Kubeflow Pipelines (kfp) 는 Docker 컨테이너를 기반으로 이식성과 확장성을 갖춘 머신러닝(ML) 워크플로우를 구축하고 배포하기 위한 플랫폼입니다. 이 통합을 사용하면 kfp Python 함수형 컴포넌트에 데코레이터를 적용해 매개변수와 아티팩트를 W&B에 자동으로 로깅할 수 있습니다. 이 기능은Documentation Index
Fetch the complete documentation index at: https://translations.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
wandb==0.12.11에서 활성화되었으며 kfp<2.0.0이 필요합니다.
회원가입 및 API key 생성
보다 간편하게 설정하려면 User Settings로 바로 이동해 API key를 생성하세요. 새로 생성된 API key는 즉시 복사하여 비밀번호 관리자와 같은 안전한 위치에 저장하세요.
- 오른쪽 상단에서 사용자 프로필 아이콘을 클릭합니다.
- User Settings를 선택한 다음, 아래로 스크롤하여 API Keys 섹션으로 이동합니다.
wandb 라이브러리를 설치하고 로그인하기
wandb 라이브러리를 설치하고 로그인하려면 다음 단계를 수행하세요:
- 명령줄
- Python
- Python 노트북
-
WANDB_API_KEY환경 변수를 API key로 설정합니다. -
wandb라이브러리를 설치하고 로그인합니다.
컴포넌트에 데코레이터 적용하기
@wandb_log 데코레이터를 적용한 다음 평소처럼 컴포넌트를 작성하세요. 그러면 파이프라인을 실행할 때마다 입력 및 출력 매개변수와 아티팩트가 자동으로 W&B에 로깅됩니다.
컨테이너에 환경 변수 전달하기
WANDB_KUBEFLOW_URL에 Kubeflow Pipelines 인스턴스의 기본 URL을 설정해야 합니다. 예를 들어 https://kubeflow.mysite.com처럼 설정합니다.
프로그래밍 방식으로 데이터에 접근하기
Kubeflow Pipelines UI를 통한 접근
Input/Output및ML Metadata탭에서 입력과 출력에 대한 세부 정보를 확인합니다.Visualizations탭에서 W&B 웹 앱을 확인합니다.
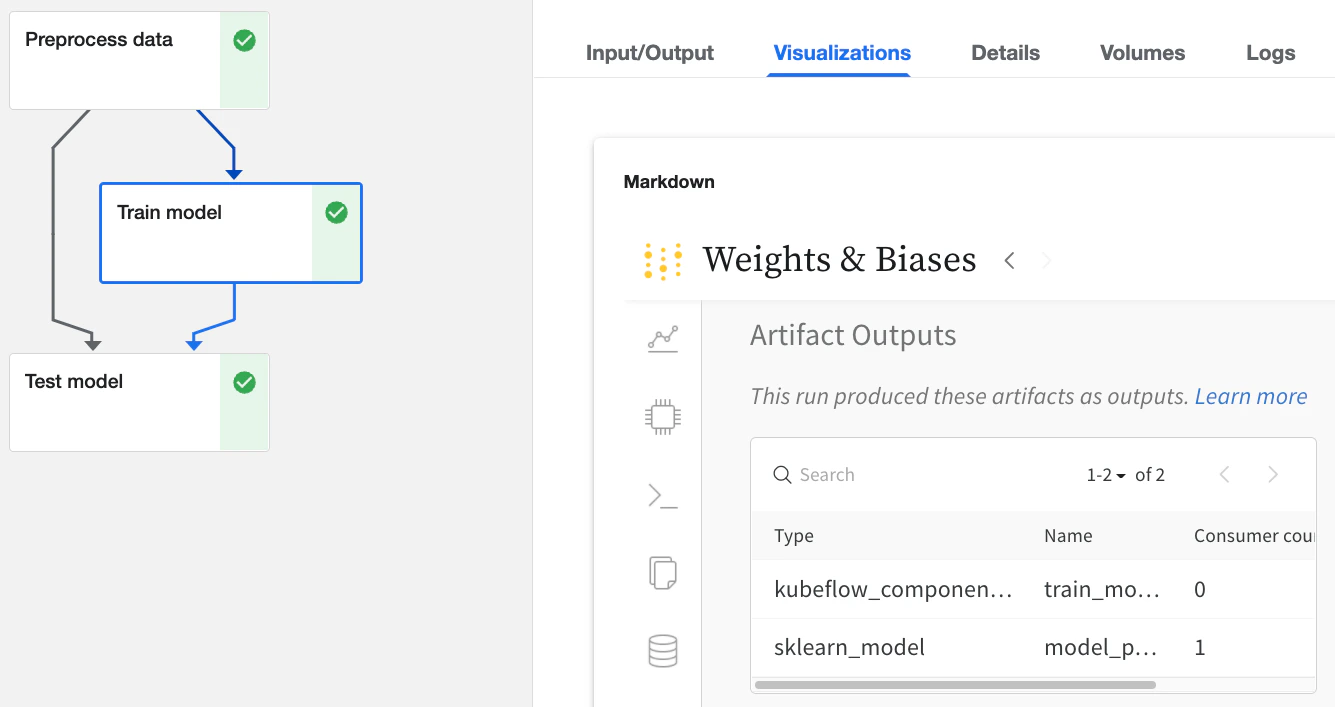
웹 앱 UI를 통해
Visualizations 탭과 동일한 내용을 보여주지만, 더 넓은 화면 공간을 제공합니다. 웹 앱 UI에 대해 자세히 알아보려면 여기를 참조하세요.
