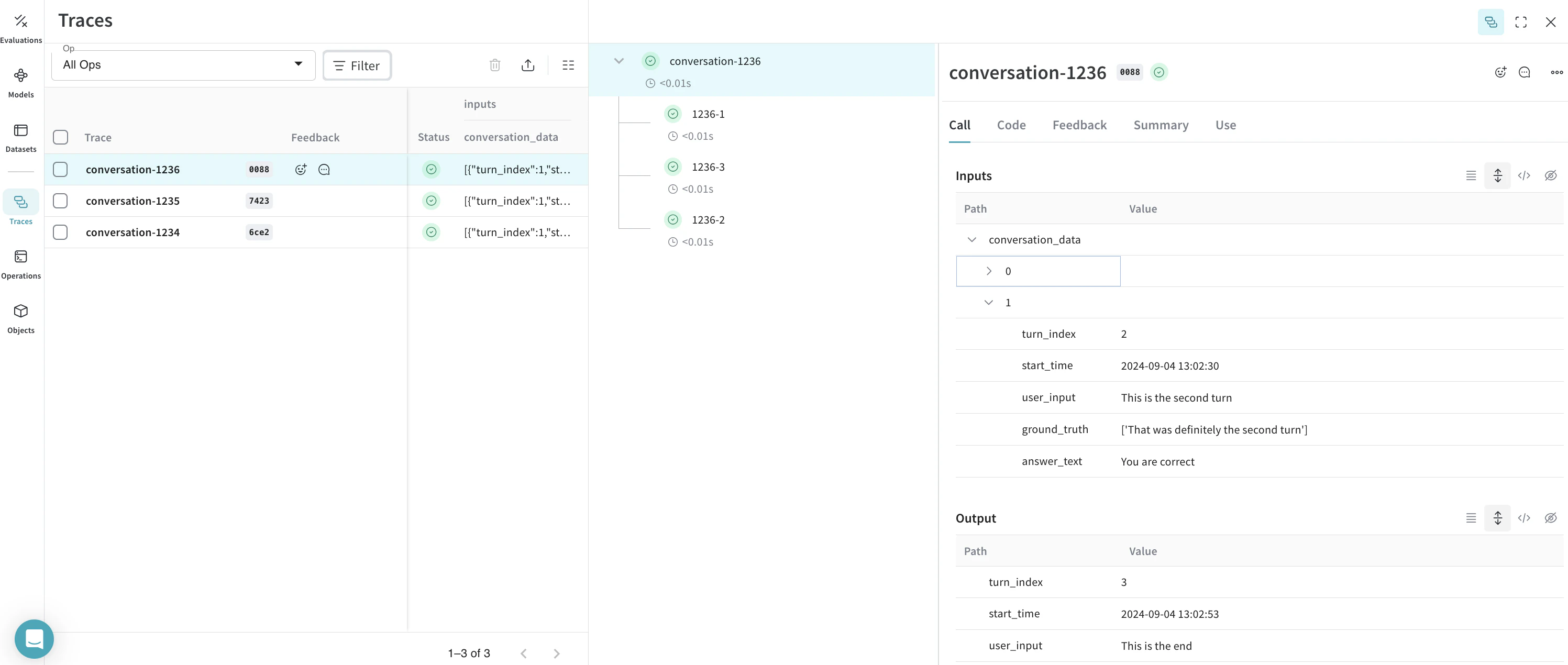
display_name=f"conversation-{row['conversation_id']}",
)
# 부모의 출력을 대화의 마지막 트레이스로 설정
parent_output = row["conversation_data"][len(row["conversation_data"]) - 1]
# 부모의 모든 대화 턴을 순회하며
# 대화의 자식 call로 기록
for item in row["conversation_data"]:
item_id = f"{row['conversation_id']}-{item['turn_index']}"
# 대화 하위로 분류되도록 여기서 다시 call을 생성
call = weave_client.create_call(
# 단일 대화 트레이스를 "Turn"으로 지정
op="Turn",
# RAG 'ground_truth'를 포함한 턴의 모든 입력을 제공
inputs={
"turn_index": item["turn_index"],
"start_time": item["start_time"],
"user_input": item["user_input"],
"ground_truth": item["ground_truth"],
},
# 정의한 부모의 자식으로 설정
parent=parent_call,
# Weave에서 식별에 사용할 이름을 지정
display_name=item_id,
)
# call의 출력을 답변으로 설정
output = {
"answer_text": item["answer_text"],
}
# 이미 발생한 트레이스이므로 단일 턴 call을 완료 처리
weave_client.finish_call(call=call, output=output)
# 모든 자식 call을 기록했으므로 부모 call도 완료 처리
weave_client.finish_call(call=parent_call, output=parent_output)
보너스: 트레이스를 내보내 엄격한 평가를 수행해 보세요!
