Documentation Index
Fetch the complete documentation index at: https://translations.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
Weave는 선도적인 AI 기업들의 파운데이션 모델을 통합 API를 통해 제공하는 AWS의 완전 관리형 서비스인 Amazon Bedrock을 통해 수행되는 LLM 호출을 자동으로 추적하고 로그로 기록합니다.
Amazon Bedrock에서 Weave로 LLM 호출을 기록하는 방법은 여러 가지가 있습니다. weave.op을 사용하여 Bedrock 모델에 대한 모든 호출을 추적하는 데 사용할 수 있는 재사용 가능한 op를 만들 수 있습니다. 선택적으로, Anthropic 모델을 사용하는 경우 Weave에 내장된 Anthropic 통합 기능을 사용할 수 있습니다.
Weave는 Bedrock API 호출에 대한 트레이스를 자동으로 캡처합니다. Weave를 초기화하고 클라이언트를 패치한 후에는 평소처럼 Bedrock 클라이언트를 사용할 수 있습니다:
import weave
import boto3
import json
from weave.integrations.bedrock.bedrock_sdk import patch_client
weave.init("my_bedrock_app")
# Bedrock 클라이언트 생성 및 패치
client = boto3.client("bedrock-runtime")
patch_client(client)
# 클라이언트를 평소처럼 사용
response = client.invoke_model(
modelId="anthropic.claude-3-5-sonnet-20240620-v1:0",
body=json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 100,
"messages": [
{"role": "user", "content": "What is the capital of France?"}
]
}),
contentType='application/json',
accept='application/json'
)
response_dict = json.loads(response.get('body').read())
print(response_dict["content"][0]["text"])
converse API 사용:
messages = [{"role": "user", "content": [{"text": "What is the capital of France?"}]}]
response = client.converse(
modelId="anthropic.claude-3-5-sonnet-20240620-v1:0",
system=[{"text": "You are a helpful AI assistant."}],
messages=messages,
inferenceConfig={"maxTokens": 100},
)
print(response["output"]["message"]["content"][0]["text"])
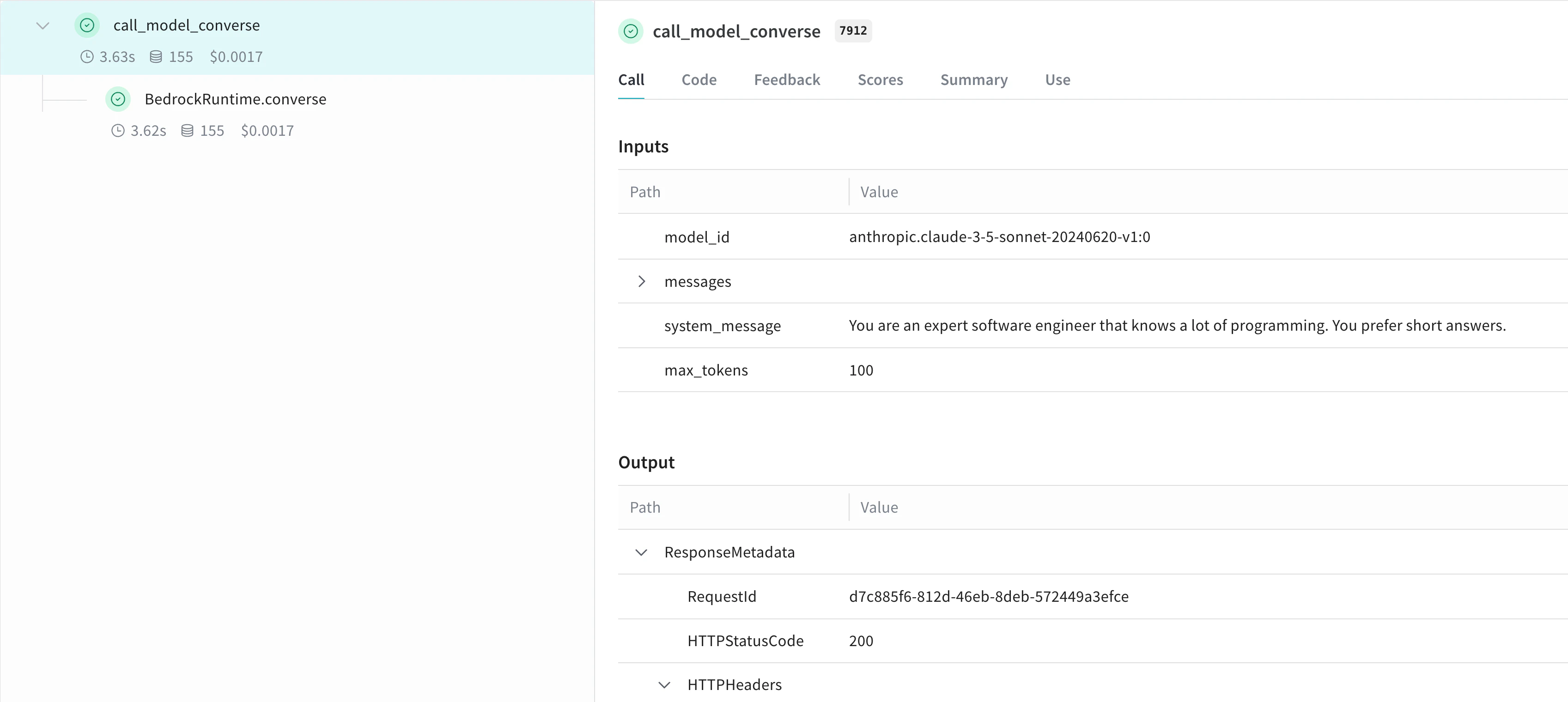
@weave.op() 데코레이터를 사용해서 재사용 가능한 op을 만들 수 있습니다. 다음은 invoke_model과 converse API 둘 다를 보여 주는 예시입니다.
@weave.op
def call_model_invoke(
model_id: str,
prompt: str,
max_tokens: int = 100,
temperature: float = 0.7
) -> dict:
body = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": max_tokens,
"temperature": temperature,
"messages": [
{"role": "user", "content": prompt}
]
})
response = client.invoke_model(
modelId=model_id,
body=body,
contentType='application/json',
accept='application/json'
)
return json.loads(response.get('body').read())
@weave.op
def call_model_converse(
model_id: str,
messages: str,
system_message: str,
max_tokens: int = 100,
) -> dict:
response = client.converse(
modelId=model_id,
system=[{"text": system_message}],
messages=messages,
inferenceConfig={"maxTokens": max_tokens},
)
return response
Model을 생성할 수 있습니다. 다음은 converse API를 사용하는 예시입니다:
class BedrockLLM(weave.Model):
model_id: str
max_tokens: int = 100
system_message: str = "You are a helpful AI assistant."
@weave.op
def predict(self, prompt: str) -> str:
"Generate a response using Bedrock's converse API"
messages = [{
"role": "user",
"content": [{"text": prompt}]
}]
response = client.converse(
modelId=self.model_id,
system=[{"text": self.system_message}],
messages=messages,
inferenceConfig={"maxTokens": self.max_tokens},
)
return response["output"]["message"]["content"][0]["text"]
# 모델 생성 및 사용
model = BedrockLLM(
model_id="anthropic.claude-3-5-sonnet-20240620-v1:0",
max_tokens=100,
system_message="You are an expert software engineer that knows a lot of programming. You prefer short answers."
)
result = model.predict("What is the best way to handle errors in Python?")
print(result)
Weave Playground에서 Bedrock 사용해 보기
리포트: Weave를 사용해 Bedrock에서 텍스트 요약용 LLM 비교하기