# 테스트 이미지 배치에 대한 예측을 기록하는 편의 함수
def log_test_predictions(images, labels, outputs, predicted, test_table, log_counter):
# 모든 클래스에 대한 신뢰도 점수 획득
scores = F.softmax(outputs.data, dim=1)
log_scores = scores.cpu().numpy()
log_images = images.cpu().numpy()
log_labels = labels.cpu().numpy()
log_preds = predicted.cpu().numpy()
# 이미지 순서에 따라 id 추가
_id = 0
for i, l, p, s in zip(log_images, log_labels, log_preds, log_scores):
# 데이터 테이블에 필요한 정보 추가:
# id, 이미지 픽셀, 모델의 예측, 실제 레이블, 모든 클래스에 대한 점수
img_id = str(_id) + "_" + str(log_counter)
test_table.add_data(img_id, wandb.Image(i), p, l, *s)
_id += 1
if _id == NUM_IMAGES_PER_BATCH:
break
# W&B: 이 모델의 학습을 추적하기 위해 새 실행 초기화
with wandb.init(project="table-quickstart") as run:
# W&B: config를 사용하여 하이퍼파라미터 기록
cfg = run.config
cfg.update({"epochs" : EPOCHS, "batch_size": BATCH_SIZE, "lr" : LEARNING_RATE,