## 이 셀은 기본적으로 실행되지 않습니다. 아래 줄을 주석 처리하여 이 스크립트를 실행하세요
%%script false --no-raise-error
## 평가를 위한 모든 Conversation 트레이스를 가져오고 평가용 데이터셋을 준비합니다
# 모든 Conversation 객체를 가져오는 쿼리 필터를 생성합니다
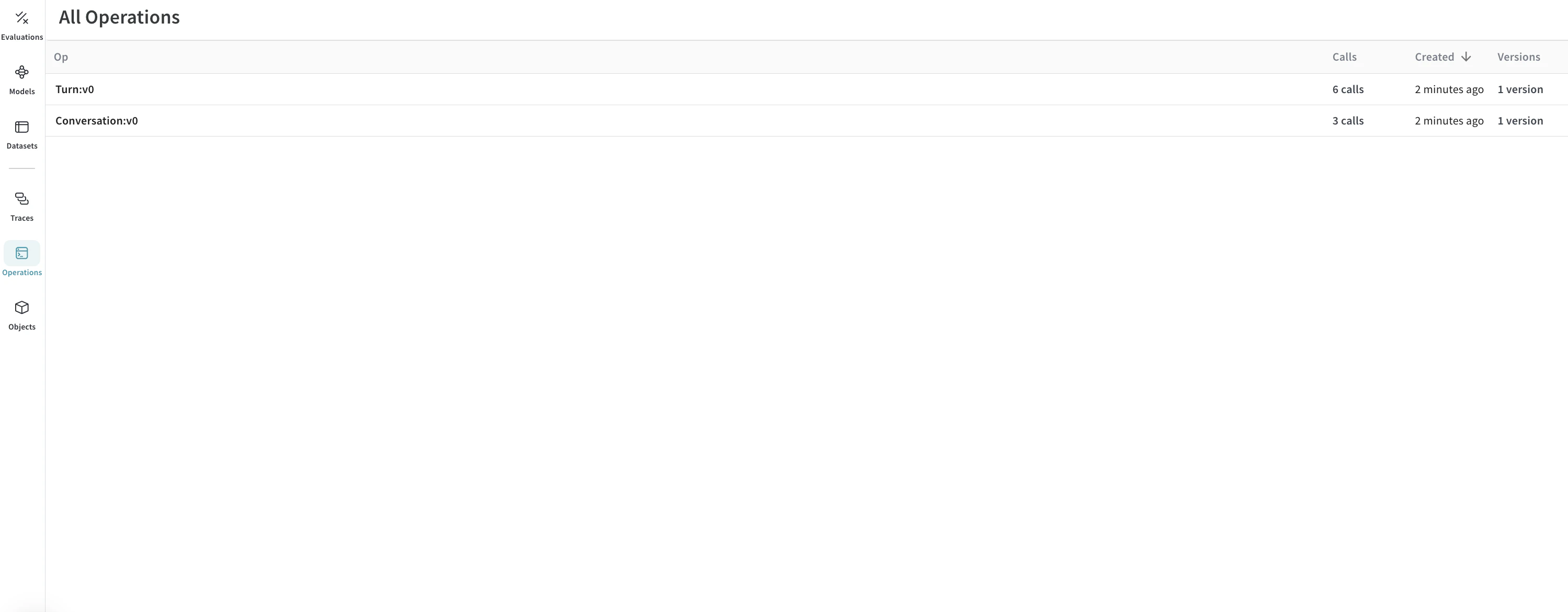
# 아래에 표시된 ref는 해당 프로젝트에 고유하며, UI에서 프로젝트의 Operations로 이동한 후
# "Conversations" 객체를 클릭하고 사이드 패널의 "Use" 탭에서 확인할 수 있습니다.
weave_ref_for_conversation_op = "weave://wandb-smle/import-weave-traces-cookbook/op/Conversation:tzUhDyzVm5bqQsuqh5RT4axEXSosyLIYZn9zbRyenaw"
filter = weave.trace_server.trace_server_interface.CallsFilter(
op_names=[weave_ref_for_conversation_op],
)
# 쿼리를 실행합니다
conversation_traces = weave_client.get_calls(filter=filter)
rows = []
# conversation 트레이스를 순회하며 데이터셋 행을 구성합니다
for single_conv in conversation_traces:
# 이 예시에서는 RAG 파이프라인을 활용한 대화만 처리할 수 있으므로,
# 해당 유형의 대화를 필터링합니다
is_rag = False
for single_trace in single_conv.inputs['conversation_data']:
if single_trace['ground_truth'] is not None:
is_rag = True
break
