Weave에서 Scorer는 AI 출력을 평가하고 평가 지표를 반환하는 데 사용됩니다. Scorer는 AI의 출력을 입력으로 받아 이를 분석한 뒤 결과 딕셔너리를 반환합니다. 필요하다면 입력 데이터를 참조로 사용할 수 있으며, 평가 과정에 대한 설명이나 추론 같은 추가 정보를 함께 반환할 수도 있습니다.Documentation Index
Fetch the complete documentation index at: https://translations.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
- Python
- TypeScript
Scorer는 평가 시
weave.Evaluation 객체에 전달됩니다. Weave에는 두 가지 유형의 Scorer가 있습니다:- 함수 기반 Scorer:
@weave.op으로 데코레이팅된 단순 Python 함수. - 클래스 기반 Scorer: 더 복잡한 평가를 위해
weave.Scorer를 상속하는 Python 클래스.
나만의 Scorer 만들기
함수 기반 Scorer
- Python
- TypeScript
@weave.op 데코레이터가 적용된, 딕셔너리를 반환하는 함수입니다. 다음과 같은 간단한 평가에 적합합니다:evaluate_uppercase가 텍스트가 모두 대문자인지 검사합니다.클래스 기반 Scorer
- Python
- TypeScript
더 고급 평가가 필요하거나, 추가적인 scorer 메타데이터를 추적해야 하거나, LLM 평가자에 대해 서로 다른 프롬프트를 시도하거나, 여러 번 함수 호출을 해야 하는 경우에는 이 클래스는 원문과 비교하여 요약 품질이 얼마나 좋은지 평가합니다.
Scorer 클래스를 사용할 수 있습니다.요구 사항:weave.Scorer를 상속합니다.@weave.op데코레이터가 붙은score메서드를 정의합니다.score메서드는 반드시 딕셔너리를 반환해야 합니다.
Scorer의 동작 방식
Scorer 키워드 인자
- Python
- TypeScript
Scorer는 AI 시스템의 출력과 데이터셋 행의 입력 데이터를 모두 사용할 수 있습니다.Weave
때때로 이제
- 입력(Input): Scorer에서 데이터셋 행의
"label"또는"target"같은 컬럼 데이터를 사용하고 싶다면, scorer 정의에label또는target키워드 인자를 추가해 쉽게 사용할 수 있습니다.
"label"이라는 컬럼을 사용하고 싶다면, scorer 함수(또는 score 클래스 메서드)의 매개변수 목록은 다음과 같이 정의할 수 있습니다:Evaluation이 실행될 때, AI 시스템의 출력은 output 매개변수로 전달됩니다. Evaluation은 추가로 정의된 scorer 인자 이름을 데이터셋의 컬럼 이름과 자동으로 매칭하려고 시도합니다. Scorer 인자나 데이터셋 컬럼 이름을 변경하기 어렵다면, 컬럼 매핑을 사용할 수 있습니다. 자세한 내용은 아래를 참고하세요.- 출력(Output): AI 시스템의 출력을 사용하려면, scorer 함수 시그니처에
output매개변수를 포함하세요.
column_map으로 컬럼 이름 매핑하기
때때로 score 메서드의 인자 이름이 데이터셋의 컬럼 이름과 일치하지 않을 수 있습니다. 이 경우 column_map을 사용해 해결할 수 있습니다.클래스 기반 scorer를 사용하는 경우, scorer 클래스를 초기화할 때 Scorer의 column_map 속성에 딕셔너리를 전달하세요. 이 딕셔너리는 {scorer_keyword_argument: dataset_column_name} 형태로, score 메서드의 인자 이름을 데이터셋 컬럼 이름에 매핑합니다.예시:score 메서드의 text 인자는 news_article 데이터셋 컬럼의 값을 받게 됩니다.참고:- 컬럼을 매핑하는 또 다른 동등한 방법은
Scorer를 상속받아score메서드를 오버로드하면서 컬럼 매핑을 명시적으로 수행하는 것입니다.
scoring 프롬프트에서 op의 변수에 접근하기
| 변수 | 설명 |
|---|---|
{article} | 입력 인수 article의 값 |
{max_length} | 입력 인수 max_length의 값 |
{inputs} | 모든 입력 인수를 포함하는 JSON 딕셔너리 |
{output} | 사용 중인 op가 반환한 결과 |
점수 산출기의 최종 요약
- Python
- TypeScript
평가 중에는 데이터셋의 각 행마다 점수 산출기가 계산됩니다. 평가에 대한 최종 점수를 제공하기 위해, 점수 출력 타입에 따라 동작하는
auto_summarize를 제공합니다.- 수치형 열에는 평균을 계산합니다.
- 불리언 열에는 개수와 비율을 계산합니다.
- 그 외 타입의 열은 무시됩니다.
