Use this file to discover all available pages before exploring further.
Colab에서 실행해 보기W&B를 사용해 머신러닝 실험 추적, 데이터셋 버전 관리, 그리고 프로젝트 협업을 수행하세요.
트리 기반 모델에서 최고의 성능을 끌어내려면
적절한 하이퍼파라미터를 선택해야 합니다.
early_stopping_rounds는 얼마로 설정해야 할까요? 트리의 max_depth는 어떻게 설정해야 할까요?최고의 성능을 내는 모델을 찾기 위해 고차원 하이퍼파라미터 공간을 탐색하는 작업은 매우 빠르게 감당하기 어려워질 수 있습니다.
하이퍼파라미터 sweep은 수많은 모델을 체계적이고 효율적으로 비교하여 최종 우승 모델을 선정하는 방법을 제공합니다.
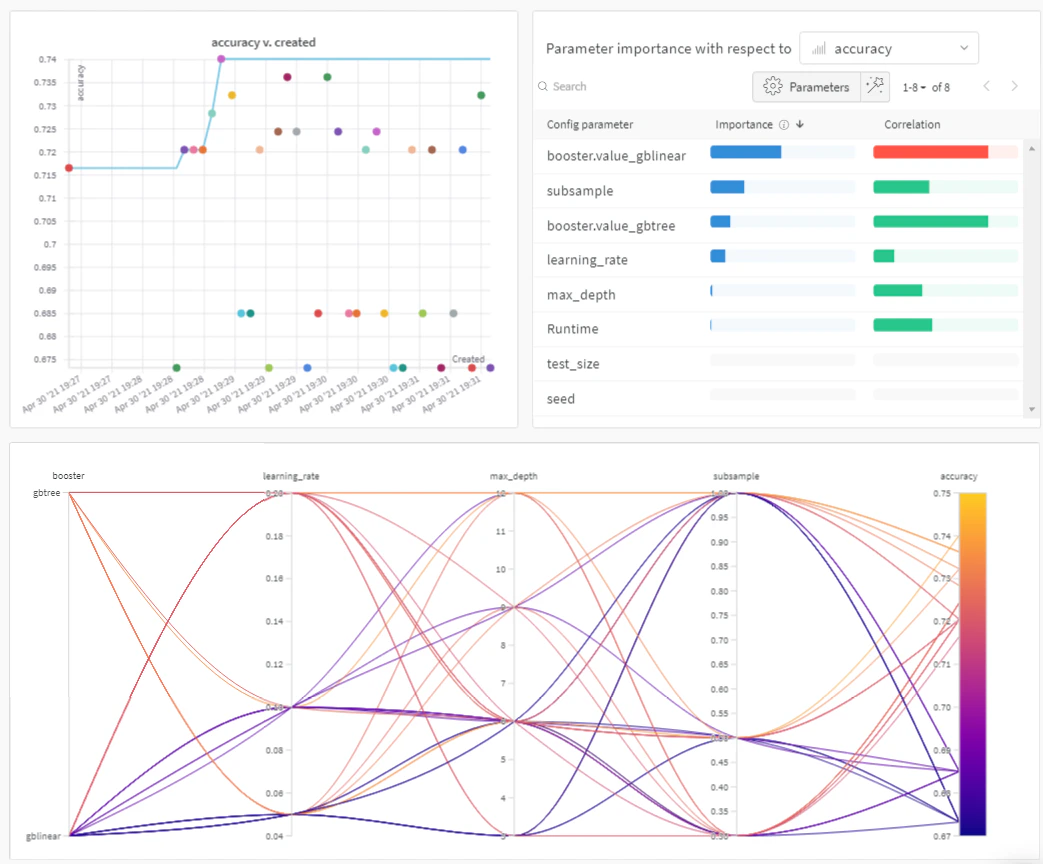
이는 하이퍼파라미터 값의 조합을 자동으로 탐색해 가장 최적의 값을 찾도록 함으로써 이루어집니다.이 튜토리얼에서는 W&B를 사용해 3단계만으로 XGBoost 모델에 대해 고급 하이퍼파라미터 sweep을 실행하는 방법을 알아봅니다.미리 보기로, 아래 그래프를 확인해 보세요:
W&B 스윕을 사용하면 몇 줄의 코드만으로 스윕을 원하는 대로 정확하게 구성할 수 있습니다. 스윕 구성(config)은
딕셔너리 또는 YAML 파일로 정의할 수 있습니다.이 중 일부를 함께 살펴보겠습니다:
Metric: 스윕이 최적화하려는 메트릭입니다. Metric은 name(학습 스크립트에서 로깅되어야 하는 메트릭 이름)과 goal(maximize 또는 minimize)을 가질 수 있습니다.
Search Strategy: "method" 키로 지정합니다. 스윕에서는 여러 가지 탐색 전략을 지원합니다.
Grid Search: 하이퍼파라미터 값의 모든 조합을 순회합니다.
