Documentation Index
Fetch the complete documentation index at: https://translations.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
W&B Weave는 LLM 및 GenAI 애플리케이션 평가를 위해 특화된 툴킷입니다. 스코어러(scorer), 재판관(judge), 세밀한 트레이싱(tracing) 등 포괄적인 평가 기능을 제공하여 모델 성능을 이해하고 개선할 수 있도록 돕습니다. 또한 Weave는 W&B Models와 통합되어 Model Registry에 저장된 모델을 평가할 수 있습니다.
- Scorers 및 Judges: 정확도, 관련성, 일관성 등을 위한 사전 정의 및 사용자 정의 평가 지표
- 평가 데이터세트: 체계적인 평가를 위한 정답(ground truth)이 포함된 구조화된 테스트 세트
- 모델 버저닝: 모델의 서로 다른 버전 추적 및 비교
- 자세한 트레이싱: 전체 입력/출력 트레이스를 통한 모델 동작 디버깅
- 비용 추적: 평가 전반에 걸친 API 비용 및 토큰 사용량 모니터링
시작하기: W&B Registry의 모델 평가하기
import weave
import wandb
from typing import Any
# Weave 초기화
weave.init("your-entity/your-project")
# W&B Registry에서 로드하는 ChatModel 정의
class ChatModel(weave.Model):
model_name: str
def model_post_init(self, __context):
# W&B Models Registry에서 모델 다운로드
with wandb.init(project="your-project", job_type="model_download") as run:
artifact = run.use_artifact(self.model_name)
self.model_path = artifact.download()
