이 노트북에서는 PyTorch 코드에 W&B를 통합하여 파이프라인에 실험 추적 기능을 추가하는 방법을 설명합니다.
# 라이브러리를 import 합니다.import wandb# config로 하이퍼파라미터 딕셔너리를 설정합니다.config = { "learning_rate": 0.001, "epochs": 100, "batch_size": 128}# 새로운 실행을 시작합니다.with wandb.init(project="new-sota-model", config=config) as run: # 모델과 데이터를 준비합니다. model, dataloader = get_model(), get_data() # 선택 사항: 그래디언트를 추적합니다. run.watch(model) for batch in dataloader: metrics = model.training_step() # 모델 성능을 시각화할 수 있도록 학습 루프 안에서 지표를 로그로 남깁니다. run.log(metrics) # 선택 사항: 마지막에 모델을 저장합니다. model.to_onnx() run.save("model.onnx")
비디오 튜토리얼을 보면서 따라오세요.참고: Step으로 시작하는 섹션만 보면 기존 파이프라인에 W&B를 통합하는 데 충분합니다. 나머지는 데이터를 로드하고 모델을 정의하는 내용입니다.
프로그램적으로 우리가 가장 먼저 하는 일은 실험을 정의하는 것입니다:
하이퍼파라미터는 무엇인지, 이 실행에는 어떤 메타데이터가 연결되는지 정합니다.이 정보를 config 딕셔너리(또는 유사한 객체)에 저장해 두고
필요할 때 꺼내 쓰는 워크플로우가 매우 일반적입니다.이 예제에서는 소수의 하이퍼파라미터만 변경 가능하게 두고
나머지는 코드에 직접 정의합니다.
하지만 모델의 어떤 부분이든 config에 포함될 수 있습니다.또한 일부 메타데이터도 포함합니다: 우리는 MNIST 데이터셋과 합성곱
아키텍처를 사용하고 있습니다. 나중에 같은 프로젝트에서, 예를 들어
CIFAR 데이터셋에 대해 완전 연결 아키텍처로 작업할 경우,
이 메타데이터가 서로 다른 실행을 구분하는 데 도움이 됩니다.
def model_pipeline(hyperparameters): # wandb 시작 with wandb.init(project="pytorch-demo", config=hyperparameters) as run: # run.config를 통해 모든 하이퍼파라미터에 접근하여 로깅이 실행과 일치하도록 함. config = run.config # 모델, 데이터, 최적화 문제 생성 model, train_loader, test_loader, criterion, optimizer = make(config) print(model) # 이를 사용하여 모델 학습 train(model, train_loader, criterion, optimizer, config) # 최종 성능 테스트 test(model, test_loader) return model
여기에서 표준 파이프라인과의 유일한 차이는
모든 것이 wandb.init 컨텍스트 안에서 일어난다는 점입니다.
이 함수를 호출하면
여러분의 코드와 저희 서버 사이에 통신이 설정됩니다.config 딕셔너리를 wandb.init에 전달하면
그 모든 정보가 즉시 저희 쪽에 기록되므로,
실험에서 사용하도록 설정한 하이퍼파라미터 값들을
항상 확인할 수 있습니다.선택하고 기록한 값이 모델에서 실제로 사용되는 값과 항상 일치하도록 하려면,
객체의 run.config 사본을 사용할 것을 권장합니다.
아래의 make 정의를 확인해 예시를 살펴보세요.
추가 설명: 저희 코드는 별도의 프로세스에서 실행되도록 주의 깊게 설계되어 있어서
저희 쪽 문제
(예: 거대한 바다 괴물이 데이터 센터를 공격하는 경우와 같은 상황)로 인해
여러분의 코드에서 크래시가 발생하지 않도록 합니다.
문제가 해결되고, 예를 들어 크라켄이 심해로 돌아간 뒤에는
wandb sync로 데이터를 동기화할 수 있습니다.
def make(config): # 데이터 생성 train, test = get_data(train=True), get_data(train=False) train_loader = make_loader(train, batch_size=config.batch_size) test_loader = make_loader(test, batch_size=config.batch_size) # 모델 생성 model = ConvNet(config.kernels, config.classes).to(device) # 손실 함수 및 옵티마이저 생성 criterion = nn.CrossEntropyLoss() optimizer = torch.optim.Adam( model.parameters(), lr=config.learning_rate) return model, train_loader, test_loader, criterion, optimizer
모델을 정의하는 과정은 보통 가장 재미있는 부분입니다.하지만 wandb 때문에 특별히 바뀌는 건 없으니,
여기서는 표준적인 ConvNet 아키텍처를 그대로 사용하겠습니다.이 부분을 마음껏 바꿔 보면서 여러 실험을 시도해 보세요 —
모든 결과는 wandb.ai에 기록됩니다.
