Documentation Index
Fetch the complete documentation index at: https://translations.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
이 노트북은 대화형입니다. 로컬에서 실행하거나 아래 링크를 사용할 수 있습니다: PII 데이터와 함께 Weave를 사용하는 방법
- PII 데이터를 식별하고 마스킹하기 위한 정규식(regular expressions).
- 파이썬 기반 데이터 보호 SDK인 Microsoft의 Presidio. 이 도구는 마스킹 및 대체(replacement) 기능을 제공합니다.
- PII 데이터를 익명화하기 위해 Presidio와 함께 사용하는, 가짜 데이터를 생성하는 Python 라이브러리 Faker.
또한 weave.op 입력/출력 로깅 커스터마이징 및 _autopatch_settings_을 사용하여 PII 마스킹 및 익명화를 워크플로에 통합하는 방법을 설명합니다. 자세한 내용은 로그되는 입력과 출력 커스터마이즈를 참고하세요.
시작하려면 다음 단계를 따르세요:
- 개요 섹션을 확인합니다.
- 사전 준비 사항을 완료합니다.
- PII 데이터를 식별, 마스킹 및 익명화하기 위한 사용 가능한 방법을 검토합니다.
- 이 방법들을 Weave 호출에 적용합니다.
다음 섹션에서는 weave.op을 사용한 입력 및 출력 로깅 방식과, Weave에서 PII 데이터를 처리할 때의 모범 사례를 살펴봅니다.
Weave op을 사용하면 입력 및 출력에 대한 후처리 함수를 정의할 수 있습니다. 이 함수들을 사용해 LLM 호출에 전달되거나 Weave에 로깅되는 데이터를 수정할 수 있습니다.
다음 예제에서는 두 개의 후처리 함수를 정의하고, 이를 weave.op()의 인자로 전달합니다.
from dataclasses import dataclass
from typing import Any
import weave
# 입력 래퍼 클래스
@dataclass
class CustomObject:
x: int
secret_password: str
# 먼저 입력 및 출력 후처리 함수를 정의합니다:
def postprocess_inputs(inputs: dict[str, Any]) -> dict[str, Any]:
return {k:v for k,v in inputs.items() if k != "hide_me"}
def postprocess_output(output: CustomObject) -> CustomObject:
return CustomObject(x=output.x, secret_password="REDACTED")
# 그런 다음, `@weave.op` 데코레이터를 사용할 때 이 처리 함수들을 데코레이터의 인수로 전달합니다:
@weave.op(
postprocess_inputs=postprocess_inputs,
postprocess_output=postprocess_output,
)
def some_llm_call(a: int, hide_me: str) -> CustomObject:
return CustomObject(x=a, secret_password=hide_me)
PII 데이터와 함께 Weave 사용 시 모범 사례
- PII 탐지를 확인하기 위해 익명화된 데이터를 로그로 남기세요
- Weave Traces로 PII 처리 프로세스를 추적하세요
- 실제 PII를 노출하지 않고 익명화 성능을 측정하세요
- PII 원본 데이터는 절대 로그에 남기지 마세요
- 민감한 필드는 로깅 전에 암호화하세요
- 나중에 복호화해야 하는 데이터에는 복호화 가능한 암호화를 사용하세요
- 역으로 복원할 필요가 없는 고유 ID에는 단방향 해시를 적용하세요
- 암호화된 상태로 분석해야 하는 데이터에는 특수 암호화 기법 사용을 고려하세요
- 먼저 필요한 패키지를 설치합니다.
%%capture
# @title 필요한 파이썬 패키지:
!pip install cryptography
!pip install presidio_analyzer
!pip install presidio_anonymizer
!python -m spacy download en_core_web_lg # Presidio는 spacy NLP 엔진을 사용합니다
!pip install Faker # PII 데이터를 가짜 데이터로 대체하기 위해 Faker를 사용합니다
!pip install weave # Traces 활용을 위해
!pip install set-env-colab-kaggle-dotenv -q # 환경 변수 설정용
!pip install anthropic # sonnet 사용을 위해
!pip install cryptography # 데이터 암호화를 위해
-
다음에서 API key를 생성합니다:
%%capture
# @title API key를 올바르게 설정하세요
# 사용 방법은 https://pypi.org/project/set-env-colab-kaggle-dotenv/ 를 참조하세요.
from set_env import set_env
_ = set_env("ANTHROPIC_API_KEY")
_ = set_env("WANDB_API_KEY")
- Weave 프로젝트를 초기화합니다.
import weave
# 새 Weave 프로젝트 시작
WEAVE_PROJECT = "pii_cookbook"
weave.init(WEAVE_PROJECT)
- 10개의 텍스트 블록이 포함된 데모용 PII 데이터셋을 로드합니다.
import requests
url = "https://raw.githubusercontent.com/wandb/docs/main/weave/cookbooks/source/10_pii_data.json"
response = requests.get(url)
pii_data = response.json()
print('PII data first sample: "' + pii_data[0]["text"] + '"')
- 정규식(regular expressions) 으로 PII 데이터를 식별하고 비식별화합니다.
