Documentation Index
Fetch the complete documentation index at: https://translations.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
Hugging Face AutoTrain는 자연어 처리(NLP) 작업, 컴퓨터 비전(CV) 작업, 음성 작업, 그리고 테이블(Tabular) 작업까지 최첨단 모델을 학습하기 위한 노코드(no-code) 도구입니다.
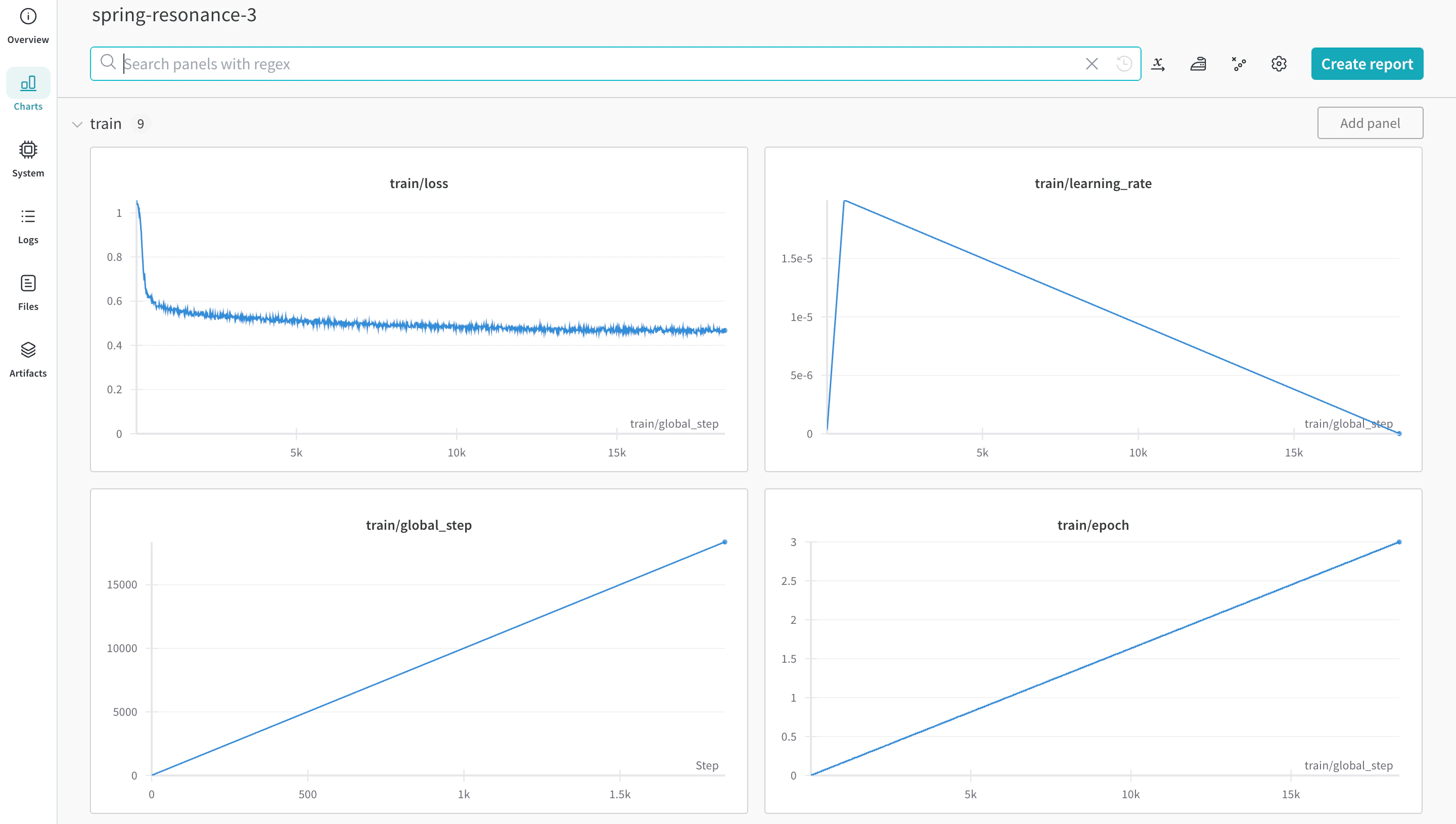
W&B는 Hugging Face AutoTrain에 직접 통합되어 실험 추적 및 구성(config) 관리를 제공합니다. 실험을 실행할 때 CLI 명령에 파라미터 하나만 추가하면 될 정도로 간단합니다.