# 여기서 모델을 초기화하세요
@weave.op()
async def predict(self, query: str) -> str:
# 모델 추론 로직
return self.model.generate(query)
# 평가 데이터셋 생성
dataset = weave.Dataset(name="eval_dataset", rows=[
{"input": "What is the capital of France?", "expected": "Paris"},
{"input": "What is 2+2?", "expected": "4"},
])
# 스코어러 정의
@weave.op()
def exact_match_scorer(expected: str, output: str) -> dict:
return {"correct": expected.lower() == output.lower()}
# 평가 실행
model = ChatModel(model_name="wandb-entity/registry-name/model:version")
evaluation = weave.Evaluation(
dataset=dataset,
scorers=[exact_match_scorer]
)
results = await evaluation.evaluate(model)
Weave 평가를 W&B Models와 통합하기
- Registry에서 모델 로드: W&B Models Registry에 저장된 파인 튜닝된 모델을 다운로드합니다
- 평가 파이프라인 생성: 사용자 정의 채점기를 사용해 종합적인 평가를 구성합니다
- 결과를 다시 W&B에 로깅: 평가 지표를 모델 실행과 연결합니다
- 평가된 모델 버전 관리: 향상된 모델을 Registry에 다시 저장합니다
Weave와 W&B Models 모두에 평가 결과를 로깅합니다:
# W&B 추적으로 평가 실행
with weave.attributes({"wandb-run-id": wandb.run.id}):
summary, call = await evaluation.evaluate.call(evaluation, model)
# W&B Models에 메트릭 기록
wandb.run.log(summary)
wandb.run.config.update({
"weave_eval_url": f"https://wandb.ai/{entity}/{project}/r/call/{call.id}"
})
@weave.op()
def llm_judge_scorer(expected: str, output: str, judge_model) -> dict:
prompt = f"Is this answer correct? Expected: {expected}, Got: {output}"
judgment = await judge_model.predict(prompt)
return {"judge_score": judgment}
models = [
ChatModel(model_name="model:v1"),
ChatModel(model_name="model:v2"),
]
for model in models:
results = await evaluation.evaluate(model)
print(f"{model.model_name}: {results}")
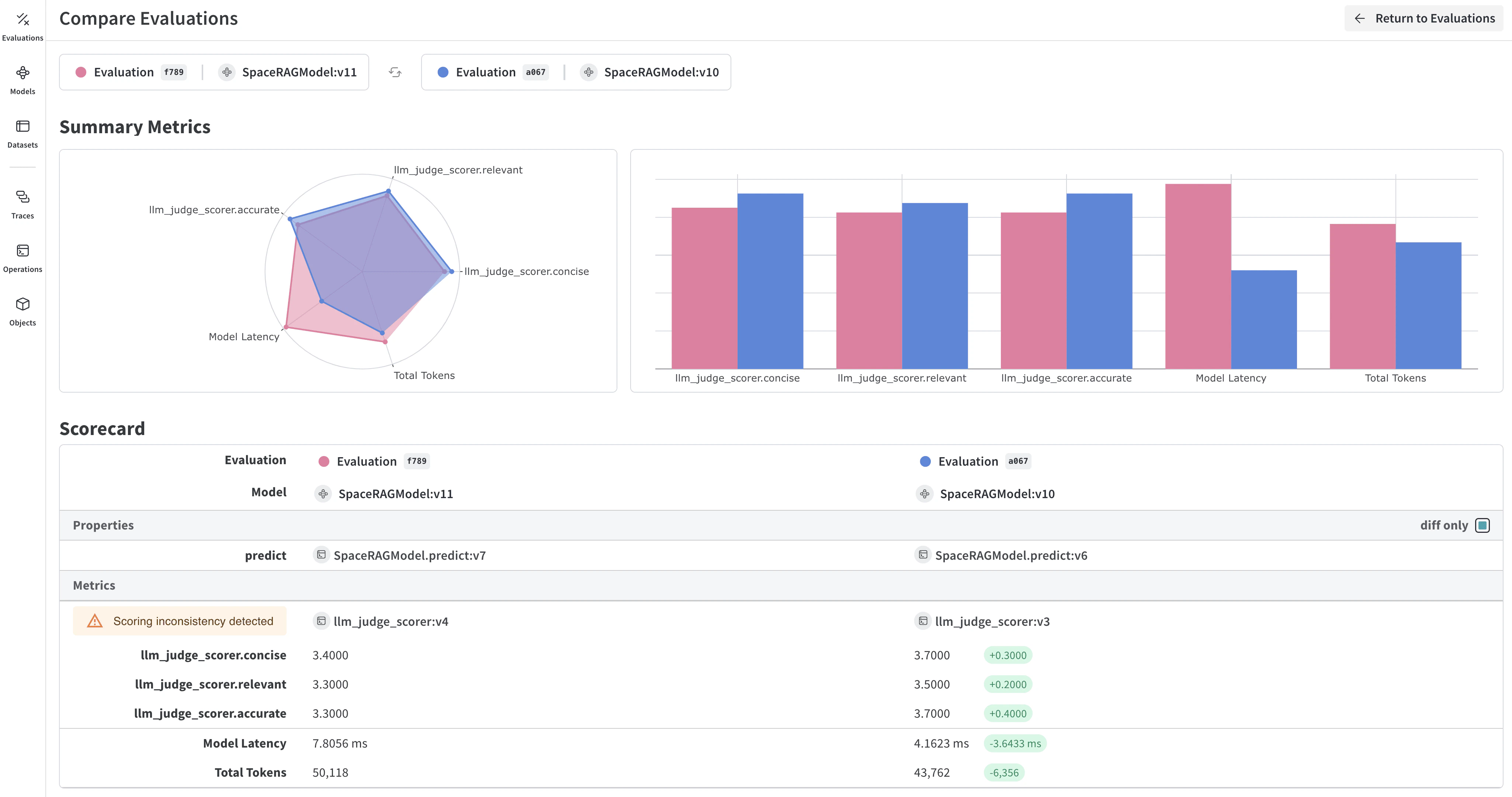
- 모델 예측 비교: 서로 다른 모델이 동일한 테스트 세트에서 어떤 성능을 내는지 나란히 비교해 확인합니다
- 예측 변화 추적: 학습 에폭 또는 모델 버전별로 예측이 어떻게 변하는지 모니터링합니다
- 오류 분석: 자주 오분류되는 예시와 오류 패턴을 찾기 위해 필터링하고 쿼리합니다
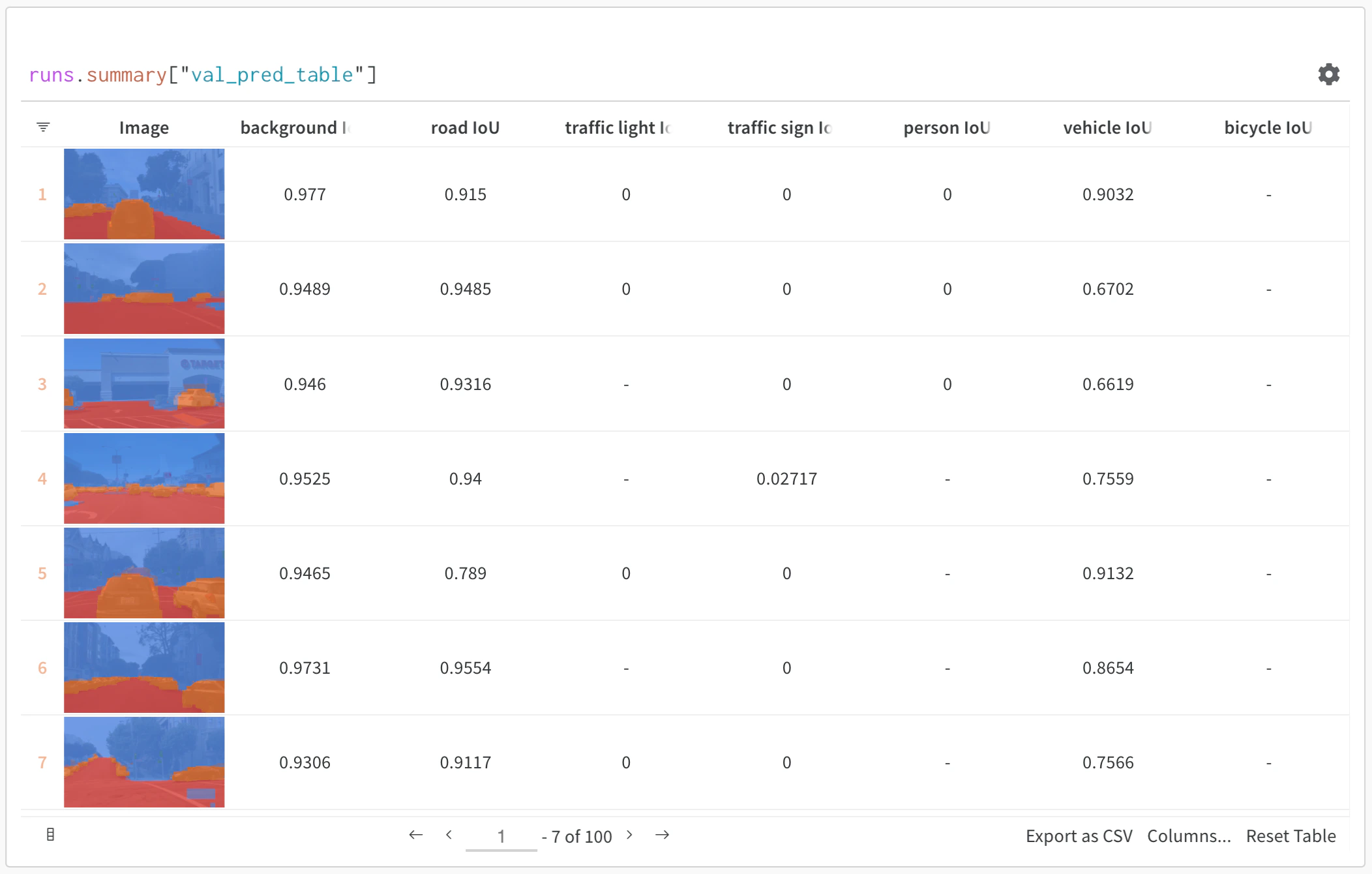
- 리치 미디어 시각화: 예측값과 메트릭과 함께 이미지, 오디오, 텍스트 및 기타 미디어 타입을 나란히 표시합니다
import wandb
# 실행 초기화
run = wandb.init(project="model-evaluation")
# 평가 결과가 담긴 테이블 생성
columns = ["id", "input", "ground_truth", "prediction", "confidence", "correct"]