Random Search: 무작위로 선택된 하이퍼파라미터 값 조합을 순회합니다.
Bayesian Search: 하이퍼파라미터를 메트릭 점수의 확률과 매핑하는 확률 모델을 만들고, 메트릭을 향상시킬 가능성이 높은 파라미터를 선택합니다. 베이지안 최적화의 목적은 시도하는 하이퍼파라미터 값의 수를 줄이는 대신, 어떤 하이퍼파라미터 값을 선택할지 결정하는 데 더 많은 리소스를 쓰는 것입니다.
Parameters: 하이퍼파라미터 이름과 이산 값, 범위, 또는 각 반복에서 값을 샘플링할 분포를 포함하는 딕셔너리입니다.
# Pima Indians 데이터셋을 위한 XGBoost 모델from numpy import loadtxtfrom xgboost import XGBClassifierfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import accuracy_score# 데이터 로드def train(): config_defaults = { "booster": "gbtree", "max_depth": 3, "learning_rate": 0.1, "subsample": 1, "seed": 117, "test_size": 0.33, } with wandb.init(config=config_defaults) as run: # sweep 실행 중 기본값이 재정의됨 config = run.config # 데이터를 로드하고 예측 변수와 타겟으로 분할 dataset = loadtxt("pima-indians-diabetes.data.csv", delimiter=",") X, Y = dataset[:, :8], dataset[:, 8] # 데이터를 학습 세트와 테스트 세트로 분할 X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=config.test_size, random_state=config.seed) # 학습 데이터로 모델 학습 model = XGBClassifier(booster=config.booster, max_depth=config.max_depth, learning_rate=config.learning_rate, subsample=config.subsample) model.fit(X_train, y_train) # 테스트 데이터로 예측 수행 y_pred = model.predict(X_test) predictions = [round(value) for value in y_pred] # 예측 결과 평가 accuracy = accuracy_score(y_test, predictions) print(f"Accuracy: {accuracy:.0%}") run.log({"accuracy": accuracy})
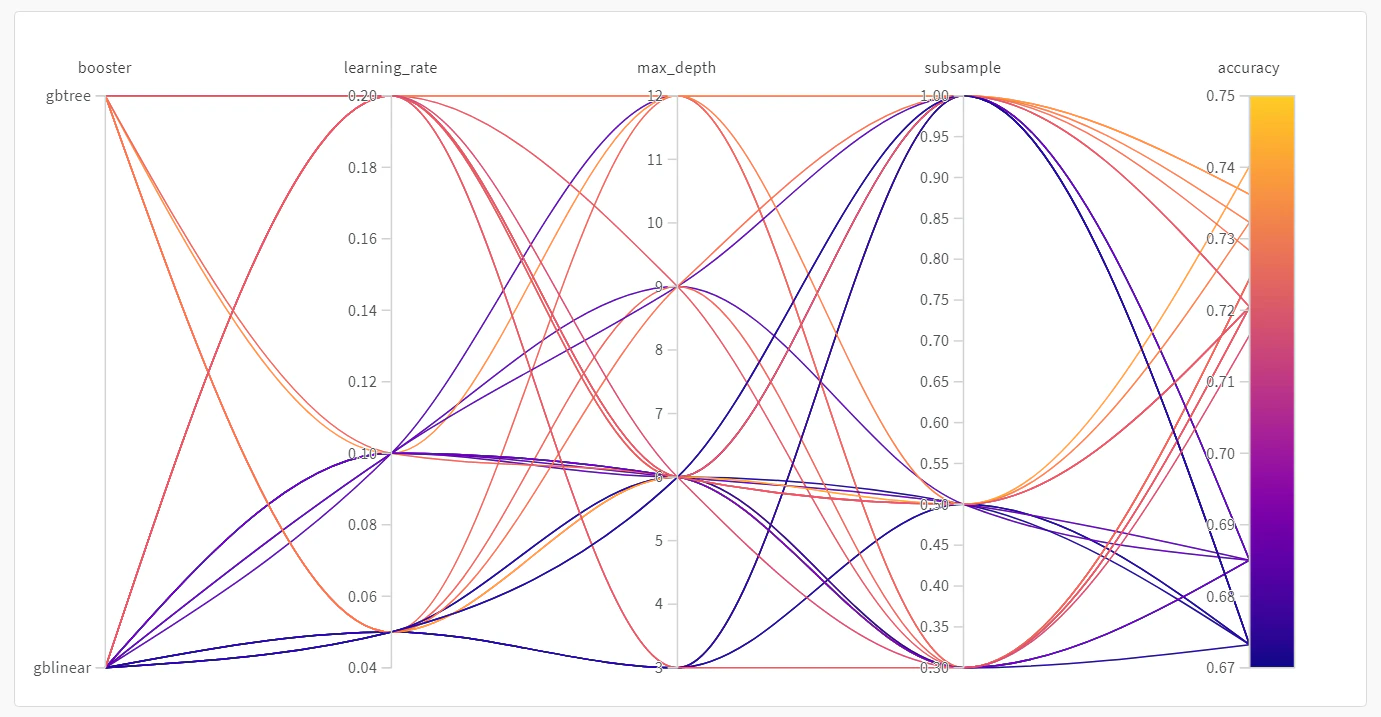
이 플롯은 하이퍼파라미터 값을 모델 지표에 매핑합니다. 최상의 모델 성능을 낳은 하이퍼파라미터 조합을 좁혀 나갈 때 유용합니다.이 플롯은 트리를 learner로 사용할 경우 단순 선형 모델을 learner로 사용할 때보다 약간,
하지만 극적인 차이는 아니게,
더 좋은 성능을 낸다는 것을 시사합니다.
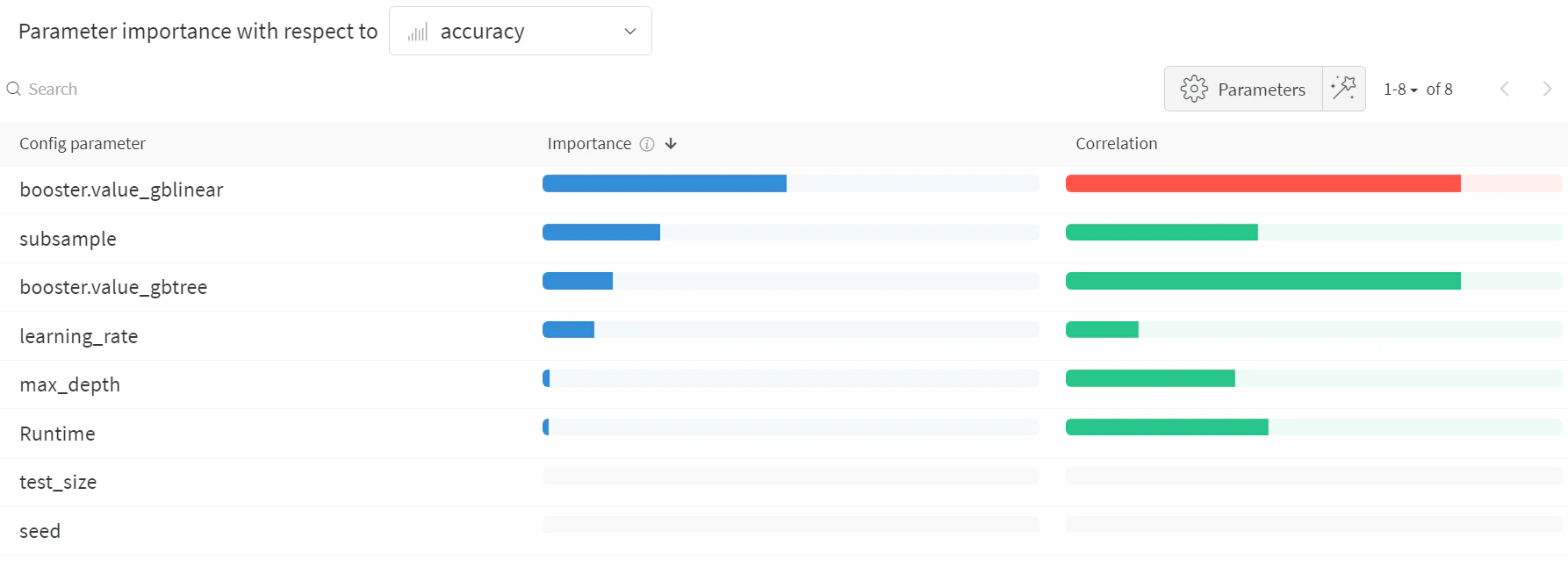
하이퍼파라미터 중요도 플롯은 어떤 하이퍼파라미터 값이
메트릭에 가장 큰 영향을 미쳤는지를 보여줍니다.상관관계(선형 예측 변수로 가정했을 때의 상관계수)와
특성 중요도(결과에 대해 random forest를 학습한 후 산출한 값)를 모두 제공하므로,
어떤 파라미터가 가장 큰 영향을 미쳤는지와
그 영향이 긍정적인지 부정적인지를 확인할 수 있습니다.이 차트를 통해 위의 병렬 좌표 차트에서 관찰한 추세를
정량적으로 확인할 수 있습니다.
검증 정확도에 가장 큰 영향을 준 것은 학습기(learner)의 선택이었고,
gblinear 학습기는 일반적으로 gbtree 학습기보다 성능이 떨어졌습니다.
이러한 시각화는 가장 중요한 파라미터(및 값 범위)에 집중함으로써,
고비용의 하이퍼파라미터 최적화를 수행하는 데 필요한 시간과 리소스를 절약하고,
추가적으로 탐색할 가치가 있는 파라미터를 좁히는 데 도움을 줍니다.