Scorer 클래스에서 summarize 메서드를 오버라이드하여 최종 점수를 계산하는 방식을 직접 정의할 수 있습니다. summarize 함수는 다음을 인수로 받습니다.- 단일 파라미터
score_rows: 딕셔너리들의 리스트이며, 각 딕셔너리는 데이터셋의 한 행에 대해score메서드가 반환한 점수를 포함합니다. - 이 함수는 요약된 점수를 담은 딕셔너리를 반환해야 합니다.
이 예시에서 기본 auto_summarize는 True의 개수와 비율을 반환했을 것입니다.
자세한 내용은 CorrectnessLLMJudge의 구현을 참고하세요.호출에 Scorer 적용하기
.call() 메서드를 사용해야 합니다. 이를 통해 Weave 데이터베이스에서 특정 호출과 scorer 결과를 연결할 수 있습니다.
.call() 메서드 사용 방법에 대한 자세한 내용은 op 호출하기 가이드를 참고하세요.
- Python
- TypeScript
기본 예시는 다음과 같습니다:동일한 호출에 여러 scorer를 적용할 수도 있습니다:참고 사항:
- scorer 결과는 Weave 데이터베이스에 자동으로 저장됩니다.
- scorer는 메인 연산이 완료된 후 비동기적으로 실행됩니다.
- UI에서 scorer 결과를 확인하거나 API를 통해 조회할 수 있습니다.
preprocess_model_input 사용하기
preprocess_model_input 매개변수를 사용할 수 있습니다.
사용 방법과 예시는 평가 전에 데이터셋 행을 포맷하기 위해 preprocess_model_input 사용하기를 참고하세요.
점수 분석
단일 호출의 점수 분석
단일 Call API
get_call 메서드를 사용합니다.
단일 Call UI
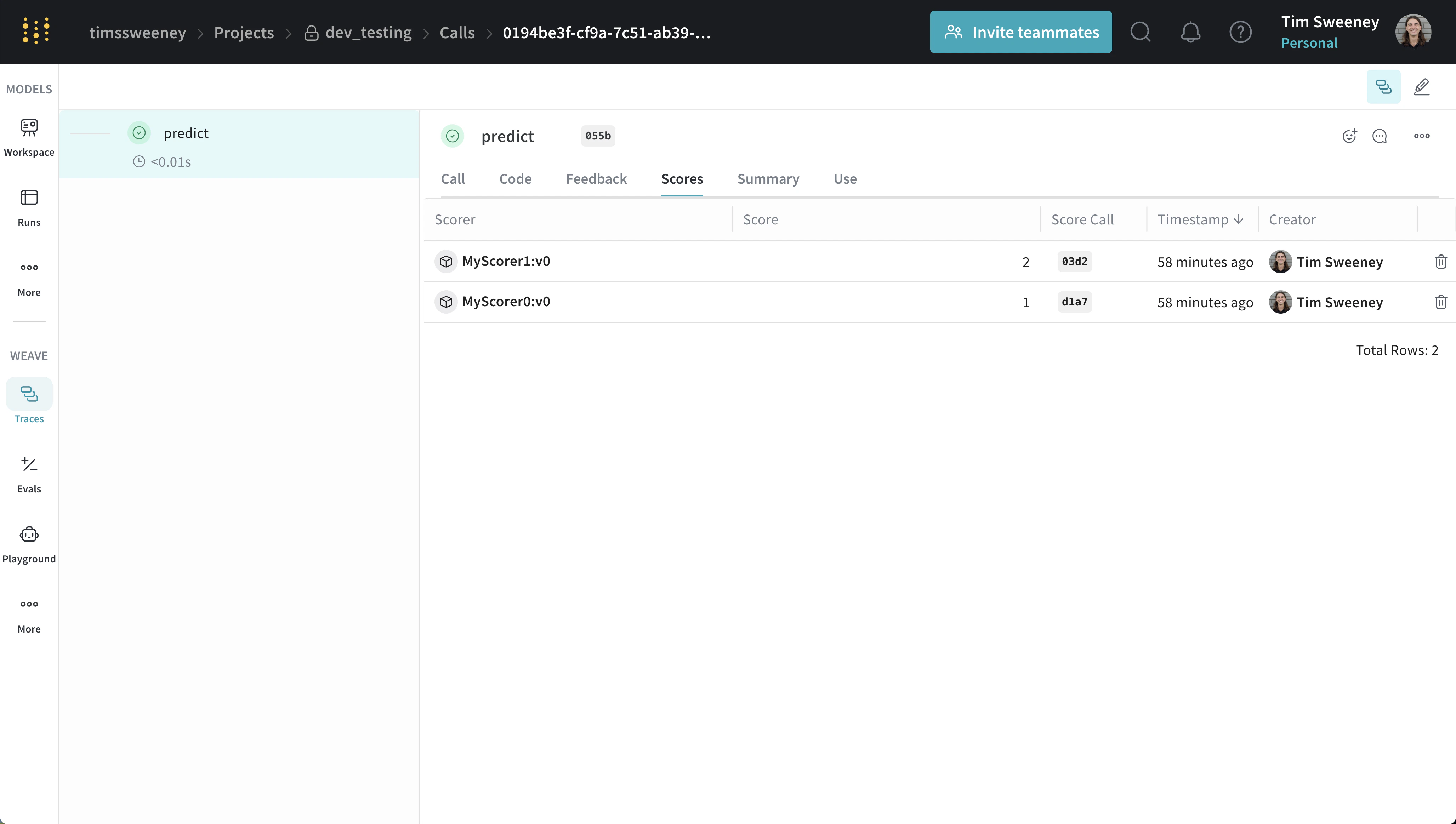
여러 Call의 점수 분석
여러 Call API
get_calls 메서드를 사용하세요.
