Use this file to discover all available pages before exploring further.
Colab에서 실행해 보기원하는 메트릭(예: 모델 정확도)을 만족하는 머신 러닝 모델을 찾는 일은 보통 여러 번 반복해야 하는 번거로운 작업입니다. 상황을 더 어렵게 만드는 것은, 주어진 학습 실행에서 어떤 하이퍼파라미터 조합을 사용해야 할지 명확하지 않을 수 있다는 점입니다.W&B Sweeps를 사용하면 학습률, 배치 크기, 은닉층 수, 옵티마이저 유형 등과 같은 하이퍼파라미터 값 조합을 자동으로 탐색하여, 원하는 메트릭 기준으로 모델을 최적화하는 값을 찾을 수 있는 체계적이고 효율적인 방법으로 검색을 수행할 수 있습니다.이 튜토리얼에서는 W&B PyTorch 통합을 사용해 하이퍼파라미터 탐색을 설정합니다. 동영상 튜토리얼을 보면서 따라 해 보세요.
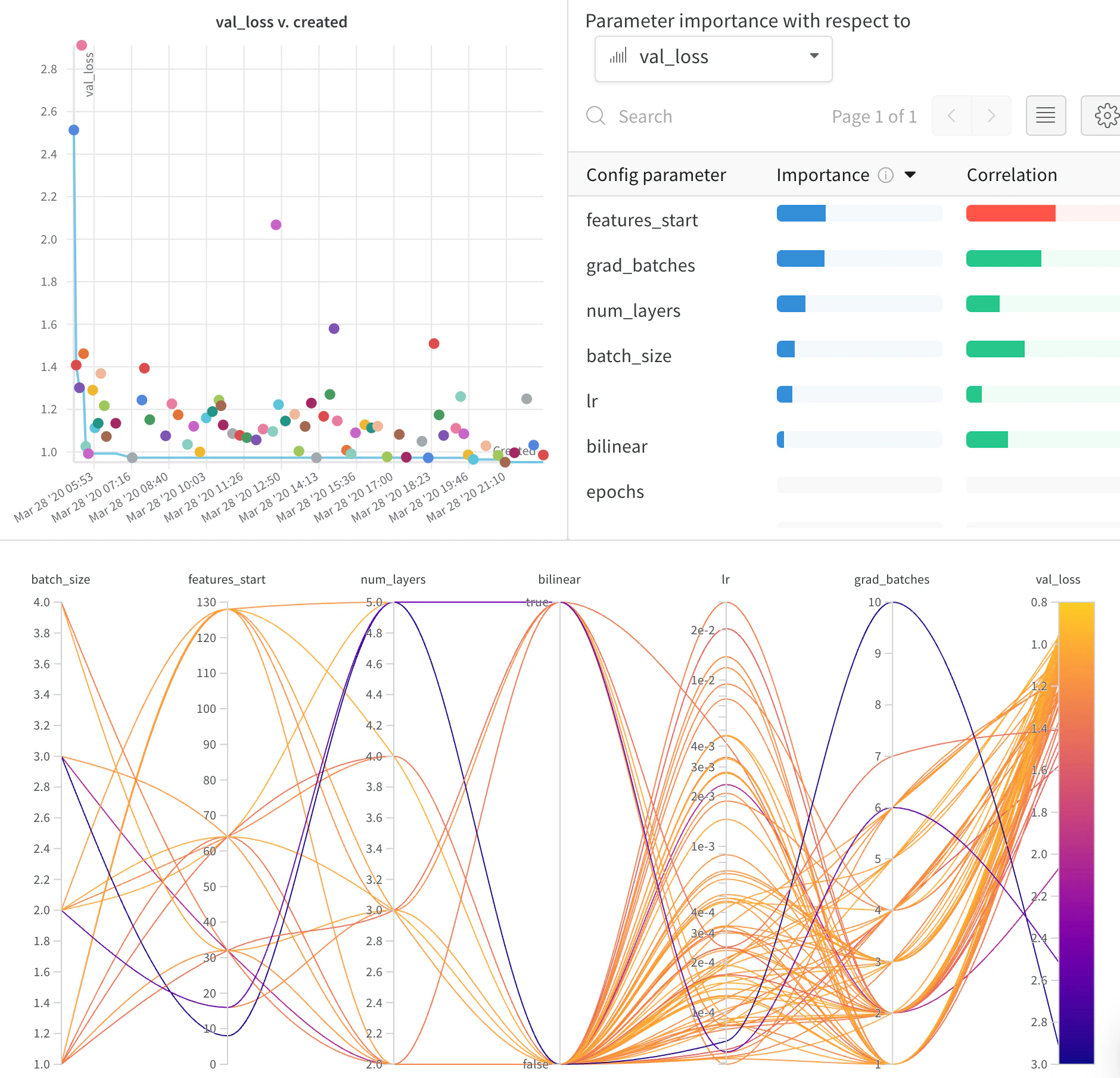
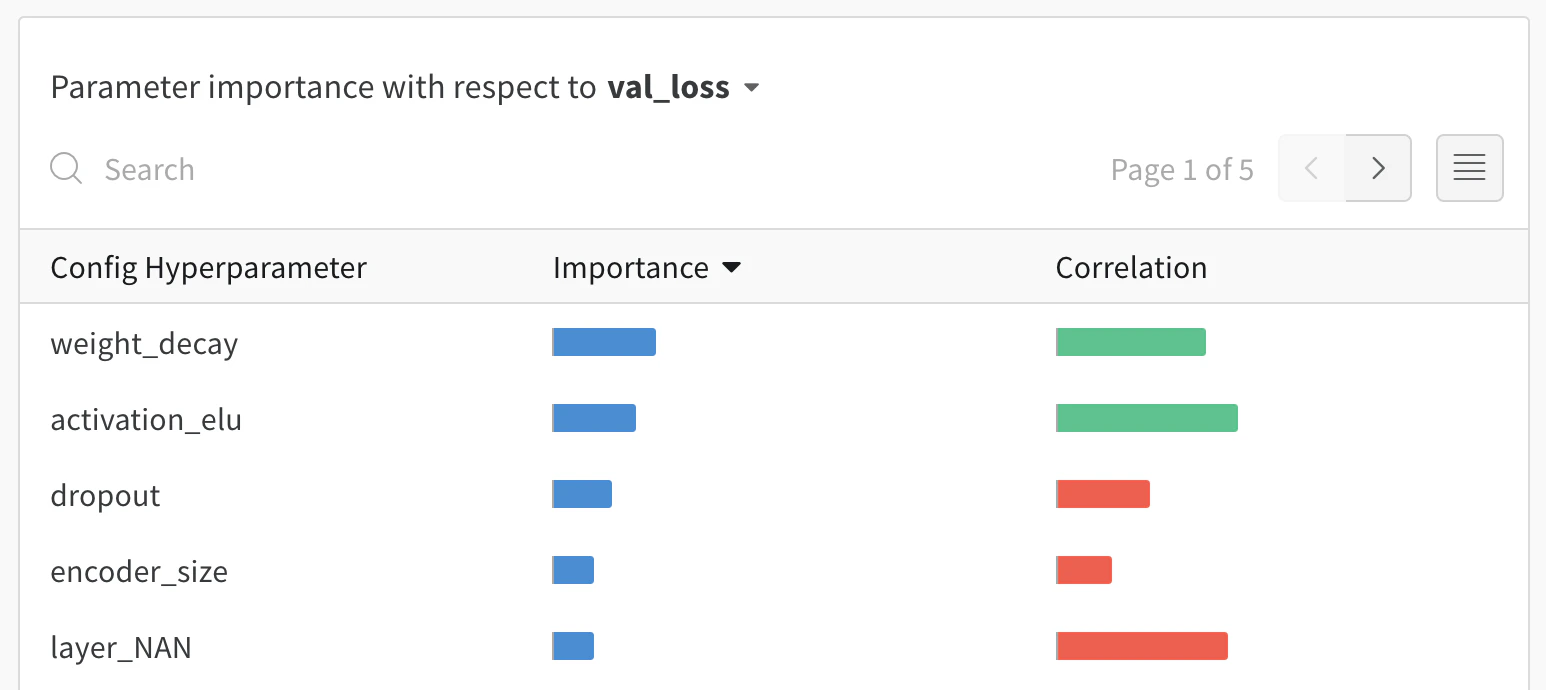
이제 스윕 구성에서 탐색 방법을 지정했으므로, 어떤 하이퍼파라미터를 탐색할지 지정합니다.이를 위해 parameter 키에 하나 이상의 하이퍼파라미터 이름을 지정하고, value 키에 해당하는 하나 이상의 하이퍼파라미터 값을 지정합니다.특정 하이퍼파라미터에 대해 탐색할 값은, 살펴보려는 하이퍼파라미터의 유형에 따라 달라집니다.예를 들어 머신러닝 옵티마이저를 선택한 경우, Adam 옵티마이저나 확률적 경사 하강법과 같은 하나 이상의 구체적인 옵티마이저 이름을 지정해야 합니다.
검색 전략을 정의했다면, 이제 이를 구현할 수단을 설정할 차례입니다.W&B는 클라우드 또는 하나 이상의 머신에서 로컬로 sweep을 관리하기 위해 Sweep Controller를 사용합니다. 이 튜토리얼에서는 W&B가 관리하는 Sweep Controller를 사용합니다.Sweep Controller가 sweep을 관리하는 동안, 실제로 sweep을 실행하는 구성 요소는 sweep agent라고 합니다.
기본적으로 Sweep Controller 구성 요소는 W&B의 서버에서 시작되며, sweep을 생성하는 구성 요소인 sweep agent는 로컬 머신에서 활성화됩니다.
노트북 내에서 wandb.sweep 메서드를 사용해 Sweep Controller를 활성화할 수 있습니다. 앞에서 정의한 sweep 구성 딕셔너리를 sweep_config 필드에 전달하십시오:
스윕을 실행하기 전에 시도해 보고 싶은 하이퍼파라미터 값을 사용하는 학습 절차를 정의합니다. 학습 코드에 W&B Sweeps를 통합하는 핵심은, 각 학습 실험에서 학습 로직이 스윕 구성에서 정의한 하이퍼파라미터 값에 접근할 수 있도록 하는 것입니다.다음 코드 예제에서 build_dataset, build_network, build_optimizer, train_epoch 헬퍼 함수들은 스윕 하이퍼파라미터 구성 딕셔너리(사전)에 접근합니다.다음 머신러닝 학습 코드를 노트북에서 실행하십시오. 이 함수들은 PyTorch를 사용해 기본적인 완전연결 신경망을 정의합니다.
import torchimport torch.optim as optimimport torch.nn.functional as Fimport torch.nn as nnfrom torchvision import datasets, transformsdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")def train(config=None): # 새로운 wandb 실행 초기화 with wandb.init(config=config) as run: # 아래와 같이 wandb.agent에 의해 호출된 경우, # 이 config는 Sweep Controller에 의해 설정됩니다 config = run.config loader = build_dataset(config.batch_size) network = build_network(config.fc_layer_size, config.dropout) optimizer = build_optimizer(network, config.optimizer, config.learning_rate) for epoch in range(config.epochs): avg_loss = train_epoch(network, loader, optimizer) run.log({"loss": avg_loss, "epoch": epoch})
train 함수 내부에서 다음과 같은 W&B Python SDK 메서드를 사용합니다:
wandb.init(): 새로운 W&B 실행을 초기화합니다. 각 실행은 학습 함수의 단일 실행입니다.
이제 스윕 설정을 정의했고, 해당 하이퍼파라미터를 동적으로 활용할 수 있는 학습 스크립트도 준비되었으므로, 스윕 에이전트를 활성화할 준비가 되었습니다. 스윕 에이전트는 스윕 설정에서 정의한 하이퍼파라미터 값 집합으로 실험을 실행하는 역할을 담당합니다.wandb.agent 메서드를 호출해 스윕 에이전트를 생성합니다. 다음 값을 전달합니다:
에이전트가 속한 스윕 (sweep_id)
스윕이 실행해야 할 함수. 이 예제에서는 스윕이 train 함수를 사용합니다.
(선택 사항) 스윕 컨트롤러에 요청할 설정 개수 (count)
동일한 sweep_id로 여러 스윕 에이전트를
서로 다른 컴퓨팅 리소스에서 시작할 수 있습니다. 스윕 컨트롤러는
여러분이 정의한 스윕 설정에 맞게 이들이 함께 동작하도록 보장합니다.
다음 셀은 학습 함수(train)를 5번 실행하는 스윕 에이전트를 활성화합니다:
wandb.agent(sweep_id, train, count=5)
스윕 설정에서 random 탐색 방식을 지정했기 때문에 스윕 컨트롤러는 무작위로 생성된 하이퍼파라미터 값을 제공합니다.
터미널에서 W&B 스윕을 생성하는 방법에 대한 자세한 내용은 W&B 스윕 워크스루를 참조하세요.
여러분이 바로 실습해 볼 수 있도록, 간단한 학습 스크립트와 여러 가지 Sweep 구성 예시를 준비해 두었습니다. 꼭 한 번 시도해 보시기를 강력히 추천합니다.해당 리포지터리에는 Bayesian Hyperband, Hyperopt와 같은 더 고급 Sweep 기능을 활용해 볼 수 있도록 도와주는 예제들도 포함되어 있습니다.