# 일반 및 합성곱 신경망class ConvNet(nn.Module): def __init__(self, kernels, classes=10): super(ConvNet, self).__init__() self.layer1 = nn.Sequential( nn.Conv2d(1, kernels[0], kernel_size=5, stride=1, padding=2), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.layer2 = nn.Sequential( nn.Conv2d(16, kernels[1], kernel_size=5, stride=1, padding=2), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2)) self.fc = nn.Linear(7 * 7 * kernels[-1], classes) def forward(self, x): out = self.layer1(x) out = self.layer2(out) out = out.reshape(out.size(0), -1) out = self.fc(out) return out
run.watch는 학습 중 매 log_freq 스텝마다
모델의 그래디언트와 파라미터를 기록합니다.학습을 시작하기 전에 run.watch()만 한 번 호출하면 됩니다.나머지 학습 코드는 그대로입니다:
에포크와 배치를 순회하면서
순전파와 역전파를 실행하고
optimizer를 적용합니다.
def train(model, loader, criterion, optimizer, config): # wandb가 모델의 그래디언트, 가중치 등을 추적하도록 설정합니다. run = wandb.init(project="pytorch-demo", config=config) run.watch(model, criterion, log="all", log_freq=10) # 학습을 실행하고 wandb로 추적합니다 total_batches = len(loader) * config.epochs example_ct = 0 # 처리된 예제 수 batch_ct = 0 for epoch in tqdm(range(config.epochs)): for _, (images, labels) in enumerate(loader): loss = train_batch(images, labels, model, optimizer, criterion) example_ct += len(images) batch_ct += 1 # 25번째 배치마다 메트릭 보고 if ((batch_ct + 1) % 25) == 0: train_log(loss, example_ct, epoch)def train_batch(images, labels, model, optimizer, criterion): images, labels = images.to(device), labels.to(device) # 순전파 ➡ outputs = model(images) loss = criterion(outputs, labels) # 역전파 ⬅ optimizer.zero_grad() loss.backward() # 옵티마이저 스텝 실행 optimizer.step() return loss
유일한 차이점은 로깅 코드에 있습니다.
이전에 터미널에 출력해서 지표를 확인했다면,
이제는 동일한 정보를 run.log()에 전달하면 됩니다.run.log()는 key가 문자열인 딕셔너리를 인자로 받습니다.
이 문자열은 로깅되는 객체를 식별하며, 해당 객체들이 value가 됩니다.
또한 선택적으로, 현재 학습이 몇 번째 step인지도 함께 기록할 수 있습니다.
추가 참고: 저는 모델이 지금까지 본 예제(example) 수를 사용하는 편입니다.
이렇게 하면 배치 크기가 달라져도 비교가 더 쉽기 때문입니다.
물론 원시 step 수나 배치 개수를 사용해도 됩니다. 학습이 오래 진행되는 경우에는 epoch 단위로 로깅하는 것도 합리적일 수 있습니다.
def train_log(loss, example_ct, epoch): with wandb.init(project="pytorch-demo") as run: # loss와 epoch 번호를 기록합니다 # 여기서 W&B에 메트릭을 기록합니다 run.log({"epoch": epoch, "loss": loss}, step=example_ct) print(f"Loss after {str(example_ct).zfill(5)} examples: {loss:.3f}")
지금은 모델의 아키텍처와 최종 파라미터를 디스크에 저장하기에 좋은 시점이기도 합니다.
최대 호환성을 위해 모델을
Open Neural Network eXchange (ONNX) 형식으로 export하겠습니다.해당 파일 이름을 run.save()에 전달하면 모델 파라미터가 W&B 서버에 저장되어,
어떤 .h5 또는 .pb 파일이 어떤 학습 실행과 대응되는지 헷갈릴 일이 없습니다.모델을 저장, 버저닝, 배포하기 위한 더 고급 wandb 기능은
아티팩트 도구를 참고하세요.
def test(model, test_loader): model.eval() with wandb.init(project="pytorch-demo") as run: # 일부 테스트 예제에서 모델 실행 with torch.no_grad(): correct, total = 0, 0 for images, labels in test_loader: images, labels = images.to(device), labels.to(device) outputs = model(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() print(f"Accuracy of the model on the {total} " + f"test images: {correct / total:%}") run.log({"test_accuracy": correct / total}) # 호환 가능한 ONNX 형식으로 모델 저장 torch.onnx.export(model, images, "model.onnx") run.save("model.onnx")
이제 전체 파이프라인을 정의했고
몇 줄의 W&B 코드를 추가했으니,
완전히 추적되는 실험을 실행할 준비가 되었습니다.몇 가지 링크가 출력됩니다:
문서 페이지,
프로젝트에 있는 모든 실행을 정리해 주는 Project 페이지, 그리고
이번 실행의 결과가 저장되는 Run 페이지입니다.Run 페이지로 이동해서 다음 탭들을 살펴보세요:
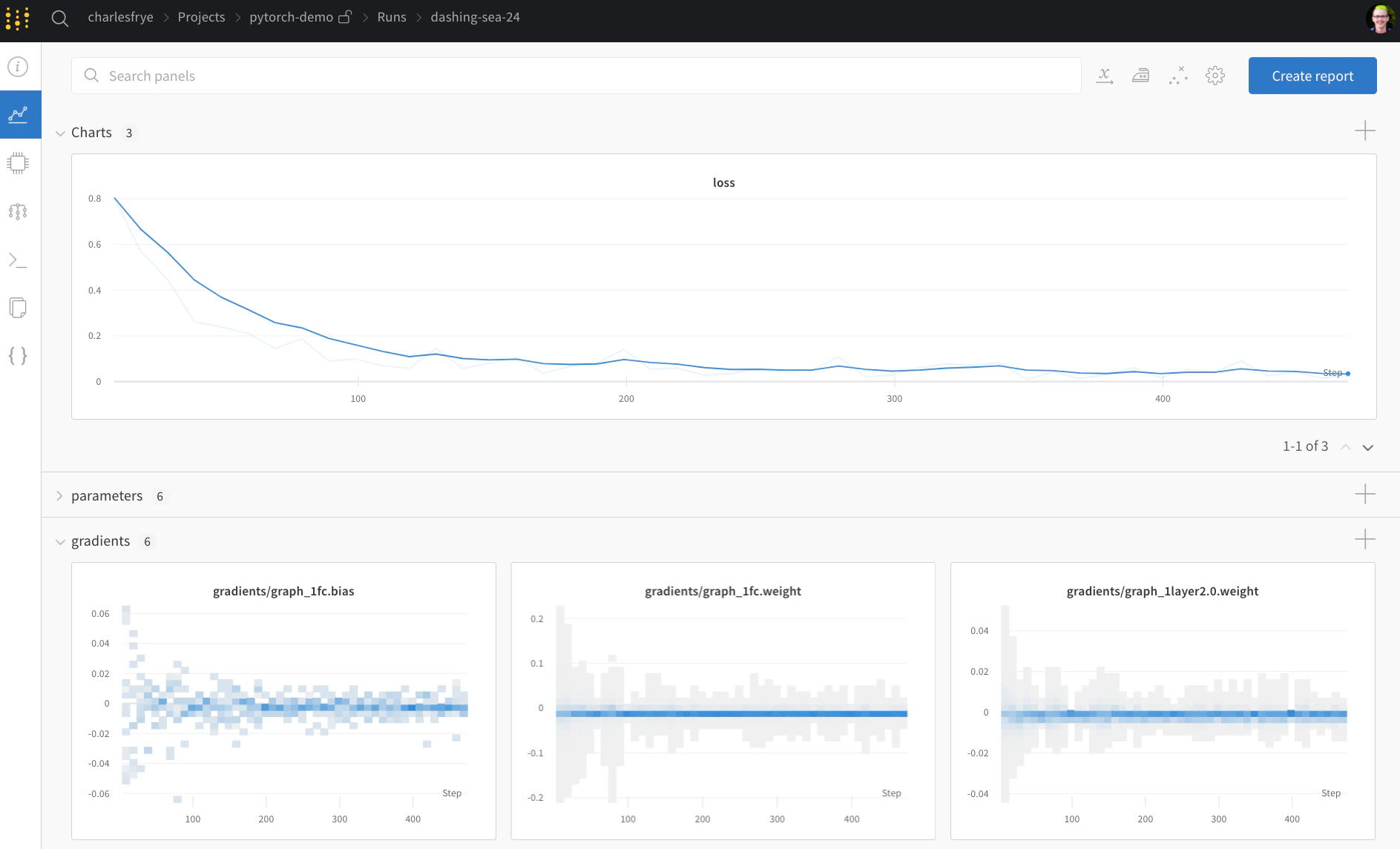
Charts 탭: 훈련 내내 모델 기울기, 파라미터 값, 손실이 기록됩니다.
System 탭: 디스크 I/O 사용량, CPU 및 GPU 메트릭(온도가 얼마나 올라가는지 확인해 보세요) 등 다양한 시스템 메트릭이 포함됩니다.
이 예제에서는 하나의 하이퍼파라미터 설정만 살펴보았습니다.
하지만 대부분의 ML 워크플로에서 중요한 부분은
여러 하이퍼파라미터 조합을 반복적으로 실험해 보는 것입니다.W&B Sweeps를 사용하면 하이퍼파라미터 테스트를 자동화하고, 가능한 모델과 최적화 전략의 공간을 효율적으로 탐색할 수 있습니다.W&B Sweeps를 사용한 하이퍼파라미터 최적화를 보여주는 Colab 노트북을 확인하세요.W&B에서 하이퍼파라미터 sweep을 실행하는 것은 매우 쉽습니다. 다음 3단계만 수행하면 됩니다:
sweep 정의: 탐색할 하이퍼파라미터, 검색 전략, 최적화 지표 등을 지정하는 딕셔너리 또는 YAML 파일을 생성합니다.