다중 호출 UI
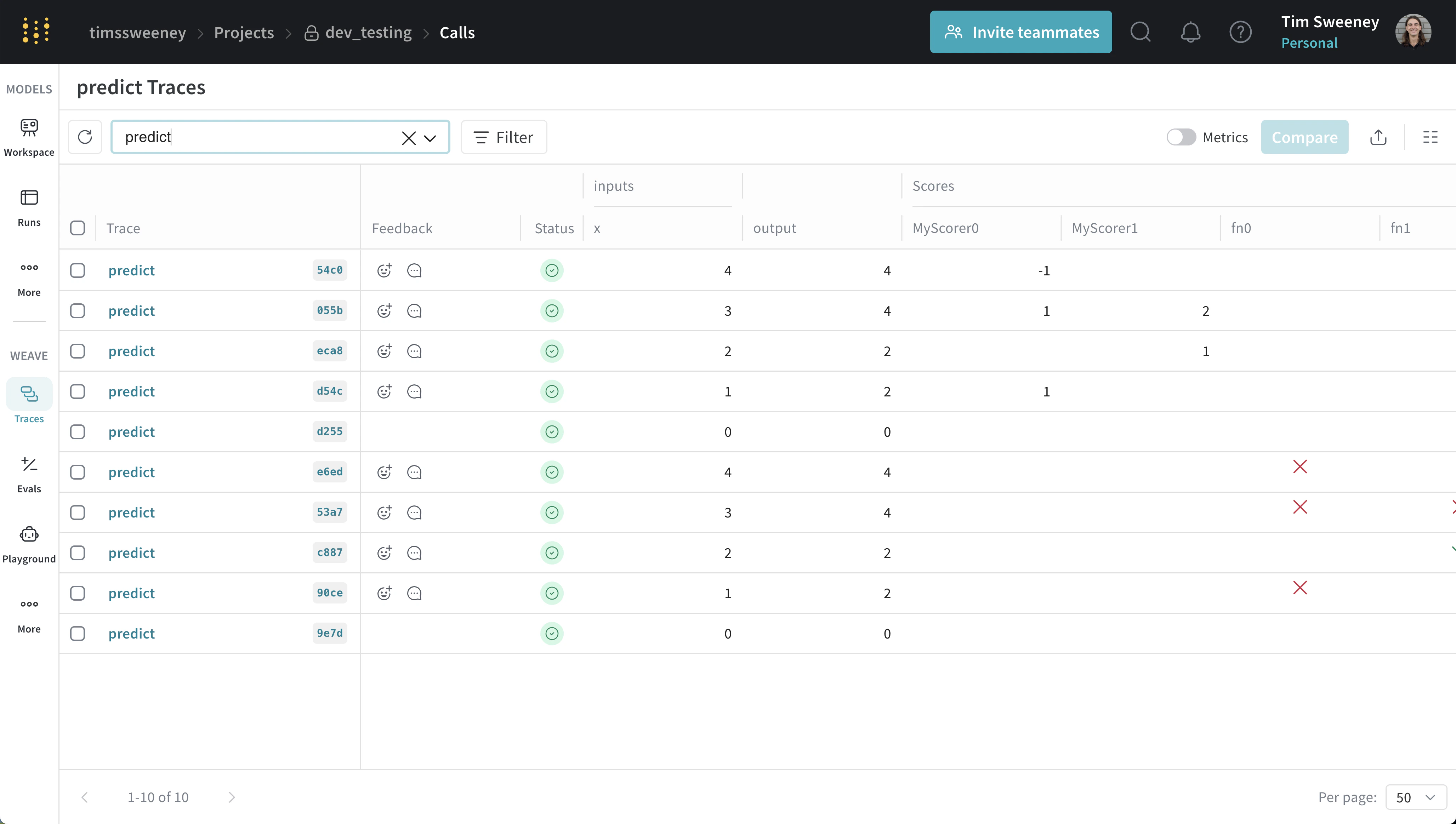
특정 Scorer가 채점한 모든 Call 분석
특정 Scorer가 채점한 모든 Call API
get_calls 메서드를 사용하십시오.
Scorer별 전체 콜 UI
Scores 아래의 View Traces 버튼을 클릭하여 해당 Scorer가 채점한 모든 콜을 확인합니다.