- Microsoft Presidio: 비식별화 및 치환 기능을 제공하는 Python 기반 데이터 보호 SDK입니다.
- Faker: 가짜 데이터를 생성하는 Python 라이브러리입니다.
정규 표현식(regular expressions, regex)은 PII 데이터를 식별하고 비식별 처리(마스킹)하는 가장 간단한 방법입니다. Regex를 사용하면 전화번호, 이메일 주소, 사회보장번호와 같은 민감한 정보의 다양한 형식에 일치하는 패턴을 정의할 수 있습니다. Regex를 이용해 방대한 양의 텍스트를 검사하면서 더 복잡한 NLP 기법 없이도 정보를 대체하거나 비식별 처리할 수 있습니다.
import re
# regex를 사용하여 PII 데이터를 정제하는 함수 정의
def redact_with_regex(text):
# 전화번호 패턴
# \b : 단어 경계
# \d{3} : 정확히 3자리 숫자
# [-.]? : 선택적 하이픈 또는 점
# \d{3} : 3자리 숫자 추가
# [-.]? : 선택적 하이픈 또는 점
# \d{4} : 정확히 4자리 숫자
# \b : 단어 경계
text = re.sub(r"\b\d{3}[-.]?\d{3}[-.]?\d{4}\b", "<PHONE>", text)
# 이메일 패턴
# \b : 단어 경계
# [A-Za-z0-9._%+-]+ : 이메일 사용자 이름에 사용 가능한 하나 이상의 문자
# @ : 리터럴 @ 기호
# [A-Za-z0-9.-]+ : 도메인 이름에 사용 가능한 하나 이상의 문자
# \. : 리터럴 점
# [A-Z|a-z]{2,} : 두 글자 이상의 대문자 또는 소문자 (TLD)
# \b : 단어 경계
text = re.sub(
r"\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b", "<EMAIL>", text
)
# SSN 패턴
# \b : 단어 경계
# \d{3} : 정확히 3자리 숫자
# - : 리터럴 하이픈
# \d{2} : 정확히 2자리 숫자
# - : 리터럴 하이픈
# \d{4} : 정확히 4자리 숫자
# \b : 단어 경계
text = re.sub(r"\b\d{3}-\d{2}-\d{4}\b", "<SSN>", text)
# 간단한 이름 패턴 (완전하지 않음)
# \b : 단어 경계
# [A-Z] : 대문자 한 글자
# [a-z]+ : 하나 이상의 소문자
# \s : 공백 문자 하나
# [A-Z] : 대문자 한 글자
# [a-z]+ : 하나 이상의 소문자
# \b : 단어 경계
text = re.sub(r"\b[A-Z][a-z]+ [A-Z][a-z]+\b", "<NAME>", text)
return text
# 함수 테스트
test_text = "My name is John Doe, my email is john.doe@example.com, my phone is 123-456-7890, and my SSN is 123-45-6789."
cleaned_text = redact_with_regex(test_text)
print(f"Raw text:\n\t{test_text}")
print(f"Redacted text:\n\t{cleaned_text}")
방법 2: Microsoft Presidio를 사용한 비식별화
"My name is Alex"에서 Alex를 <PERSON>으로 대체합니다.
Presidio에는 일반적인 엔티티에 대한 기본 지원이 포함되어 있습니다. 아래 예제에서는 PHONE_NUMBER, PERSON, LOCATION, EMAIL_ADDRESS, US_SSN인 모든 엔티티를 마스킹합니다. Presidio 처리 과정은 하나의 함수로 캡슐화되어 있습니다.