autotrain-advanced와 wandb를 설치합니다.
pip install --upgrade autotrain-advanced wandb
!pip install --upgrade autotrain-advanced wandb
pass@1 지표에서 SoTA 수준의 성능을 달성합니다.
Hugging Face AutoTrain에서는 CSV 형식의 커스텀 데이터셋이 제대로 동작하려면 특정 형식을 따라야 합니다.
-
학습 파일에는 반드시 학습에 사용되는
text 열이 포함되어 있어야 합니다. 최상의 결과를 얻으려면 text 열의 데이터가 ### Human: Question?### Assistant: Answer. 형식을 따라야 합니다. timdettmers/openassistant-guanaco에서 좋은 예시를 확인할 수 있습니다.
그러나 MetaMathQA 데이터셋에는 query, response, type 열이 포함되어 있습니다. 먼저 이 데이터셋을 전처리합니다. type 열을 제거하고, query와 response 열의 내용을 결합해 ### Human: Query?### Assistant: Response. 형식의 새로운 text 열을 만듭니다. 이렇게 생성한 데이터셋 rishiraj/guanaco-style-metamath을 사용해 학습을 수행합니다.
명령줄 또는 노트북에서 고급 autotrain 기능을 사용해 학습을 시작할 수 있습니다. --log 인자를 사용하거나, 결과를 W&B 실행에 로깅하려면 --log wandb를 사용하세요.
autotrain llm \
--train \
--model HuggingFaceH4/zephyr-7b-alpha \
--project-name zephyr-math \
--log wandb \
--data-path data/ \
--text-column text \
--lr 2e-5 \
--batch-size 4 \
--epochs 3 \
--block-size 1024 \
--warmup-ratio 0.03 \
--lora-r 16 \
--lora-alpha 32 \
--lora-dropout 0.05 \
--weight-decay 0.0 \
--gradient-accumulation 4 \
--logging_steps 10 \
--fp16 \
--use-peft \
--use-int4 \
--merge-adapter \
--push-to-hub \
--token <huggingface-token> \
--repo-id <huggingface-repository-address>
# 하이퍼파라미터 설정
learning_rate = 2e-5
num_epochs = 3
batch_size = 4
block_size = 1024
trainer = "sft"
warmup_ratio = 0.03
weight_decay = 0.
gradient_accumulation = 4
lora_r = 16
lora_alpha = 32
lora_dropout = 0.05
logging_steps = 10
# 학습 실행
!autotrain llm \
--train \
--model "HuggingFaceH4/zephyr-7b-alpha" \
--project-name "zephyr-math" \
--log "wandb" \
--data-path data/ \
--text-column text \
--lr str(learning_rate) \
--batch-size str(batch_size) \
--epochs str(num_epochs) \
--block-size str(block_size) \
--warmup-ratio str(warmup_ratio) \
--lora-r str(lora_r) \
--lora-alpha str(lora_alpha) \
--lora-dropout str(lora_dropout) \
--weight-decay str(weight_decay) \
--gradient-accumulation str(gradient_accumulation) \
--logging-steps str(logging_steps) \
--fp16 \
--use-peft \
--use-int4 \
--merge-adapter \
--push-to-hub \
--token str(hf_token) \
--repo-id "rishiraj/zephyr-math"