if single_conv.output['ground_truth'] is not None:
is_rag = True
# RAG를 사용한 대화로 식별되면 데이터셋에 추가합니다
if is_rag:
inputs = []
ground_truths = []
answers = []
# 대화의 모든 턴을 순회합니다
for turn in single_conv.inputs['conversation_data']:
inputs.append(turn.get('user_input', ''))
ground_truths.append(turn.get('ground_truth', ''))
answers.append(turn.get('answer_text', ''))
## 대화가 단일 턴인 경우를 처리합니다
if len(single_conv.inputs) != 1 or single_conv.inputs['conversation_data'][0].get('turn_index') != single_conv.output.get('turn_index'):
inputs.append(single_conv.output.get('user_input', ''))
ground_truths.append(single_conv.output.get('ground_truth', ''))
answers.append(single_conv.output.get('answer_text', ''))
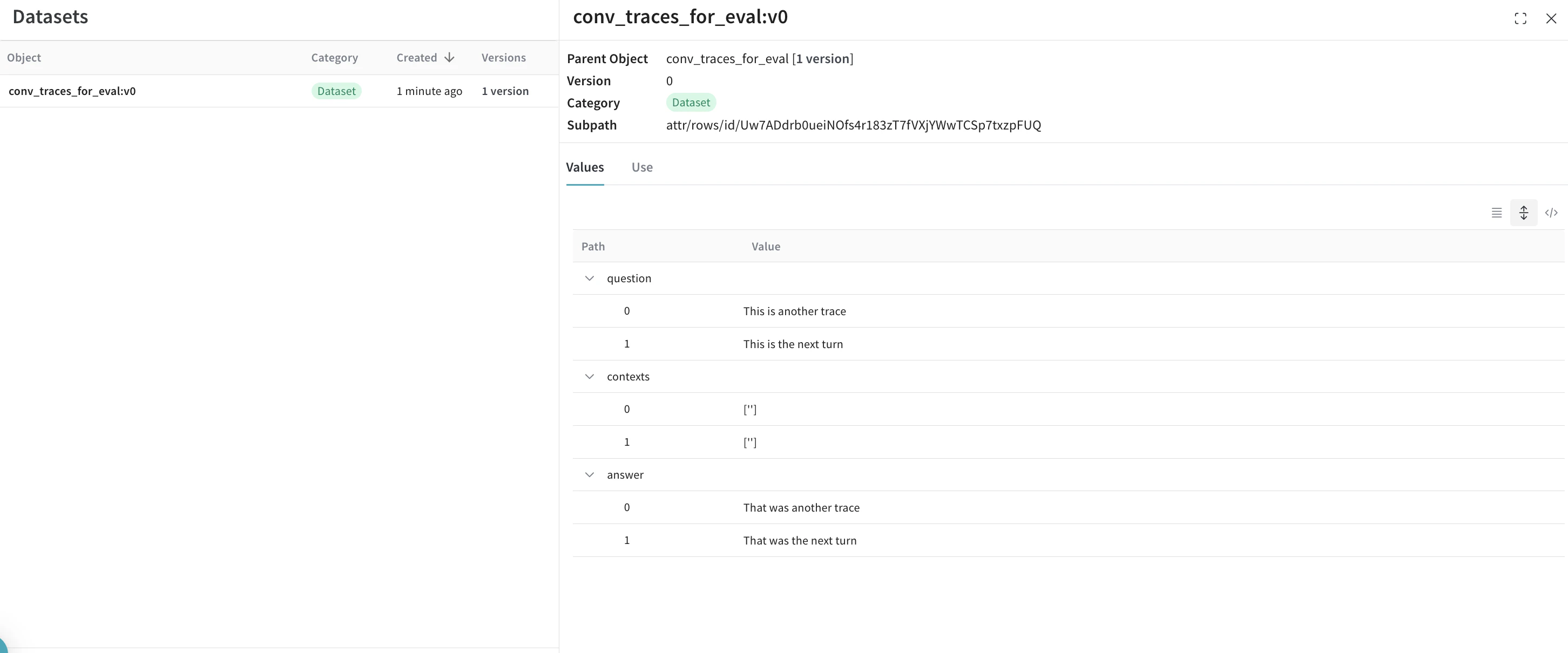
data = {
'question': inputs,
'contexts': ground_truths,
'answer': answers
}
rows.append(data)
# 데이터셋 행이 생성되면 Dataset 객체를 만들고
# 나중에 검색할 수 있도록 Weave에 다시 게시합니다
dset = weave.Dataset(name = "conv_traces_for_eval", rows=rows)
weave.publish(dset)