"l1_size" : L1_SIZE, "l2_size": L2_SIZE,
"conv_kernel" : CONV_KERNEL_SIZE,
"img_count" : min(10000, NUM_IMAGES_PER_BATCH*NUM_BATCHES_TO_LOG)})
# 모델, 손실 함수, 옵티마이저 정의
model = ConvNet(NUM_CLASSES).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=LEARNING_RATE)
# 모델 학습
total_step = len(train_loader)
for epoch in range(EPOCHS):
# 학습 단계
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
# 순전파
outputs = model(images)
loss = criterion(outputs, labels)
# 역전파 및 최적화
optimizer.zero_grad()
loss.backward()
optimizer.step()
# W&B: 학습 단계별 손실 기록, UI에서 실시간 시각화
run.log({"loss" : loss})
if (i+1) % 100 == 0:
print ('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
.format(epoch+1, EPOCHS, i+1, total_step, loss.item()))
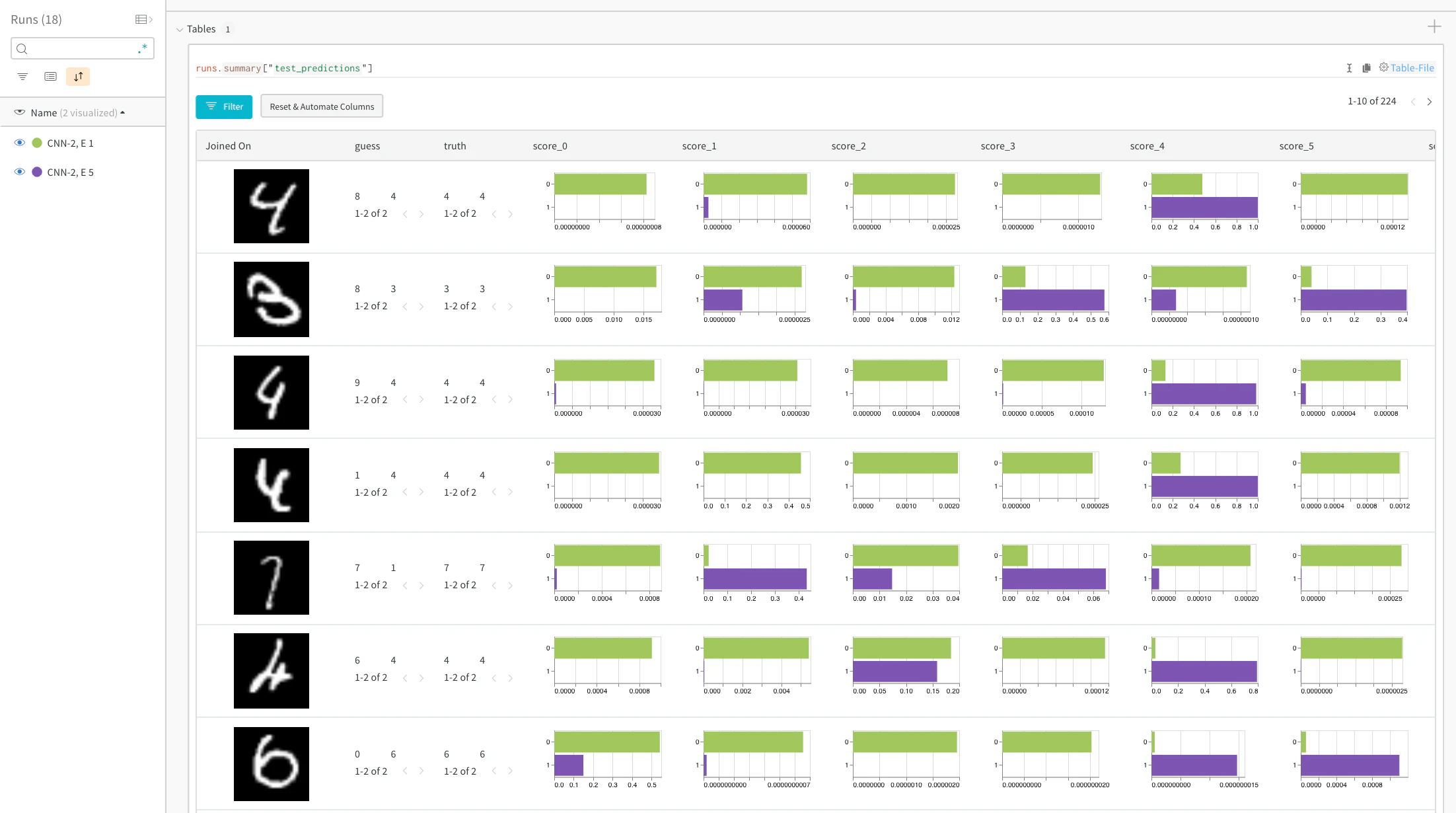
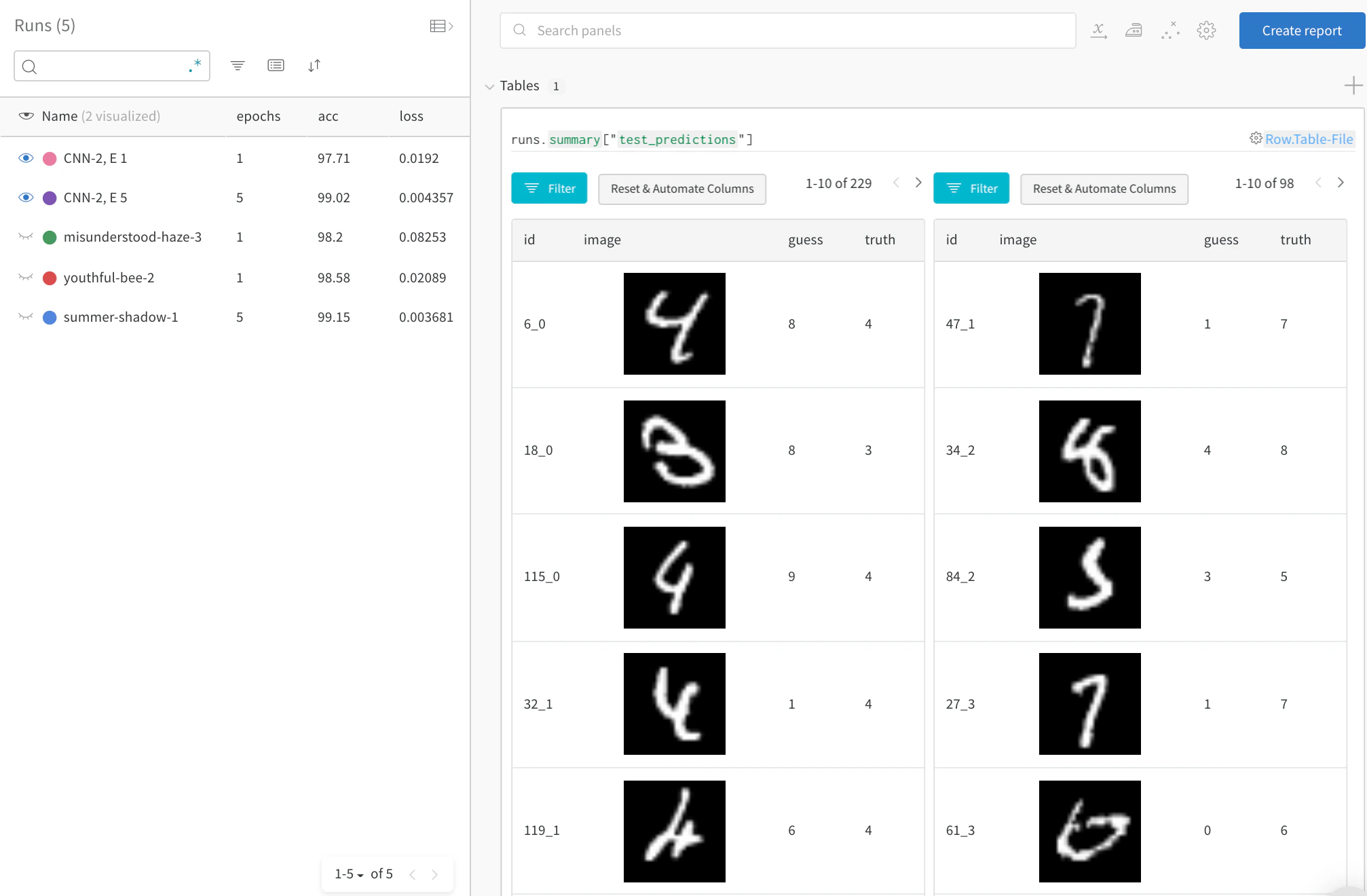
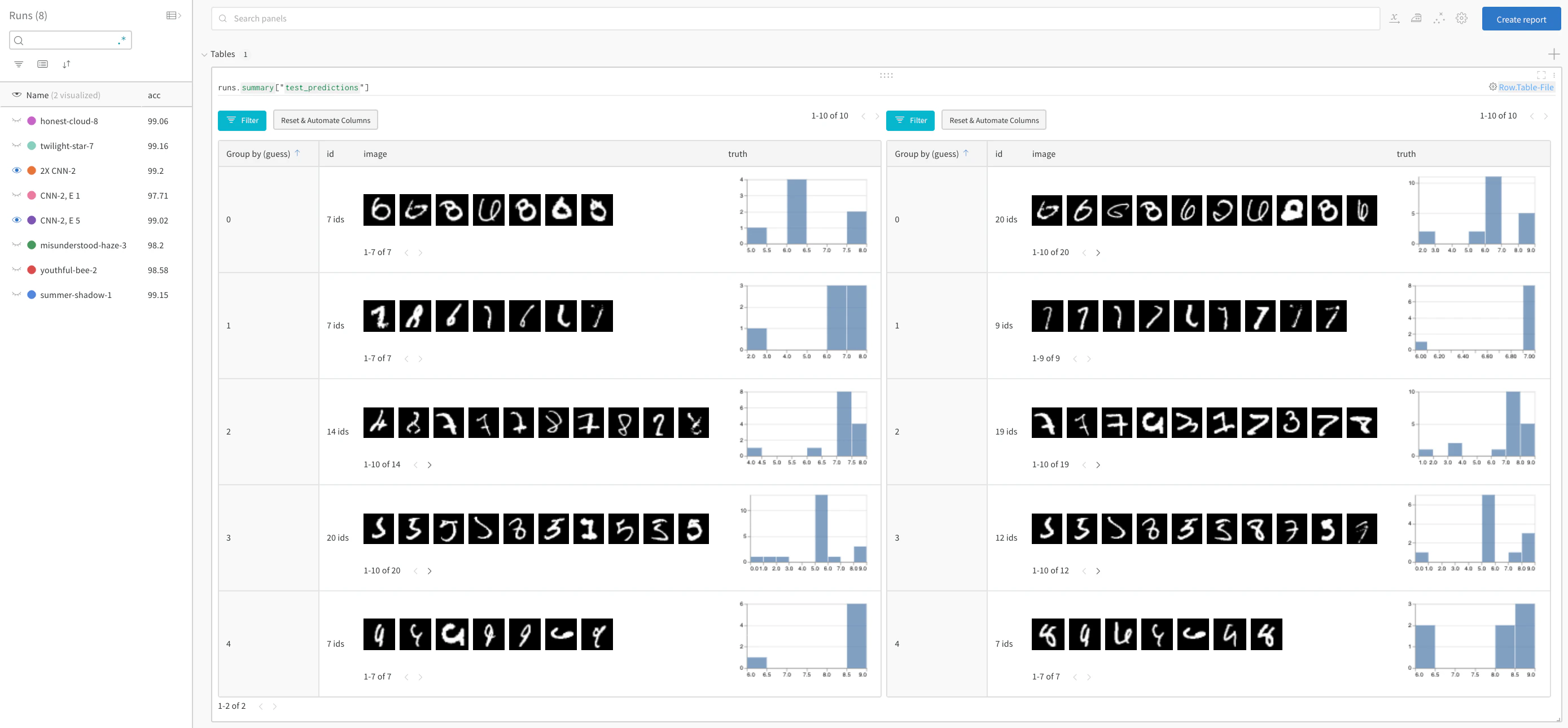
# W&B: 각 테스트 단계의 예측을 저장할 Table 생성
columns=["id", "image", "guess", "truth"]
for digit in range(10):
columns.append("score_" + str(digit))
test_table = wandb.Table(columns=columns)
# 모델 테스트
model.eval()
log_counter = 0
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
if log_counter < NUM_BATCHES_TO_LOG:
log_test_predictions(images, labels, outputs, predicted, test_table, log_counter)
log_counter += 1
total += labels.size(0)
correct += (predicted == labels).sum().item()
acc = 100 * correct / total
# W&B: 학습 에포크별 정확도 기록, UI에서 시각화
run.log({"epoch" : epoch, "acc" : acc})
print('Test Accuracy of the model on the 10000 test images: {} %'.format(acc))
# W&B: 예측 테이블을 wandb에 기록
run.log({"test_predictions" : test_table})