from presidio_analyzer import AnalyzerEngine
from presidio_anonymizer import AnonymizerEngine
# Analyzer를 설정합니다. NLP 모듈(기본값: spaCy 모델)과 기타 PII 인식기를 로드합니다.
analyzer = AnalyzerEngine()
# Anonymizer를 설정합니다. 분석기 결과를 사용하여 텍스트를 익명화합니다.
anonymizer = AnonymizerEngine()
# Presidio 편집 프로세스를 함수로 캡슐화합니다
def redact_with_presidio(text):
# 텍스트를 분석하여 PII 데이터를 식별합니다
results = analyzer.analyze(
text=text,
entities=["PHONE_NUMBER", "PERSON", "LOCATION", "EMAIL_ADDRESS", "US_SSN"],
language="en",
)
# 식별된 PII 데이터를 익명화합니다
anonymized_text = anonymizer.anonymize(text=text, analyzer_results=results)
return anonymized_text.text
text = "My phone number is 212-555-5555 and my name is alex"
# 함수 테스트
anonymized_text = redact_with_presidio(text)
print(f"원본 텍스트:\n\t{text}")
print(f"삭제된 텍스트:\n\t{anonymized_text}")
방법 3: Faker와 Presidio를 사용한 치환 기반 익명화
"My name is Raphael and I like to fish. My phone number is 212-555-5555"
이 데이터를 Presidio와 Faker로 처리하면 다음과 같이 변환될 수 있습니다:
"My name is Katherine Dixon and I like to fish. My phone number is 667.431.7379"
Presidio와 Faker를 효과적으로 함께 사용하려면, 사용자 정의 연산자에 대한 참조를 제공해야 합니다. 이 연산자들은 Presidio가 PII를 가짜 데이터로 치환하는 데 사용할 Faker 함수들을 호출하도록 지정합니다.
from faker import Faker
from presidio_anonymizer import AnonymizerEngine
from presidio_anonymizer.entities import OperatorConfig
fake = Faker()
# faker 함수 생성 (값을 인수로 받아야 한다는 점에 유의)
def fake_name(x):
return fake.name()
def fake_number(x):
return fake.phone_number()
# PERSON 및 PHONE_NUMBER 엔티티에 대한 커스텀 연산자 생성
operators = {
"PERSON": OperatorConfig("custom", {"lambda": fake_name}),
"PHONE_NUMBER": OperatorConfig("custom", {"lambda": fake_number}),
}
text_to_anonymize = (
"My name is Raphael and I like to fish. My phone number is 212-555-5555"
)
# 분석기 출력
analyzer_results = analyzer.analyze(
text=text_to_anonymize, entities=["PHONE_NUMBER", "PERSON"], language="en"
)
anonymizer = AnonymizerEngine()
# 위에서 정의한 operators를 익명화 엔진에 전달하는 것을 잊지 마세요
anonymized_results = anonymizer.anonymize(
text=text_to_anonymize, analyzer_results=analyzer_results, operators=operators
)
print(f"Raw text:\n\t{text_to_anonymize}")
print(f"Anonymized text:\n\t{anonymized_results.text}")
from typing import ClassVar
from faker import Faker
from presidio_anonymizer import AnonymizerEngine
from presidio_anonymizer.entities import OperatorConfig
# Faker를 확장하여 가짜 데이터를 생성하는 커스텀 클래스
class MyFaker(Faker):
# faker 함수 생성 (값을 반드시 받아야 함에 유의)
def fake_address(self):
return fake.address()
def fake_ssn(self):
return fake.ssn()
def fake_name(self):
return fake.name()
def fake_number(self):
return fake.phone_number()
def fake_email(self):
return fake.email()
# 엔티티에 대한 커스텀 연산자 생성
operators: ClassVar[dict[str, OperatorConfig]] = {
"PERSON": OperatorConfig("custom", {"lambda": fake_name}),
"PHONE_NUMBER": OperatorConfig("custom", {"lambda": fake_number}),
"EMAIL_ADDRESS": OperatorConfig("custom", {"lambda": fake_email}),
"LOCATION": OperatorConfig("custom", {"lambda": fake_address}),
"US_SSN": OperatorConfig("custom", {"lambda": fake_ssn}),
}
def redact_and_anonymize_with_faker(self, text):
anonymizer = AnonymizerEngine()
analyzer_results = analyzer.analyze(
text=text,
entities=["PHONE_NUMBER", "PERSON", "LOCATION", "EMAIL_ADDRESS", "US_SSN"],
language="en",
)
anonymized_results = anonymizer.anonymize(
text=text, analyzer_results=analyzer_results, operators=self.operators
)
return anonymized_results.text
faker = MyFaker()
text_to_anonymize = (
"My name is Raphael and I like to fish. My phone number is 212-555-5555"
)
anonymized_text = faker.redact_and_anonymize_with_faker(text_to_anonymize)
print(f"Raw text:\n\t{text_to_anonymize}")
print(f"Anonymized text:\n\t{anonymized_text}")
방법 4: autopatch_settings 사용
autopatch_settings를 사용하면 지원되는 하나 이상의 LLM 통합에 대해 초기화 시점에 PII 처리를 직접 구성할 수 있습니다. 이 방법의 장점은 다음과 같습니다.
- PII 처리 로직이 초기화 시점에 중앙집중식으로 정의되므로, 여기저기 흩어진 커스텀 로직을 둘 필요가 줄어듭니다.