eval_table = wandb.Table(columns=columns)
# 평가 데이터 추가
for idx, (input_data, label) in enumerate(test_dataset):
prediction = model(input_data)
confidence = prediction.max()
predicted_class = prediction.argmax()
eval_table.add_data(
idx,
wandb.Image(input_data), # 이미지 또는 기타 미디어 로깅
label,
predicted_class,
confidence,
label == predicted_class
)
# 테이블 로깅
run.log({"evaluation_results": eval_table})
# 모델 A 평가
with wandb.init(project="model-comparison", name="model_a") as run:
eval_table_a = create_eval_table(model_a, test_data)
run.log({"test_predictions": eval_table_a})
# 모델 B 평가
with wandb.init(project="model-comparison", name="model_b") as run:
eval_table_b = create_eval_table(model_b, test_data)
run.log({"test_predictions": eval_table_b})
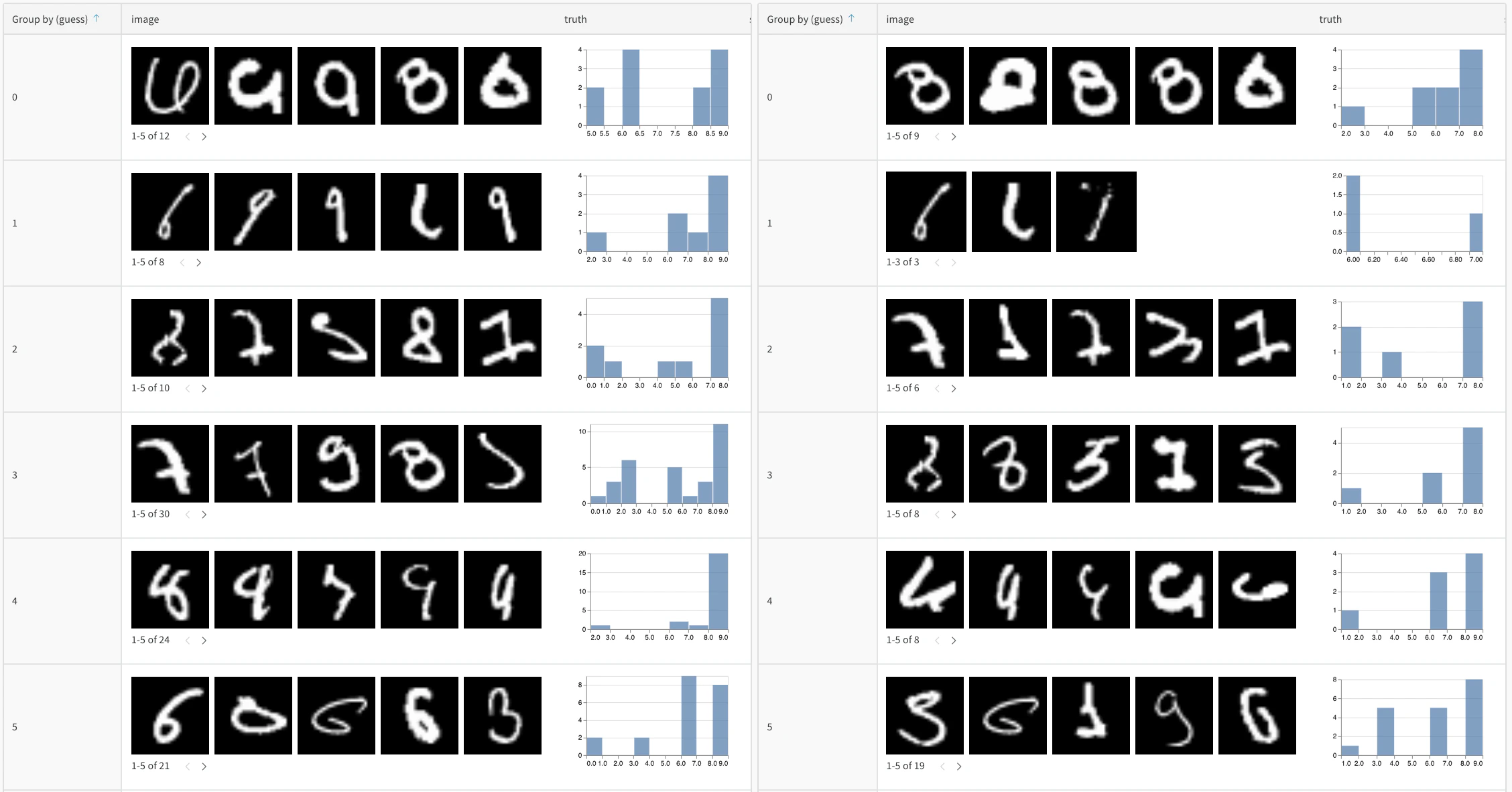
for epoch in range(num_epochs):
train_model(model, train_data)
# 이 에포크의 예측값 평가 및 기록
eval_table = wandb.Table(columns=["image", "truth", "prediction"])
for image, label in test_subset:
pred = model(image)
eval_table.add_data(wandb.Image(image), label, pred.argmax())
wandb.log({f"predictions_epoch_{epoch}": eval_table})
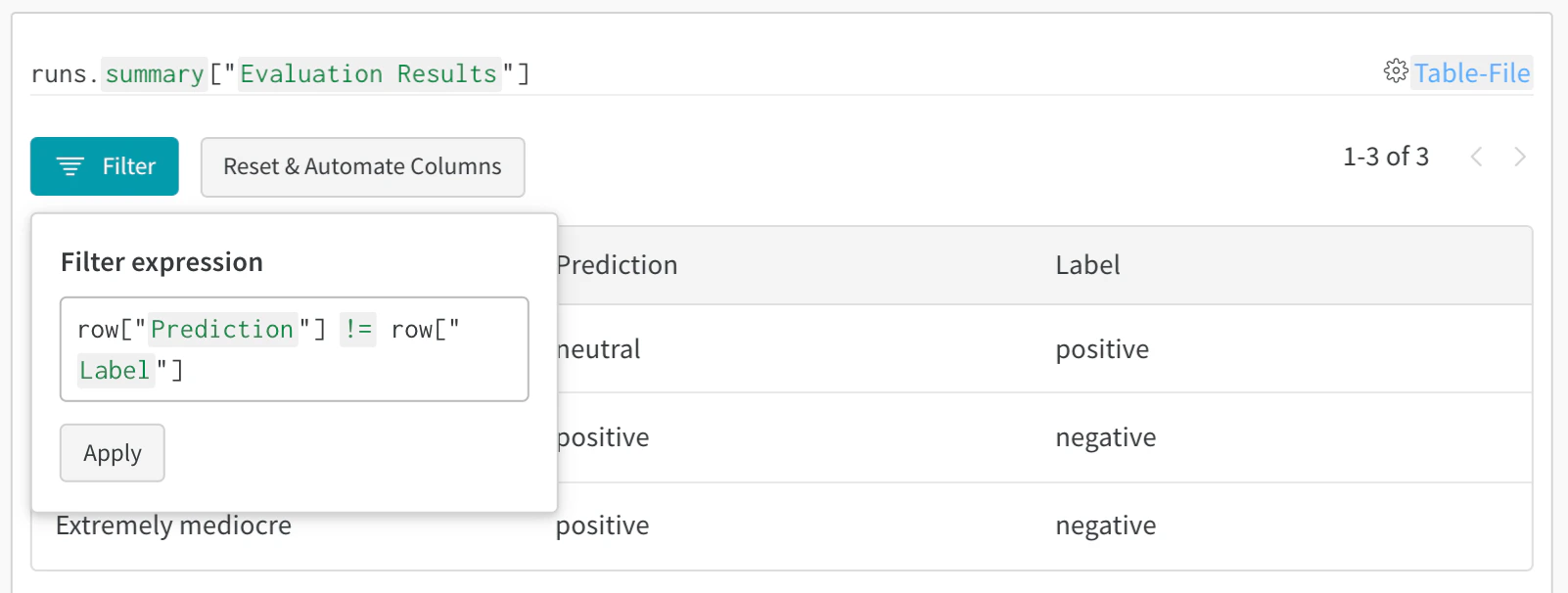
- 결과 필터링: 열 헤더를 클릭해 예측 정확도, 신뢰도 임계값, 특정 클래스 등으로 필터링합니다.
- 테이블 비교: 여러 테이블 버전을 선택해 나란히 비교합니다.
- 데이터 쿼리: 쿼리 바를 사용해 특정 패턴을 찾습니다(예:
"correct" = false AND "confidence" > 0.8).
- 그룹 및 집계: 예측 클래스로 그룹화하여 클래스별 정확도 지표를 확인합니다.
# 분석 열을 추가하기 위한 가변 테이블 생성
eval_table = wandb.Table(
columns=["id", "image", "label", "prediction"],
log_mode="MUTABLE" # 나중에 열 추가 허용
)
# 초기 예측
for idx, (img, label) in enumerate(test_data):
pred = model(img)
eval_table.add_data(idx, wandb.Image(img), label, pred.argmax())
run.log({"eval_analysis": eval_table})
# 오류 분석을 위한 신뢰도 점수 추가
confidences = [model(img).max() for img, _ in test_data]
eval_table.add_column("confidence", confidences)
# 오류 유형 추가
error_types = classify_errors(eval_table.get_column("label"),
eval_table.get_column("prediction"))
eval_table.add_column("error_type", error_types)
run.log({"eval_analysis": eval_table})