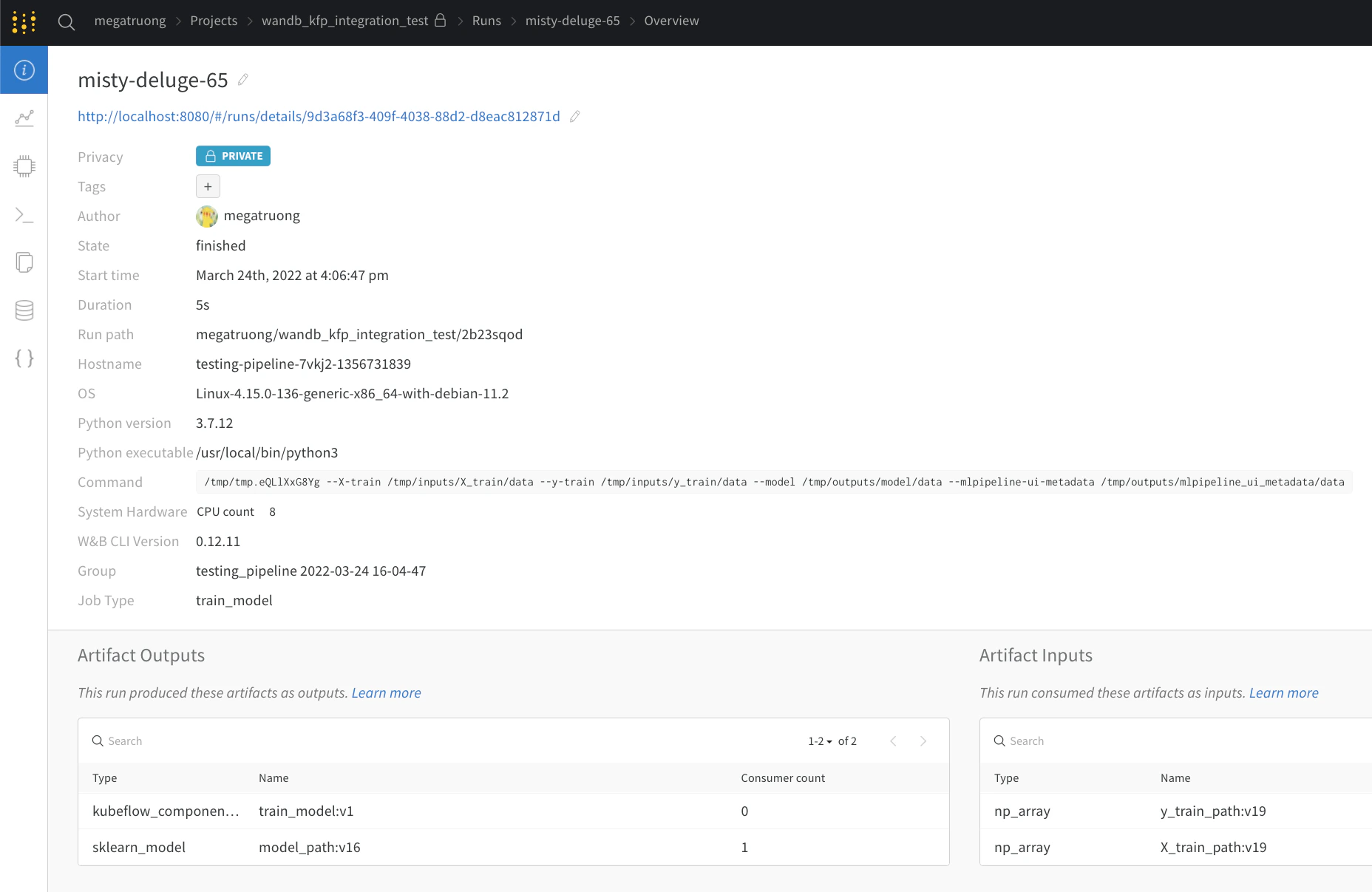
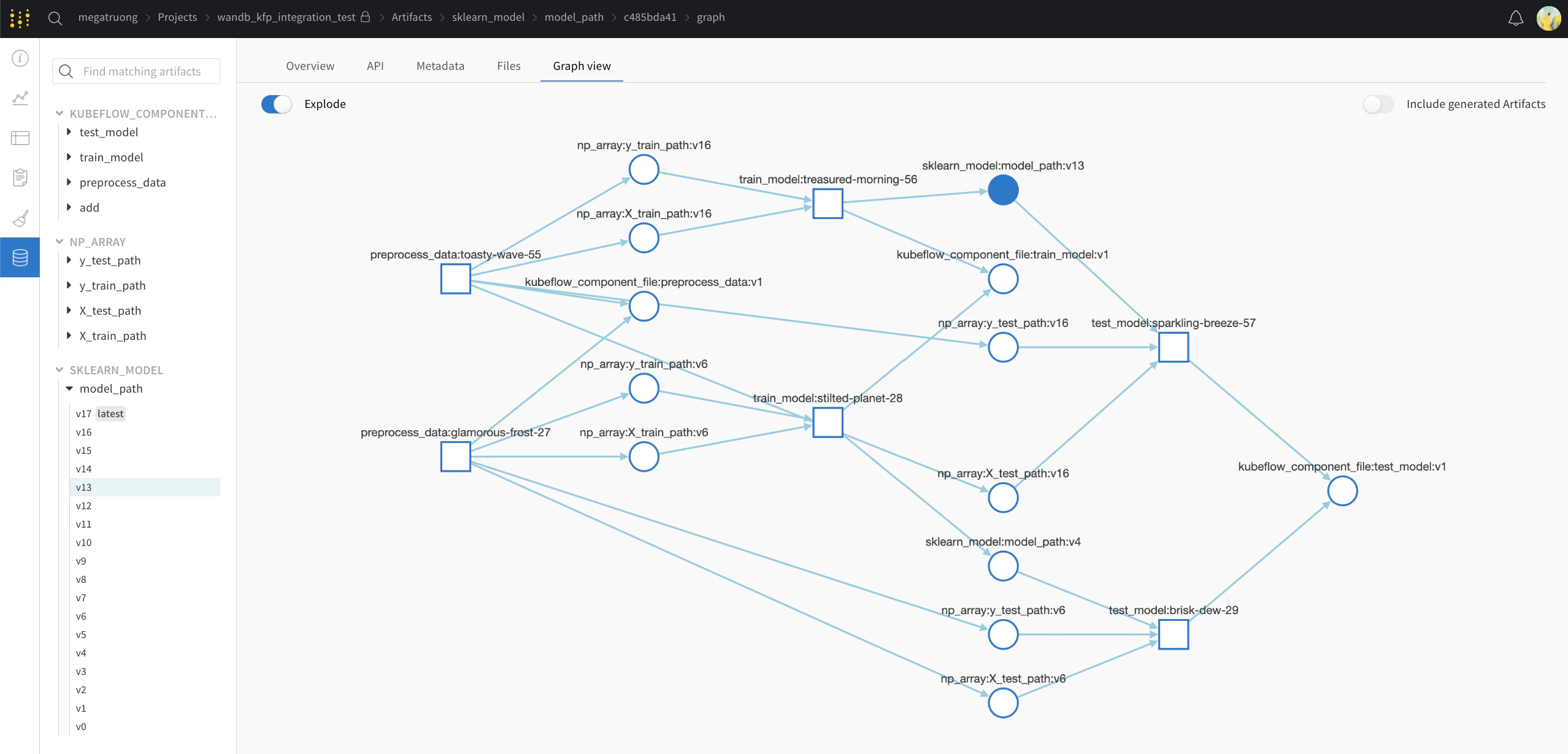
Public API를 통한 액세스(프로그래밍 방식 접근용)
- 프로그래밍 방식으로 액세스하려면 Public API 문서를 참고하세요.
Kubeflow Pipelines와 W&B 개념 매핑
| Kubeflow Pipelines | W&B | W&B에서의 위치 |
|---|---|---|
| Input Scalar | config | Overview 탭 |
| Output Scalar | summary | Overview 탭 |
| Input Artifact | 입력 아티팩트 | Artifacts 탭 |
| Output Artifact | 출력 아티팩트 | Artifacts 탭 |
세밀한 로깅
wandb.log와 wandb.log_artifact 호출을 추가하면 됩니다.
명시적으로 wandb.log_artifacts 호출하기
@wandb_log 데코레이터는 관련 입력과 출력을 자동으로 추적합니다. 학습 과정을 로깅하고 싶다면, 다음과 같이 명시적으로 로깅을 추가할 수 있습니다: