모델의 하이퍼파라미터 중 어떤 것이 지표의 바람직한 값과 가장 강하게 상관되며, 성능을 가장 잘 예측하는지 파악할 수 있습니다.Documentation Index
Fetch the complete documentation index at: https://translations.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
하이퍼파라미터 중요도 패널 생성하기
- W&B 프로젝트로 이동합니다.
- Add panels 버튼을 클릭합니다.
- CHARTS 드롭다운을 펼친 뒤, Parallel coordinates를 선택합니다.
빈 패널이 나타나면 실행이 그룹 해제(ungrouped) 상태인지 확인하세요.
하이퍼파라미터 중요도 패널 해석하기
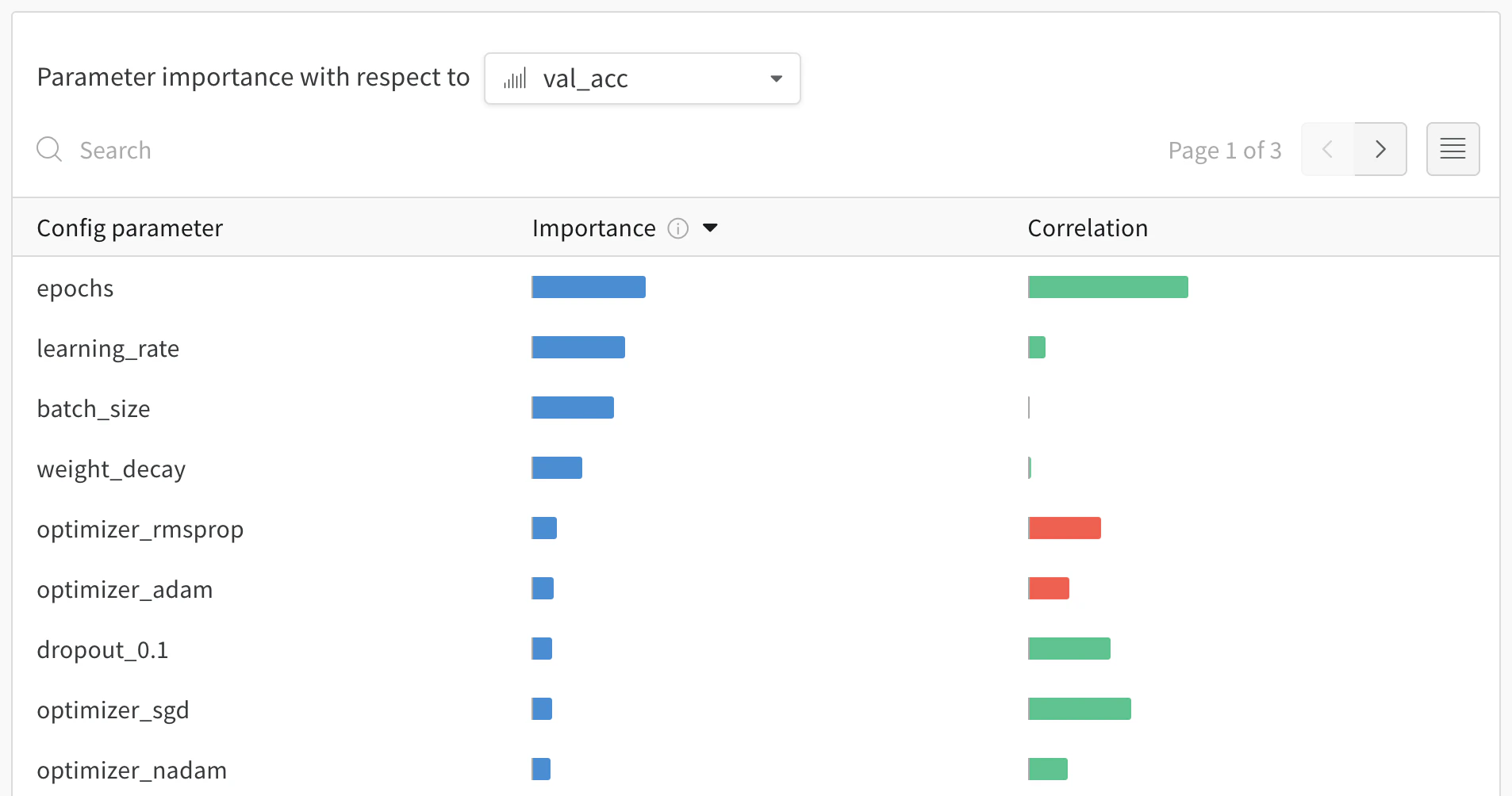
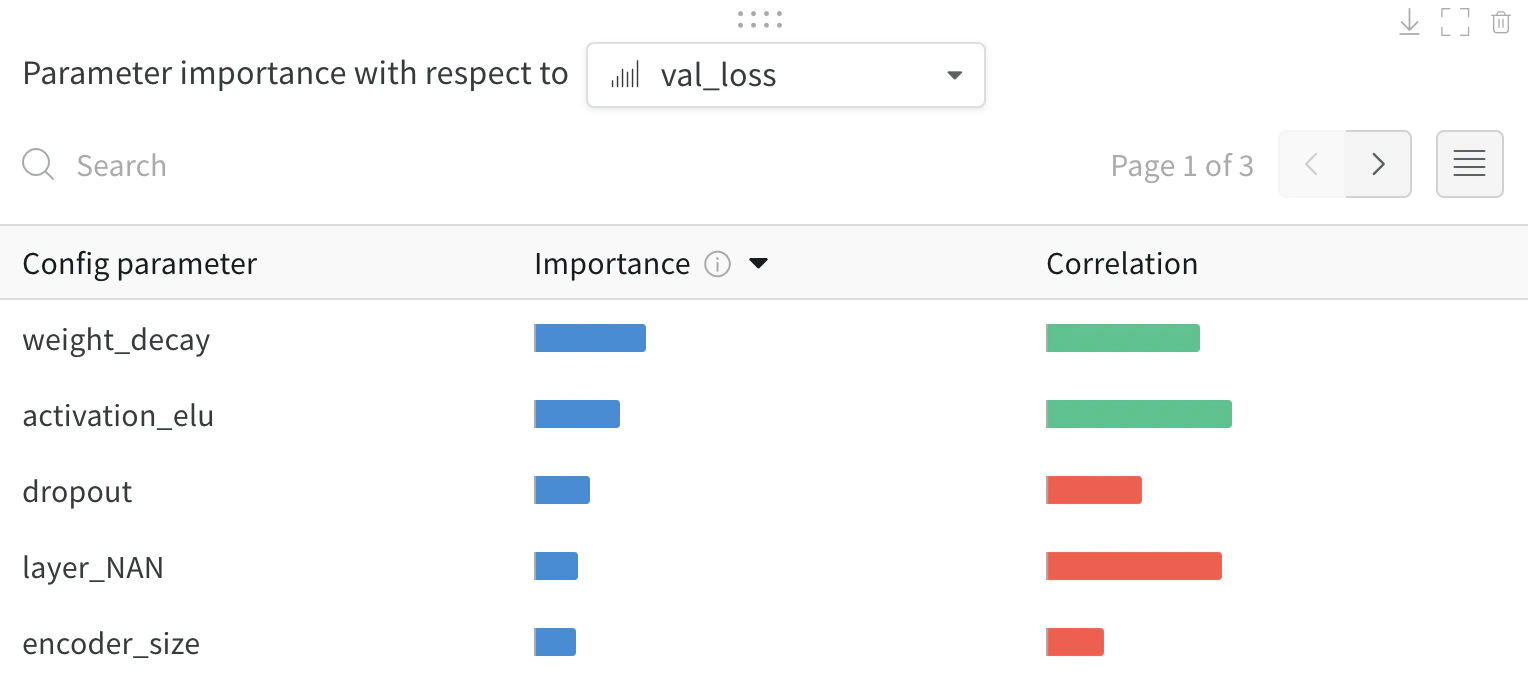
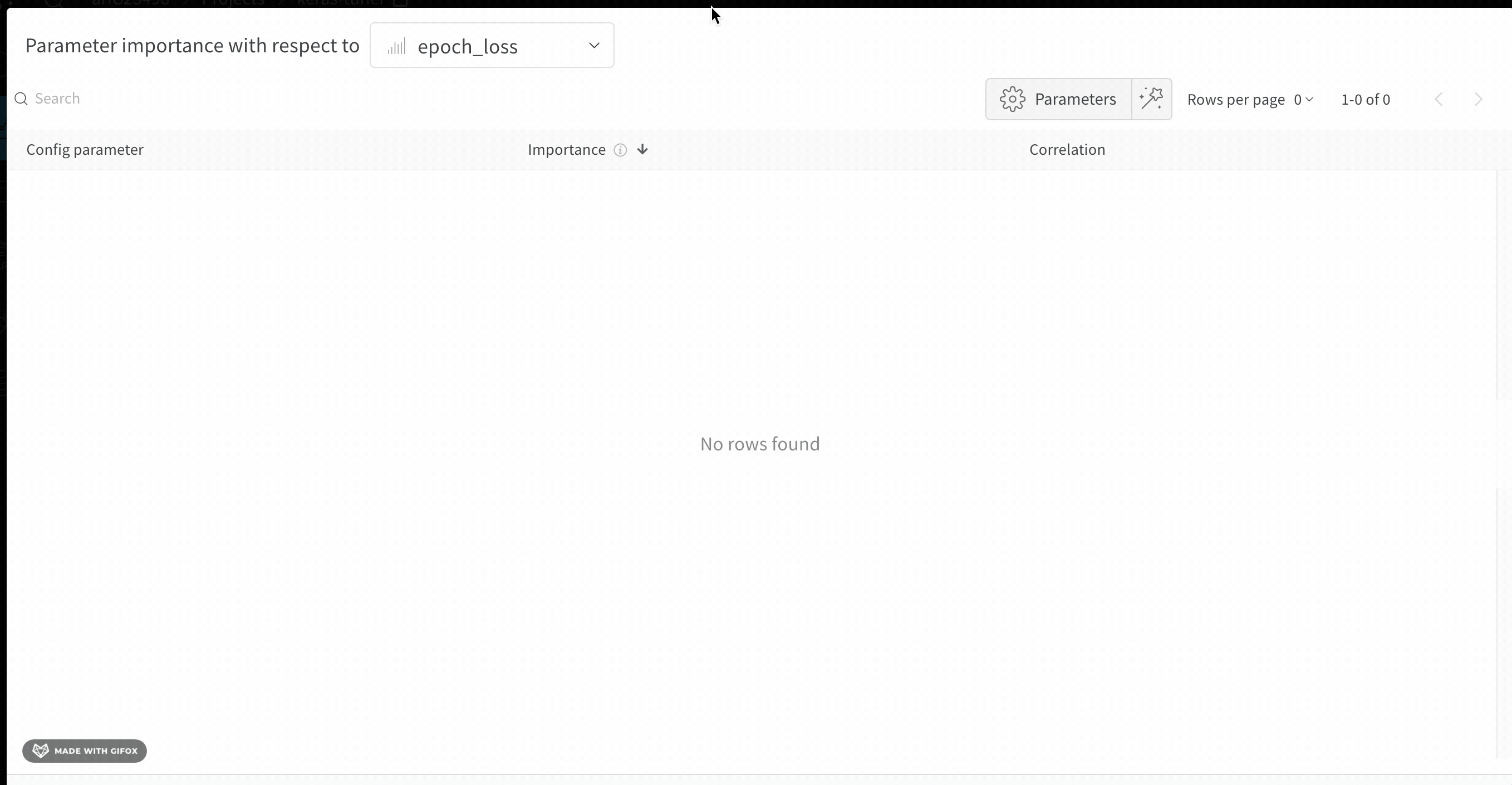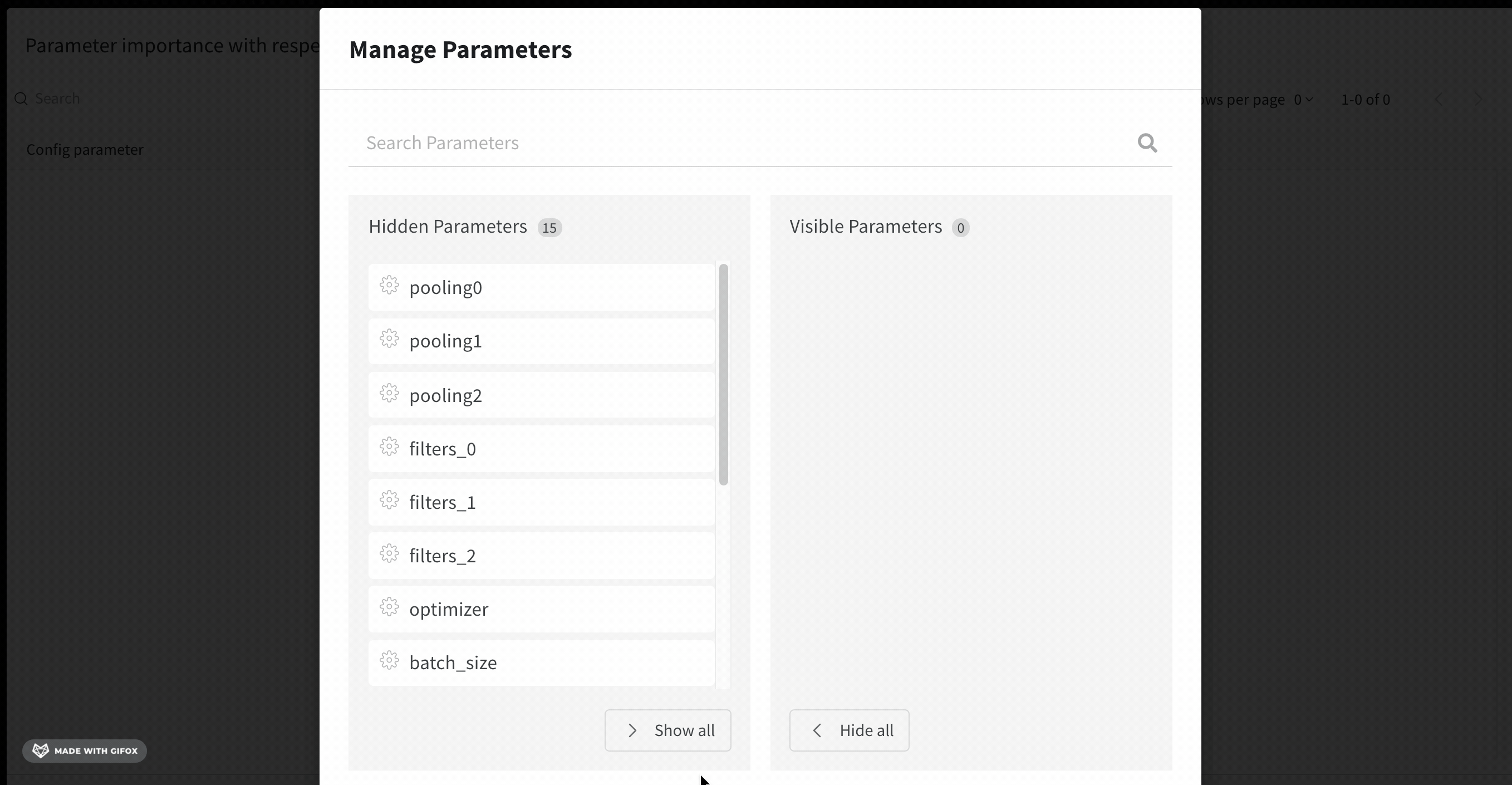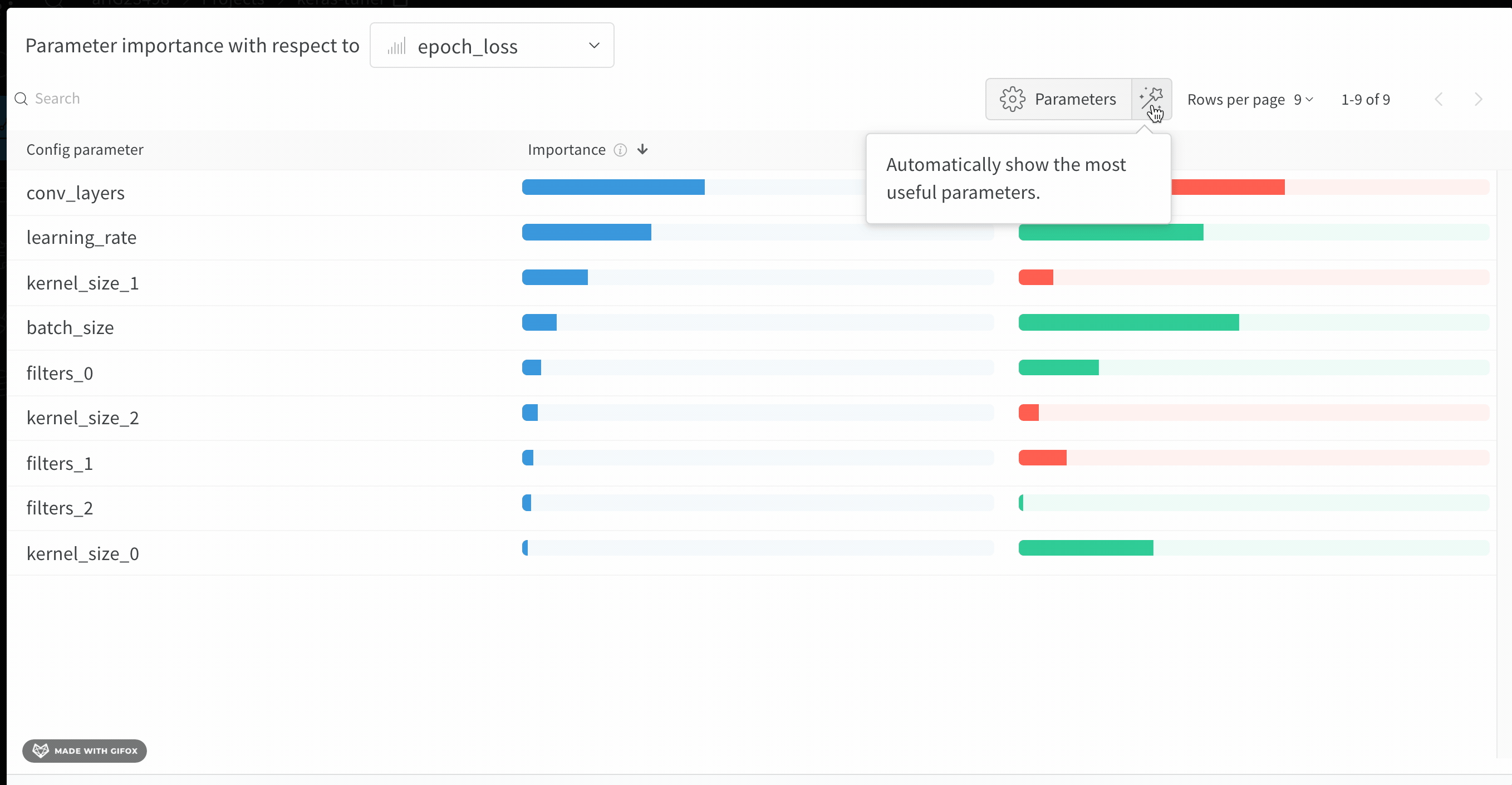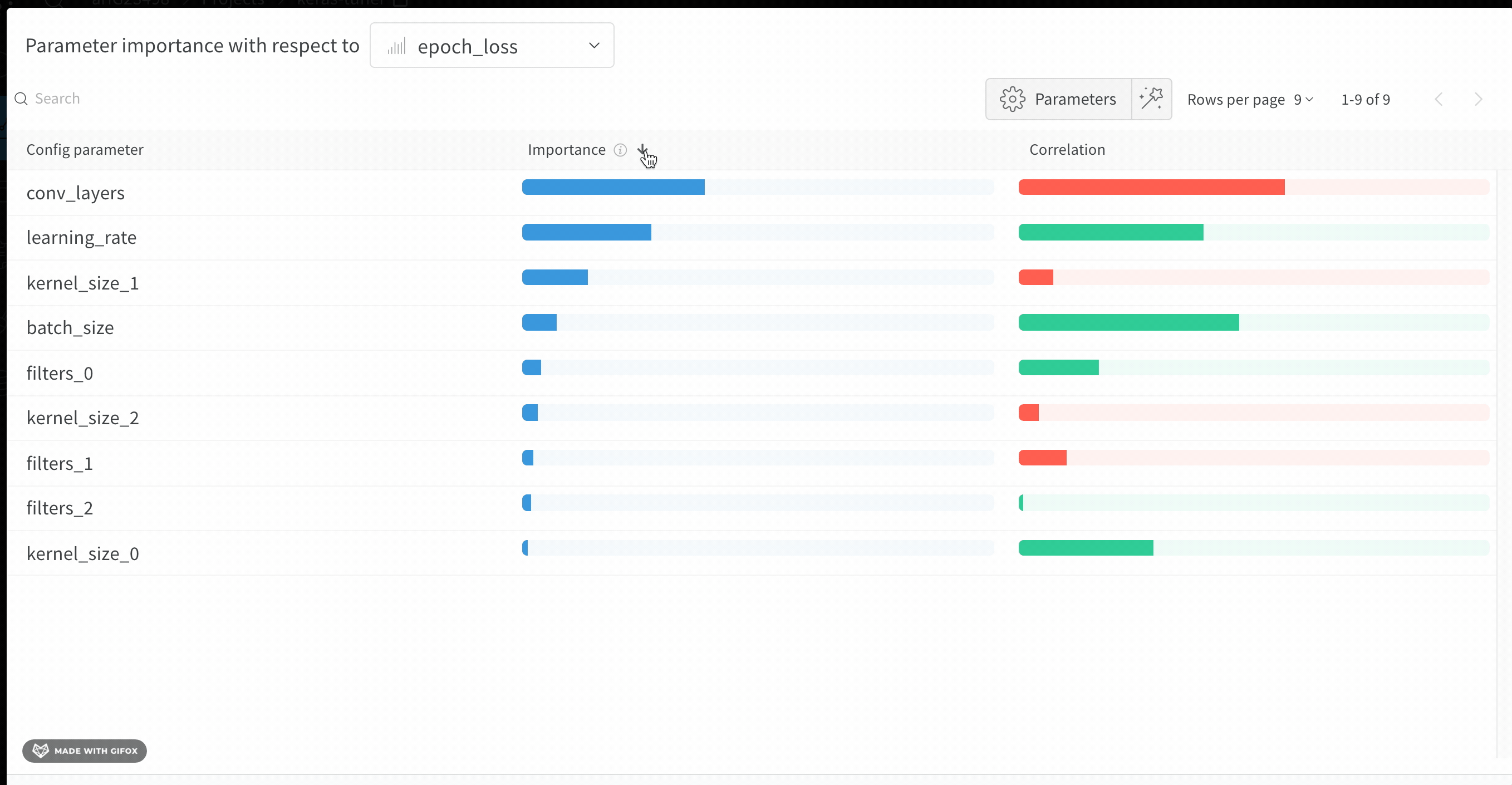
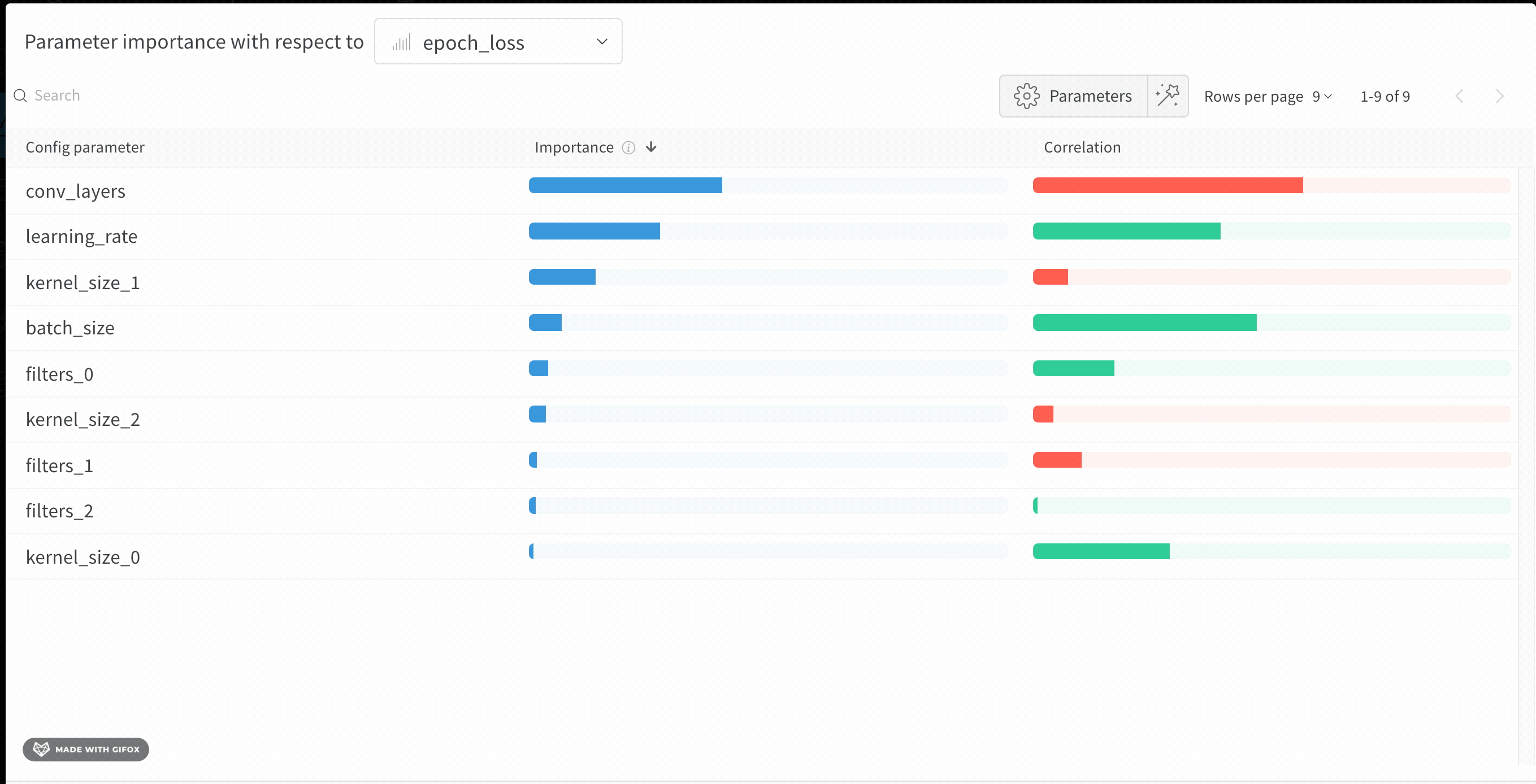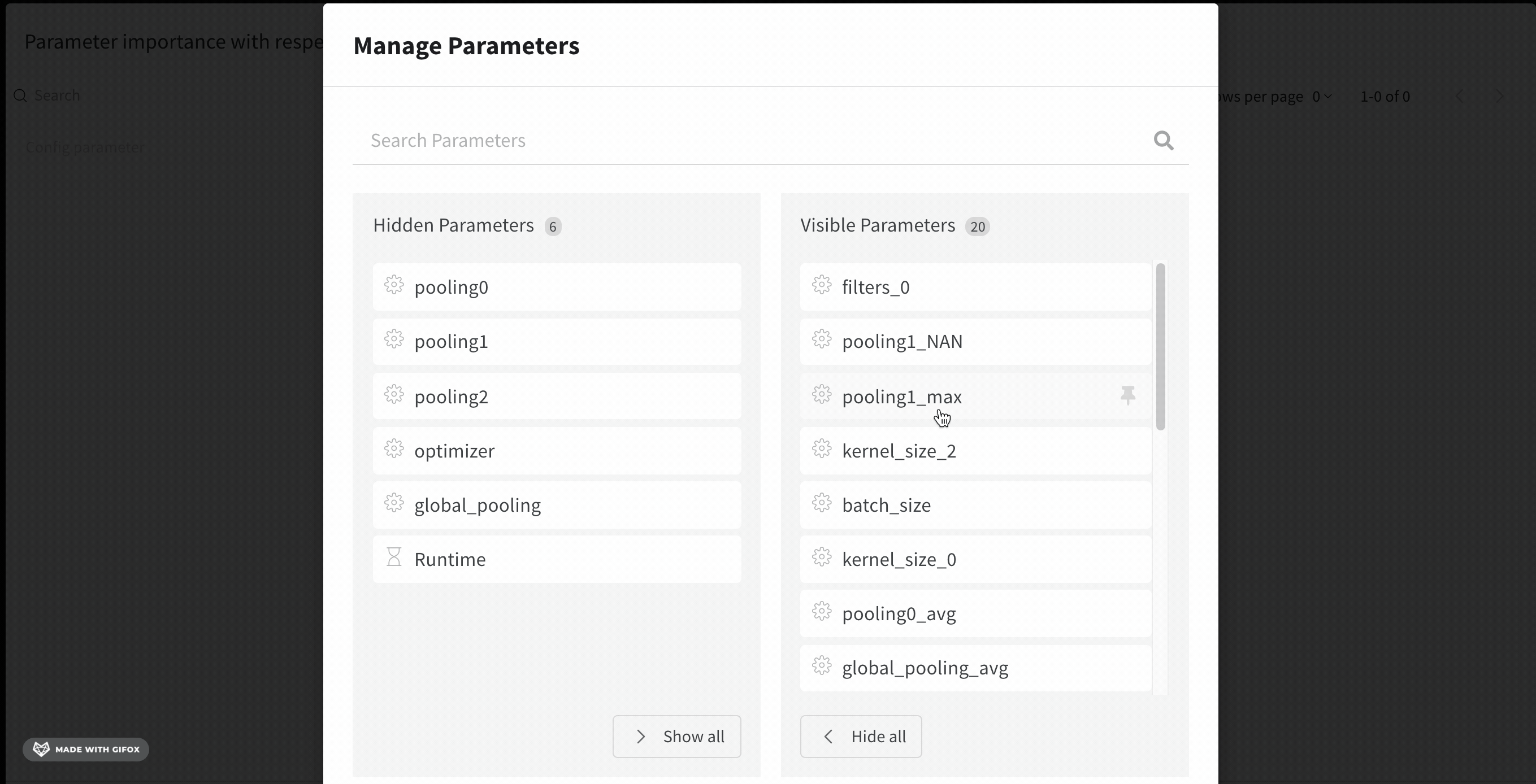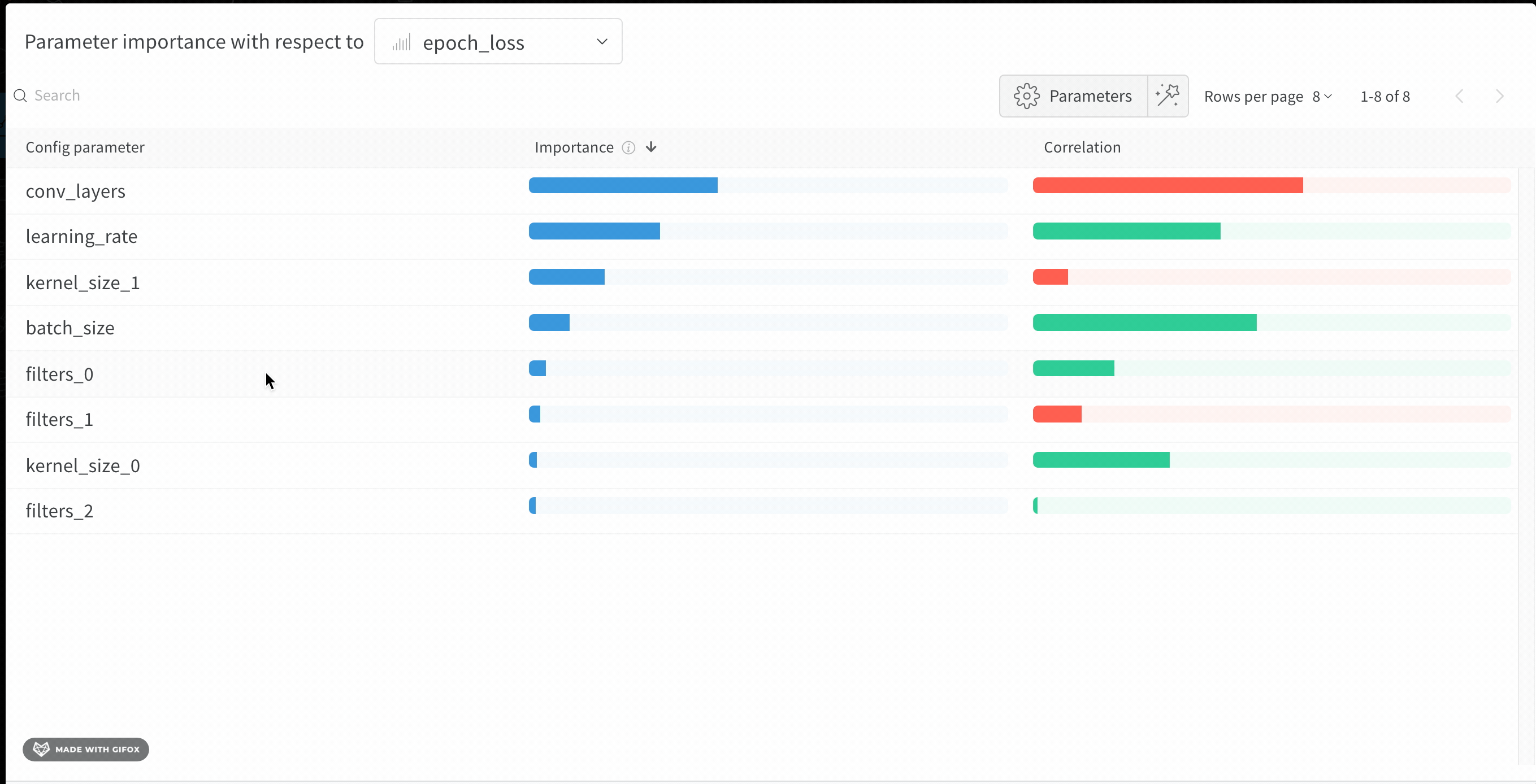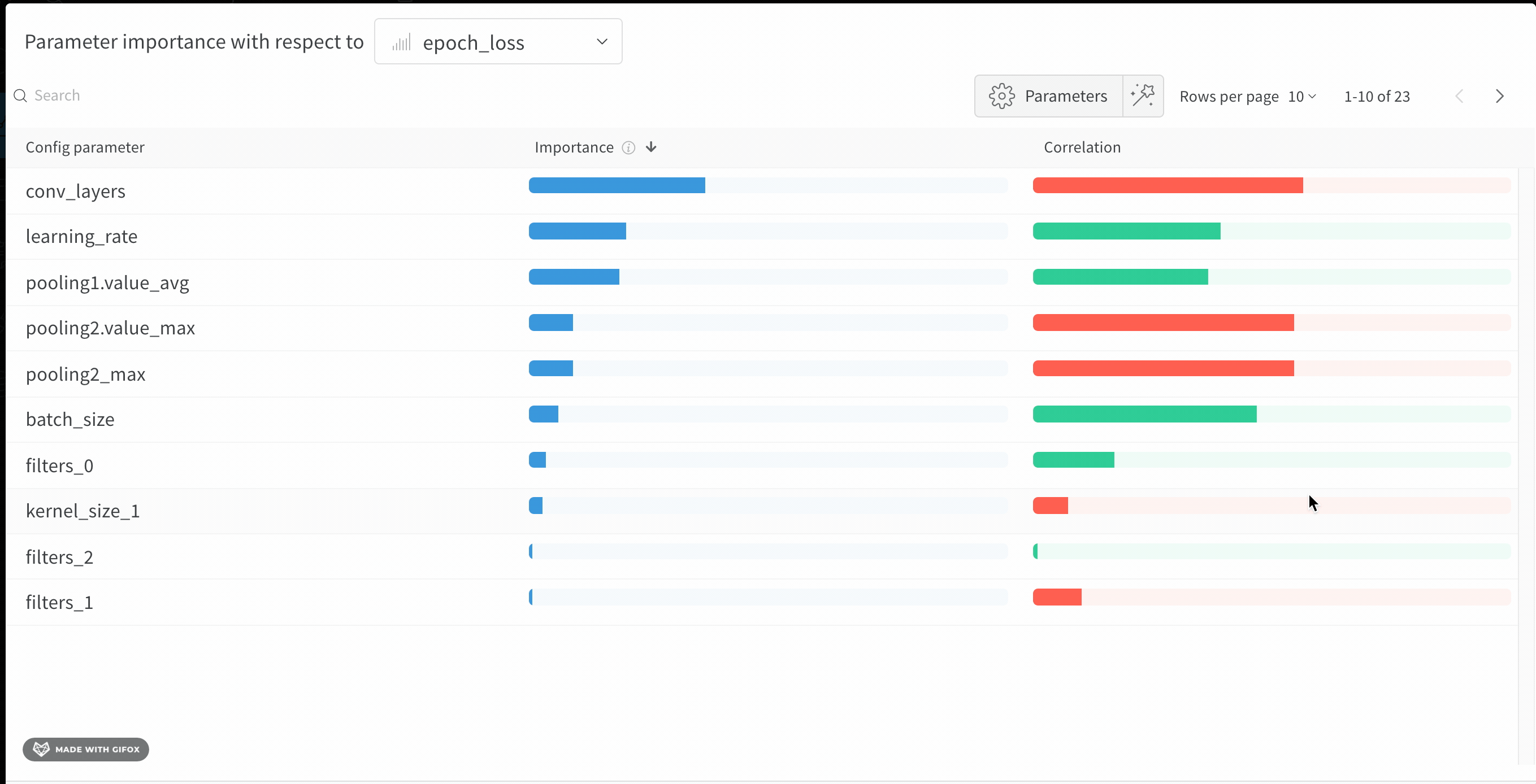
val_loss)에 대해 이러한 config 파라미터의 특성 중요도와 상관관계를 보여줍니다.
중요도
importance 열은 각 하이퍼파라미터가 선택한 메트릭을 예측하는 데 얼마나 기여했는지를 보여줍니다. 수많은 하이퍼파라미터를 튜닝하기 시작한 뒤, 이 플롯을 사용해 어떤 하이퍼파라미터를 추가로 탐색할 가치가 있는지 좁혀 나가는 상황을 떠올려 보십시오. 이후 sweep에서는 가장 중요한 하이퍼파라미터로만 범위를 제한해 더 빠르고 저렴하게 더 나은 모델을 찾을 수 있습니다.
W&B는 선형 모델이 아니라 트리 기반 모델을 사용해 중요도를 계산합니다. 트리 기반 모델은 범주형 데이터와 정규화되지 않은 데이터를 모두 더 잘 처리합니다.
epochs, learning_rate, batch_size 그리고 weight_decay가 상당히 중요한 하이퍼파라미터였음을 알 수 있습니다.
상관관계
val_loss 사이에 유의미한 관계가 있는지 (이 경우에는 예라고 할 수 있습니다)라는 질문에 답합니다. 상관계수 값은 -1에서 1 사이이며, 양수는 양의 선형 상관관계를, 음수는 음의 선형 상관관계를, 0은 상관관계가 없음을 나타냅니다. 일반적으로 어느 한쪽 방향으로 0.7을 초과하는 값은 강한 상관관계가 있다고 봅니다.
이 그래프를 활용해 메트릭과 더 높은 상관관계를 갖는 값들을 추가로 탐색할 수 있습니다 (예를 들어 이 경우 rmsprop이나 nadam 대신 stochastic gradient descent 또는 adam을 선택하거나, 더 많은 epoch 동안 학습하는 것을 고려할 수 있습니다).
- 상관관계는 인과관계를 보여주는 것이 아니라, 연관성의 증거만을 보여줍니다.
- 상관관계는 이상치에 민감하므로, 특히 시도한 하이퍼파라미터의 샘플 수가 적을 때 강한 관계를 중간 정도의 관계로 보이게 만들 수 있습니다.
- 마지막으로, 상관관계는 하이퍼파라미터와 메트릭 사이의 선형 관계만을 포착합니다. 강한 다항식 관계가 존재하더라도, 상관관계만으로는 포착되지 않습니다.