W&B에서 모델 아티팩트를 NVIDIA NeMo Inference Microservice에 배포합니다. 이를 위해 W&B Launch를 사용합니다. W&B Launch는 모델 아티팩트를 NVIDIA NeMo 모델로 변환한 뒤, 실행 중인 NIM/Triton 서버에 배포합니다. W&B Launch는 현재 다음과 같은 호환되는 모델 유형을 지원합니다:Documentation Index
Fetch the complete documentation index at: https://translations.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
배포 시간은 모델과 머신 유형에 따라 달라집니다. 기본 Llama2-7b 구성은 Google Cloud의
a2-ultragpu-1g에서 약 1분 정도 소요됩니다.빠른 시작
-
아직 Launch 큐가 없다면 Launch 큐를 생성하세요. 아래에서 큐 설정 예시를 확인할 수 있습니다.
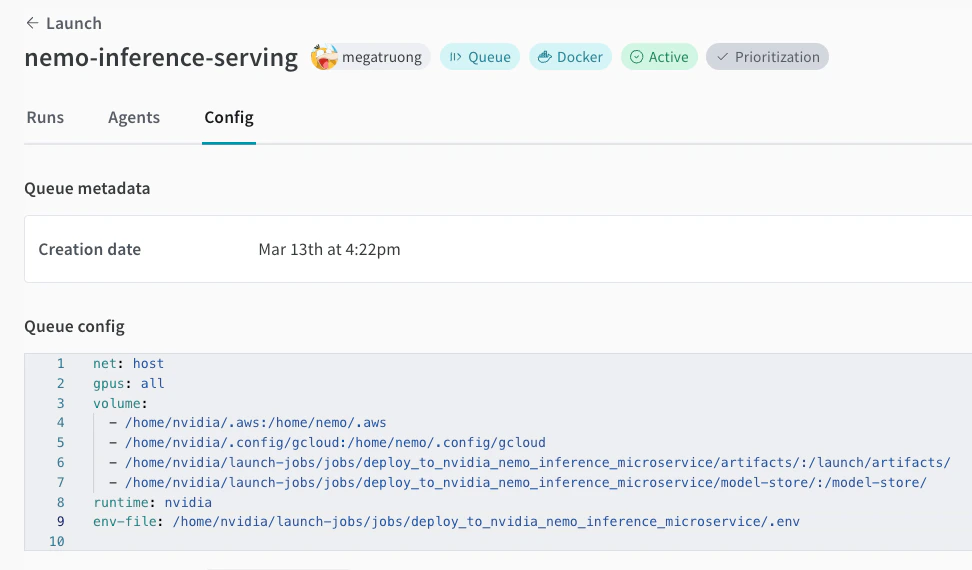
-
프로젝트에 다음 job을 생성합니다:
-
GPU 머신에서 agent를 실행합니다:
-
Launch UI에서 원하는 설정으로 배포용 Launch job을 제출합니다.
- CLI를 통해 제출할 수도 있습니다:
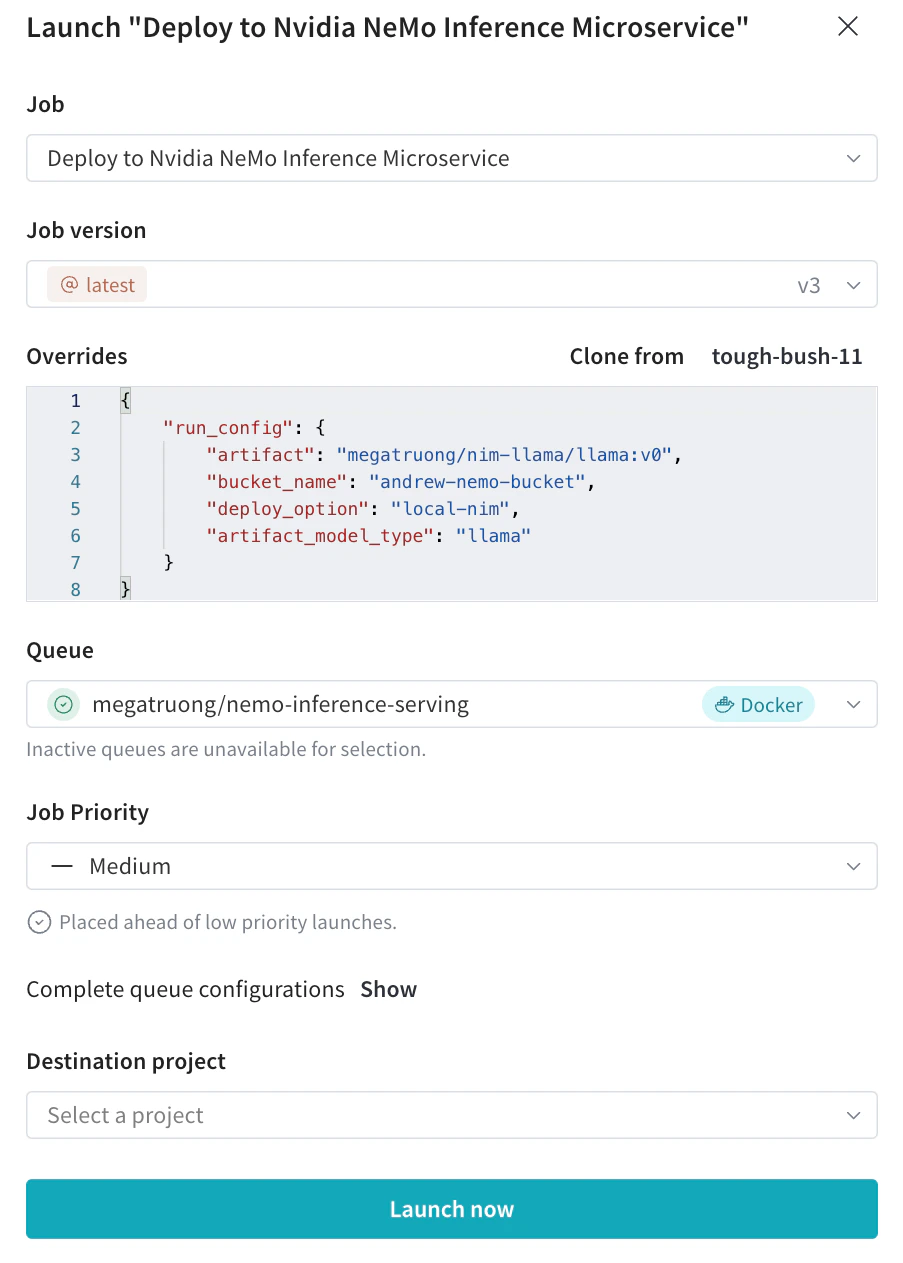
- CLI를 통해 제출할 수도 있습니다:
-
Launch UI에서 배포 진행 상황을 추적할 수 있습니다.
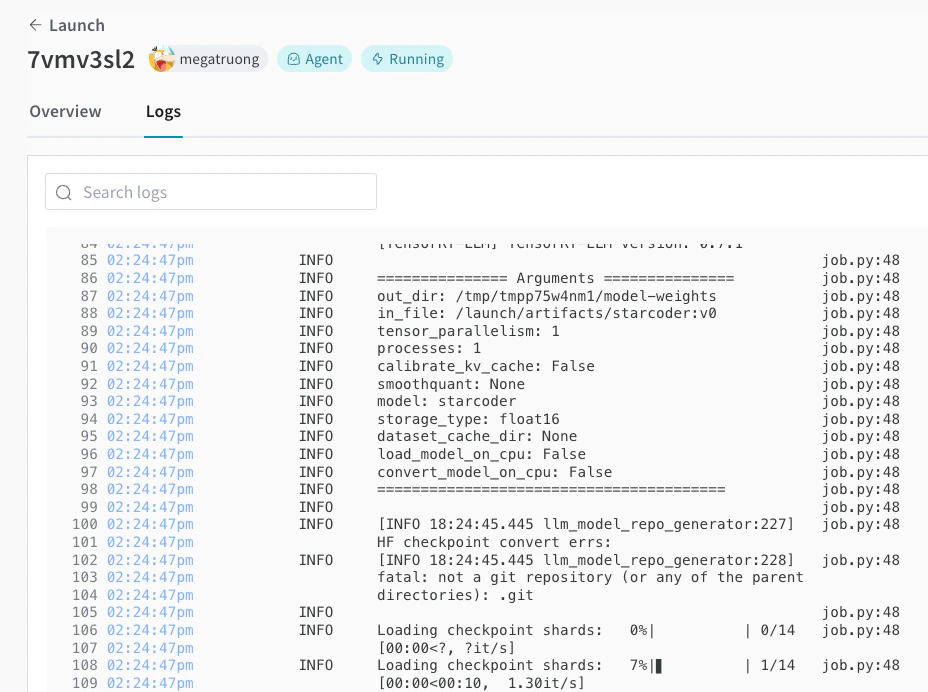
-
완료되면 즉시 엔드포인트에 curl 요청을 보내 모델을 테스트할 수 있습니다. 모델 이름은 항상
ensemble입니다.