- 특정 통합에 대해서는 PII 처리 워크플로를 커스터마이즈하거나 완전히 비활성화할 수 있습니다.
autopatch_settings를 사용해 PII 처리를 구성하려면, 지원되는 LLM 통합 중 하나의 op_settings에서 postprocess_inputs 및/또는 postprocess_output을 정의하십시오.
def postprocess(inputs: dict) -> dict:
if "SENSITIVE_KEY" in inputs:
inputs["SENSITIVE_KEY"] = "REDACTED"
return inputs
client = weave.init(
...,
autopatch_settings={
"openai": {
"op_settings": {
"postprocess_inputs": postprocess,
"postprocess_output": ...,
}
},
"anthropic": {
"op_settings": {
"postprocess_inputs": ...,
"postprocess_output": ...,
}
}
},
)
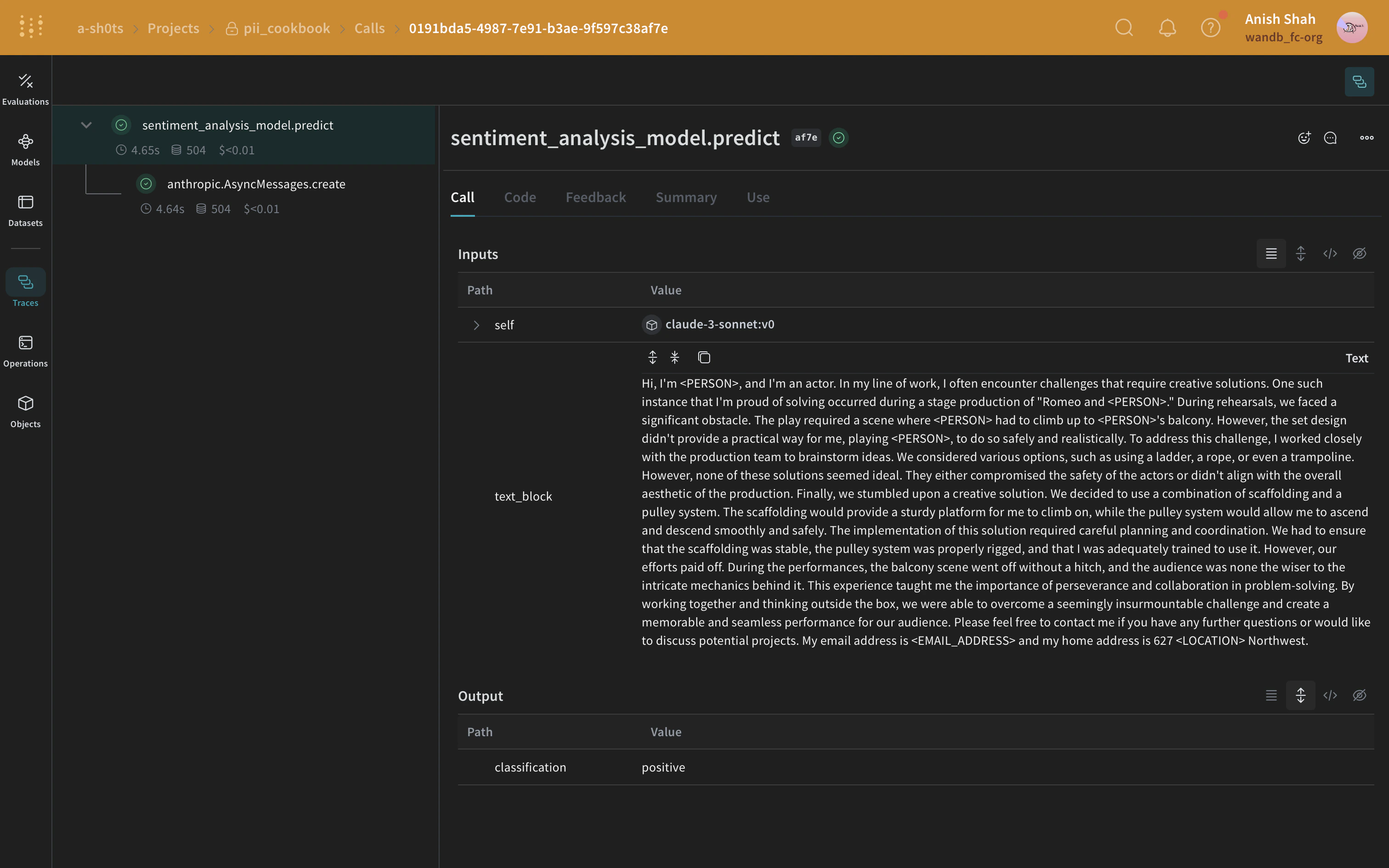
predict 함수를 포함합니다. Anthropic의 Claude Sonnet은 Traces를 사용해 LLM 호출을 추적하면서 감성 분석을 수행하는 데 사용됩니다. Claude Sonnet은 텍스트 블록을 입력으로 받아 다음 감성 분류 중 하나를 출력합니다: positive, negative, 또는 neutral. 추가로, PII 데이터가 LLM으로 전송되기 전에 마스킹되거나 익명화되도록 후처리(postprocessing) 함수도 포함합니다.
이 코드를 실행하면 Weave 프로젝트 페이지와, 실행한 특정 trace(LLM 호출)에 대한 링크들을 받게 됩니다.
가장 단순한 방법은 정규 표현식을 사용해 원본 텍스트에서 PII 데이터를 식별하고 마스킹하는 것입니다.
import json
from typing import Any
import anthropic
import weave
# 모델 예측 Weave Op에 regex 난독화를 적용하는 입력 후처리 함수 정의
def postprocess_inputs_regex(inputs: dict[str, Any]) -> dict:
inputs["text_block"] = redact_with_regex(inputs["text_block"])
return inputs
# Weave 모델 / 예측 함수
class SentimentAnalysisRegexPiiModel(weave.Model):
model_name: str
system_prompt: str
temperature: int
@weave.op(
postprocess_inputs=postprocess_inputs_regex,
)
async def predict(self, text_block: str) -> dict:
client = anthropic.AsyncAnthropic()
response = await client.messages.create(
max_tokens=1024,
model=self.model_name,
system=self.system_prompt,
messages=[
{"role": "user", "content": [{"type": "text", "text": text_block}]}
],
)
result = response.content[0].text
if result is None:
raise ValueError("No response from model")
parsed = json.loads(result)
return parsed
python
# 시스템 프롬프트로 LLM 모델 생성
model = SentimentAnalysisRegexPiiModel(
name="claude-3-sonnet",
model_name="claude-3-5-sonnet-20240620",
system_prompt='You are a Sentiment Analysis classifier. You will be classifying text based on their sentiment. Your input will be a block of text. You will answer with one the following rating option["positive", "negative", "neutral"]. Your answer should be one word in json format: {classification}. Ensure that it is valid JSON.',
temperature=0,
)
print("Model: ", model)
# 각 텍스트 블록에 대해 먼저 익명화한 후 예측 수행
for entry in pii_data:
await model.predict(entry["text"])
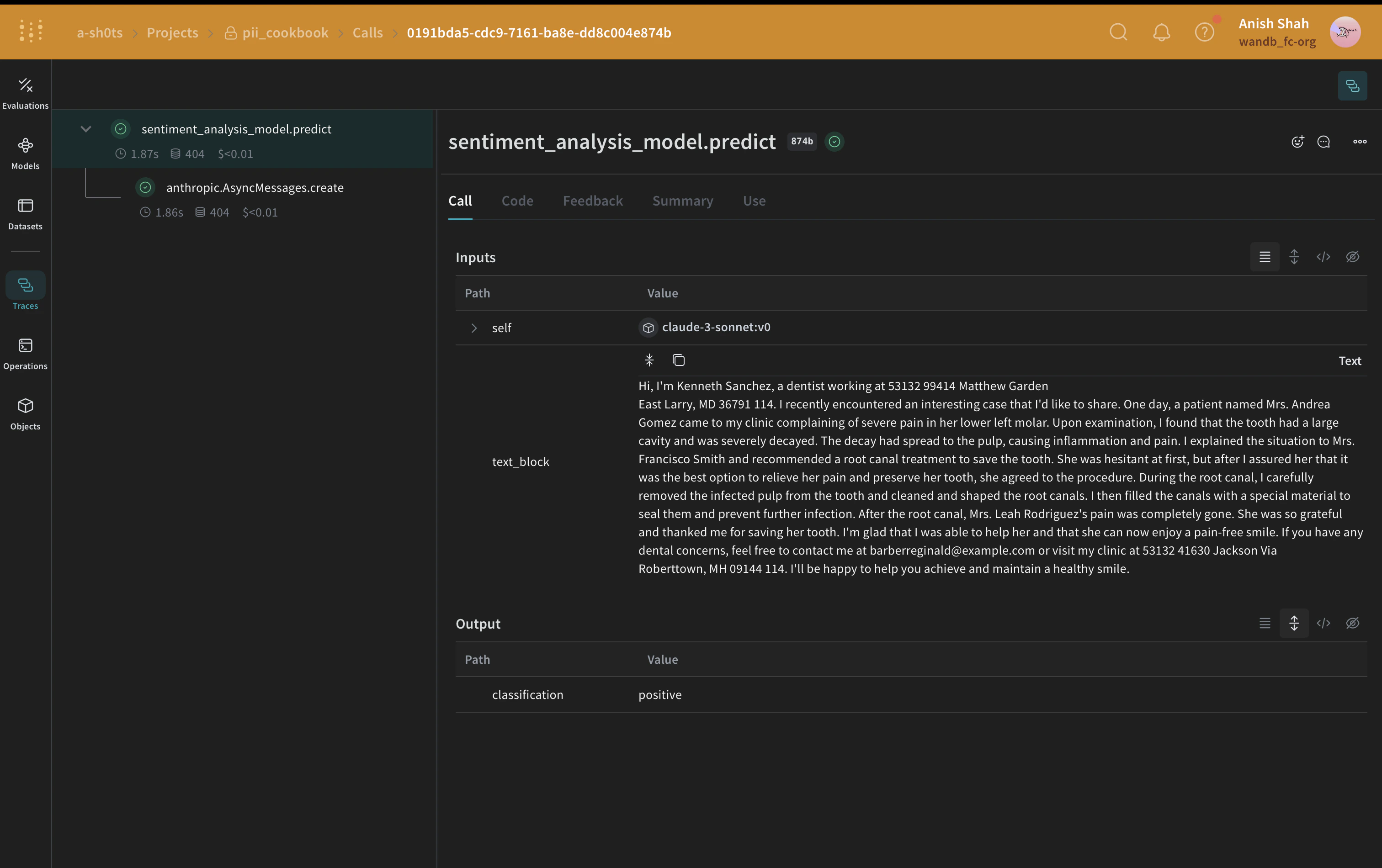
Presidio 마스킹(redaction) 방법
from typing import Any
import weave
# 모델 예측 Weave Op에 Presidio 편집을 적용하는 입력 후처리 함수 정의
def postprocess_inputs_presidio(inputs: dict[str, Any]) -> dict:
inputs["text_block"] = redact_with_presidio(inputs["text_block"])
return inputs
# Weave 모델 / 예측 함수
class SentimentAnalysisPresidioPiiModel(weave.Model):
model_name: str
system_prompt: str
temperature: int
@weave.op(
postprocess_inputs=postprocess_inputs_presidio,
)
async def predict(self, text_block: str) -> dict:
client = anthropic.AsyncAnthropic()
response = await client.messages.create(
max_tokens=1024,
model=self.model_name,
system=self.system_prompt,
messages=[
{"role": "user", "content": [{"type": "text", "text": text_block}]}
],
)
result = response.content[0].text
if result is None:
raise ValueError("No response from model")
parsed = json.loads(result)
return parsed
python
# 시스템 프롬프트로 LLM 모델 생성
model = SentimentAnalysisPresidioPiiModel(
name="claude-3-sonnet",
model_name="claude-3-5-sonnet-20240620",
system_prompt='You are a Sentiment Analysis classifier. You will be classifying text based on their sentiment. Your input will be a block of text. You will answer with one the following rating option["positive", "negative", "neutral"]. Your answer should be one word in json format: {classification}. Ensure that it is valid JSON.',
temperature=0,
)
print("Model: ", model)
# 각 텍스트 블록에 대해 먼저 익명화한 후 예측 수행
for entry in pii_data:
await model.predict(entry["text"])
Faker 및 Presidio를 사용한 치환 방법
from typing import Any
import weave
# 모델 예측 Weave Op에 Faker 익명화 및 Presidio 편집을 적용하는 입력 후처리 함수 정의
faker = MyFaker()
def postprocess_inputs_faker(inputs: dict[str, Any]) -> dict:
inputs["text_block"] = faker.redact_and_anonymize_with_faker(inputs["text_block"])
return inputs
# Weave 모델 / 예측 함수
class SentimentAnalysisFakerPiiModel(weave.Model):
model_name: str
system_prompt: str
temperature: int
@weave.op(
postprocess_inputs=postprocess_inputs_faker,
)
async def predict(self, text_block: str) -> dict:
client = anthropic.AsyncAnthropic()
response = await client.messages.create(
max_tokens=1024,
model=self.model_name,
system=self.system_prompt,
messages=[
{"role": "user", "content": [{"type": "text", "text": text_block}]}
],
)
result = response.content[0].text
if result is None:
raise ValueError("No response from model")
parsed = json.loads(result)
return parsed
python
# 시스템 프롬프트로 LLM 모델 생성
model = SentimentAnalysisFakerPiiModel(
name="claude-3-sonnet",
model_name="claude-3-5-sonnet-20240620",
system_prompt='You are a Sentiment Analysis classifier. You will be classifying text based on their sentiment. Your input will be a block of text. You will answer with one the following rating option["positive", "negative", "neutral"]. Your answer should be one word in json format: {classification}. Ensure that it is valid JSON.',
temperature=0,
)
print("Model: ", model)
# 각 텍스트 블록에 대해 먼저 익명화한 후 예측 수행
for entry in pii_data:
await model.predict(entry["text"])
anthropic에 대한 postprocess_inputs를 postprocess_inputs_regex() 함수로 설정합니다. postprocess_inputs_regex 함수는 Method 1: Regular Expression Filtering에서 정의한 redact_with_regex 메서드를 적용합니다. 이제 redact_with_regex가 모든 anthropic 모델의 모든 입력에 자동으로 적용됩니다.
from typing import Any
import weave
client = weave.init(
...,
autopatch_settings={
"anthropic": {
"op_settings": {
"postprocess_inputs": postprocess_inputs_regex,
}
}
},
)
# 모델 예측 Weave Op에 정규식 난독화를 적용하는 입력 후처리 함수 정의
def postprocess_inputs_regex(inputs: dict[str, Any]) -> dict:
inputs["text_block"] = redact_with_regex(inputs["text_block"])
return inputs
# Weave 모델 / 예측 함수
class SentimentAnalysisRegexPiiModel(weave.Model):
model_name: str
system_prompt: str
temperature: int
async def predict(self, text_block: str) -> dict:
client = anthropic.AsyncAnthropic()
response = await client.messages.create(
max_tokens=1024,
model=self.model_name,
system=self.system_prompt,
messages=[
{"role": "user", "content": [{"type": "text", "text": text_block}]}
],
)
result = response.content[0].text
if result is None:
raise ValueError("No response from model")
parsed = json.loads(result)
return parsed
python
# 시스템 프롬프트로 LLM 모델 생성
model = SentimentAnalysisRegexPiiModel(
name="claude-3-sonnet",
model_name="claude-3-5-sonnet-20240620",
system_prompt='You are a Sentiment Analysis classifier. You will be classifying text based on their sentiment. Your input will be a block of text. You will answer with one the following rating option["positive", "negative", "neutral"]. Your answer should be one word in json format: {classification}. Ensure that it is valid JSON.',
temperature=0,
)
print("Model: ", model)
# 각 텍스트 블록에 대해 먼저 익명화한 후 예측 수행
for entry in pii_data:
await model.predict(entry["text"])
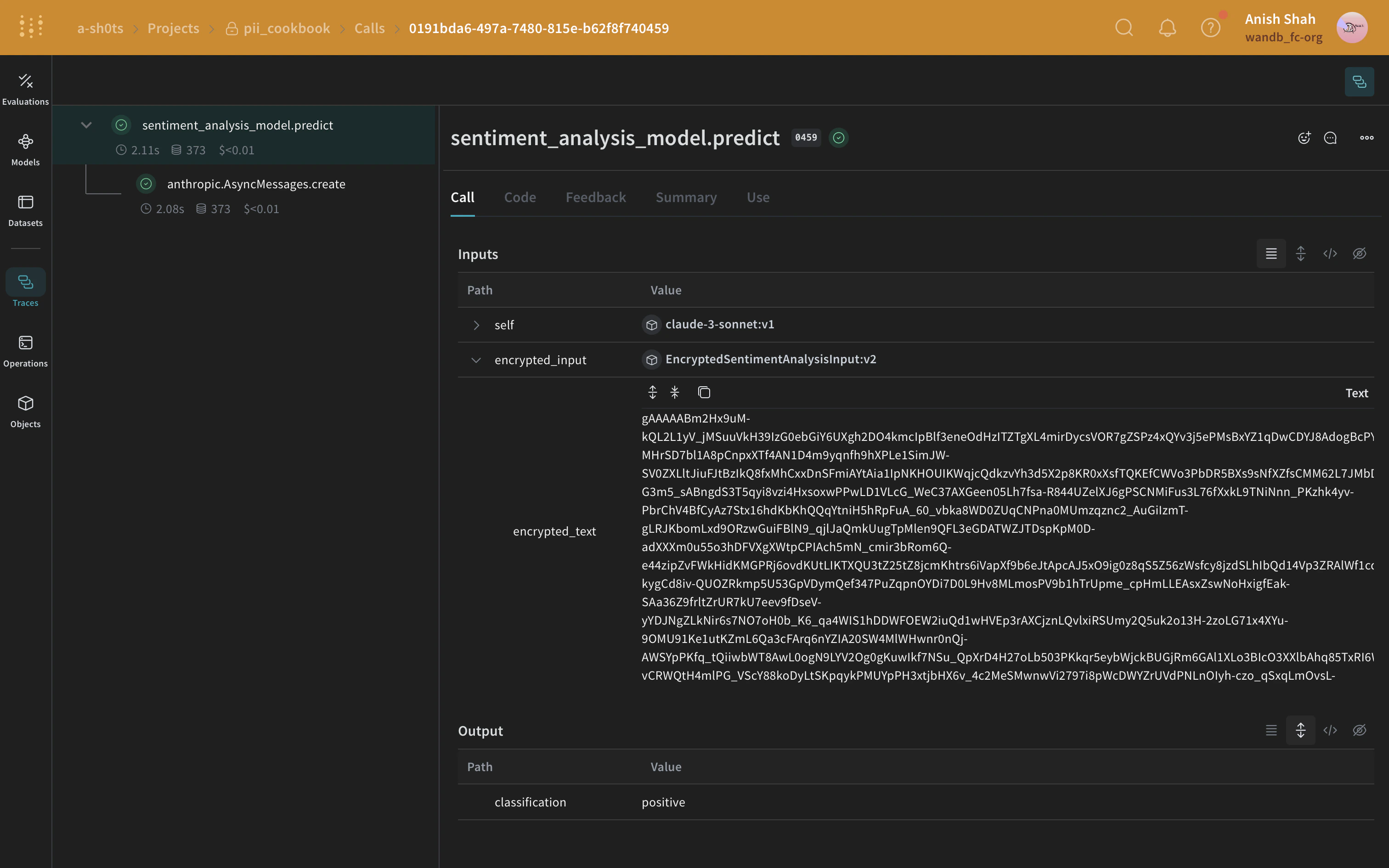
cryptography 라이브러리의 Fernet 대칭키 암호화를 사용해 데이터에 추가적인 보안 계층을 더할 수 있습니다. 이 방식은 익명화된 데이터가 가로채이더라도 암호화 키 없이는 내용을 해독할 수 없도록 보장합니다.
import os
from cryptography.fernet import Fernet
from pydantic import BaseModel, ValidationInfo, model_validator
def get_fernet_key():
# 환경 변수에 키가 존재하는지 확인
key = os.environ.get('FERNET_KEY')
if key is None:
# 키가 존재하지 않으면 새로 생성
key = Fernet.generate_key()
# 환경 변수에 키 저장
os.environ['FERNET_KEY'] = key.decode()
else:
# 키가 존재하면 바이트 형식으로 변환
key = key.encode()
return key
cipher_suite = Fernet(get_fernet_key())
class EncryptedSentimentAnalysisInput(BaseModel):
encrypted_text: str = None
@model_validator(mode="before")
def encrypt_fields(cls, values):
if "text" in values and values["text"] is not None:
values["encrypted_text"] = cipher_suite.encrypt(values["text"].encode()).decode()
del values["text"]
return values
@property
def text(self):
if self.encrypted_text:
return cipher_suite.decrypt(self.encrypted_text.encode()).decode()
return None
@text.setter
def text(self, value):
self.encrypted_text = cipher_suite.encrypt(str(value).encode()).decode()
@classmethod
def encrypt(cls, text: str):
return cls(text=text)
def decrypt(self):
return self.text
# 새로운 EncryptedSentimentAnalysisInput을 사용하도록 수정된 sentiment_analysis_model
class sentiment_analysis_model(weave.Model):
model_name: str
system_prompt: str
temperature: int
@weave.op()
async def predict(self, encrypted_input: EncryptedSentimentAnalysisInput) -> dict:
client = AsyncAnthropic()
decrypted_text = encrypted_input.decrypt() # 커스텀 클래스를 사용하여 텍스트를 복호화
response = await client.messages.create(
max_tokens=1024,
model=self.model_name,
system=self.system_prompt,
messages=[
{ "role": "user",
"content":[
{
"type": "text",
"text": decrypted_text
}
]
}
]
)
result = response.content[0].text
if result is None:
raise ValueError("No response from model")
parsed = json.loads(result)
return parsed
model = sentiment_analysis_model(
name="claude-3-sonnet",
model_name="claude-3-5-sonnet-20240620",
system_prompt="You are a Sentiment Analysis classifier. You will be classifying text based on their sentiment. Your input will be a block of text. You will answer with one the following rating option[\"positive\", \"negative\", \"neutral\"]. Your answer should one word in json format dict where the key is classification.",
temperature=0
)
for entry in pii_data:
encrypted_input = EncryptedSentimentAnalysisInput.encrypt(entry["text"])
await model.predict(encrypted_input)