Documentation Index
Fetch the complete documentation index at: https://translations.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
Weave는 Cerebras Cloud SDK를 통해 수행된 LLM 호출을 자동으로 추적하고 기록합니다.
LLM 호출을 추적하는 것은 디버깅과 성능 모니터링에 매우 중요합니다. Weave는 Cerebras Cloud SDK에 대한 트레이스를 자동으로 수집하여 이를 지원합니다.
다음은 Cerebras와 함께 Weave를 사용하는 예시입니다:
import os
import weave
from cerebras.cloud.sdk import Cerebras
# weave 프로젝트 초기화
weave.init("cerebras_speedster")
# 평소와 같이 Cerebras SDK 사용
api_key = os.environ["CEREBRAS_API_KEY"]
model = "llama3.1-8b" # Cerebras 모델
client = Cerebras(api_key=api_key)
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "What's the fastest land animal?"}],
)
print(response.choices[0].message.content)
 Weave op은 실험에서 재현성과 추적 가능성을 높이는 강력한 방법을 제공합니다. 코드의 버전을 자동으로 관리하고 입력과 출력을 기록합니다. 다음은 Cerebras SDK와 함께 Weave op을 활용하는 방법의 예시입니다:
Weave op은 실험에서 재현성과 추적 가능성을 높이는 강력한 방법을 제공합니다. 코드의 버전을 자동으로 관리하고 입력과 출력을 기록합니다. 다음은 Cerebras SDK와 함께 Weave op을 활용하는 방법의 예시입니다:
import os
import weave
from cerebras.cloud.sdk import Cerebras
# weave 프로젝트 초기화
weave.init("cerebras_speedster")
client = Cerebras(api_key=os.environ["CEREBRAS_API_KEY"])
# Weave가 이 함수의 입력, 출력 및 코드를 추적합니다
@weave.op
def animal_speedster(animal: str, model: str) -> str:
"Find out how fast an animal can run"
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": f"How fast can a {animal} run?"}],
)
return response.choices[0].message.content
animal_speedster("cheetah", "llama3.1-8b")
animal_speedster("ostrich", "llama3.1-8b")
animal_speedster("human", "llama3.1-8b")
import os
import weave
from cerebras.cloud.sdk import Cerebras
# Weave 프로젝트 초기화
weave.init("cerebras_speedster")
client = Cerebras(api_key=os.environ["CEREBRAS_API_KEY"])
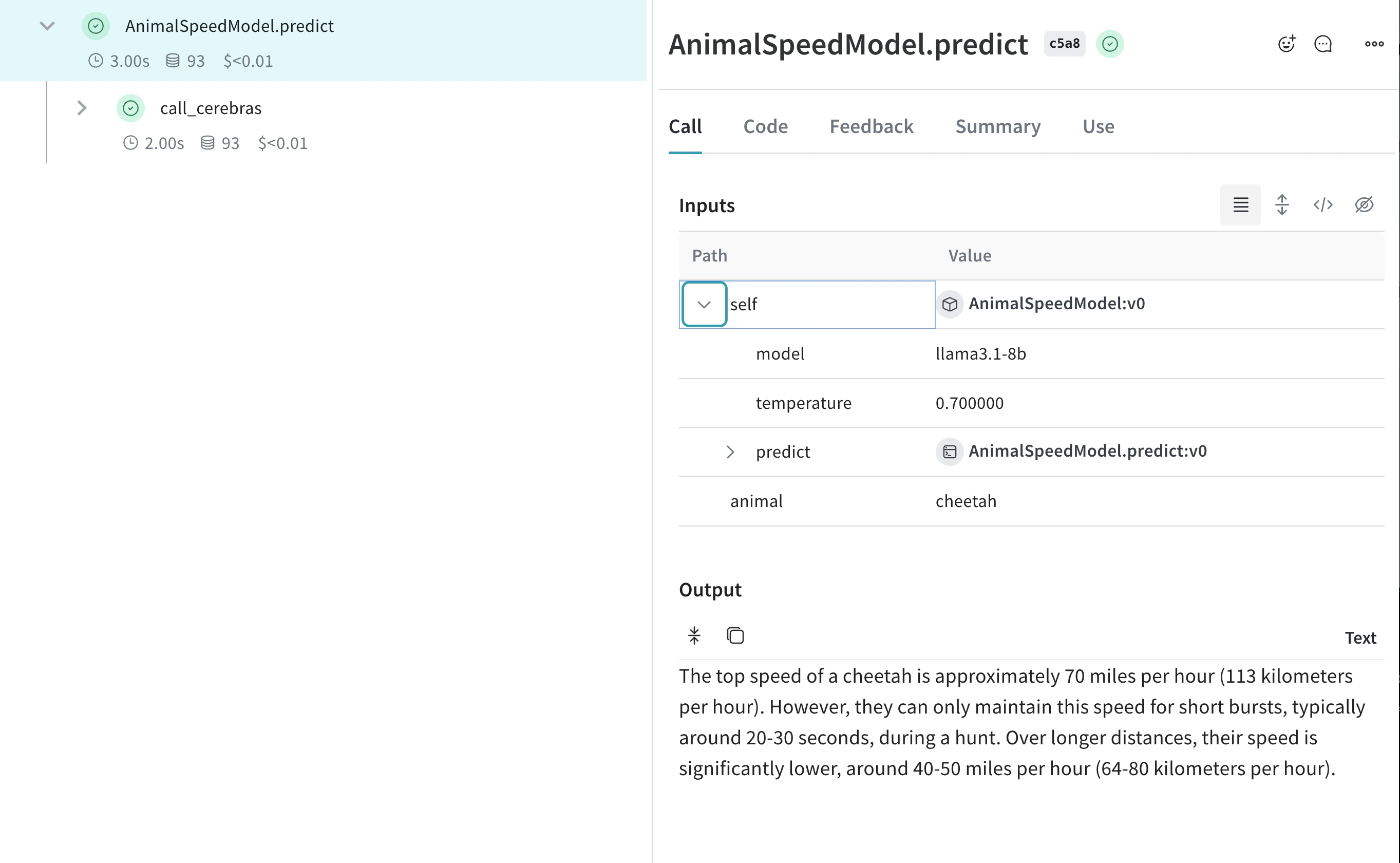
class AnimalSpeedModel(weave.Model):
model: str
temperature: float
@weave.op
def predict(self, animal: str) -> str:
"동물의 최고 속도를 예측합니다"
response = client.chat.completions.create(
model=self.model,
messages=[{"role": "user", "content": f"What's the top speed of a {animal}?"}],
temperature=self.temperature
)
return response.choices[0].message.content
speed_model = AnimalSpeedModel(
model="llama3.1-8b",
temperature=0.7
)
result = speed_model.predict(animal="cheetah")
print(result)