Documentation Index
Fetch the complete documentation index at: https://translations.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
 Groq는 빠른 AI 추론을 제공하는 AI 인프라스트럭처 기업입니다. Groq의 LPU™ Inference Engine은 뛰어난 연산 속도, 품질, 에너지 효율성을 제공하는 하드웨어 및 소프트웨어 플랫폼입니다. Weave는 Groq chat completion을 사용할 때 발생하는 호출을 자동으로 추적하고 로그에 기록합니다.
언어 모델 애플리케이션의 트레이스를 개발 및 프로덕션 환경에서 모두 중앙화된 위치에 저장하는 것은 중요합니다. 이러한 트레이스는 디버깅에 유용할 뿐만 아니라, 애플리케이션을 개선하는 데 도움이 되는 데이터셋으로도 활용할 수 있습니다.
Weave는 Groq에 대한 트레이스를 자동으로 캡처합니다. 추적을 시작하려면
Groq는 빠른 AI 추론을 제공하는 AI 인프라스트럭처 기업입니다. Groq의 LPU™ Inference Engine은 뛰어난 연산 속도, 품질, 에너지 효율성을 제공하는 하드웨어 및 소프트웨어 플랫폼입니다. Weave는 Groq chat completion을 사용할 때 발생하는 호출을 자동으로 추적하고 로그에 기록합니다.
언어 모델 애플리케이션의 트레이스를 개발 및 프로덕션 환경에서 모두 중앙화된 위치에 저장하는 것은 중요합니다. 이러한 트레이스는 디버깅에 유용할 뿐만 아니라, 애플리케이션을 개선하는 데 도움이 되는 데이터셋으로도 활용할 수 있습니다.
Weave는 Groq에 대한 트레이스를 자동으로 캡처합니다. 추적을 시작하려면 weave.init(project_name="<YOUR-WANDB-PROJECT-NAME>")를 호출한 다음 라이브러리를 평소처럼 사용하면 됩니다.
import os
import weave
from groq import Groq
weave.init(project_name="groq-project")
client = Groq(
api_key=os.environ.get("GROQ_API_KEY"),
)
chat_completion = client.chat.completions.create(
messages=[
{
"role": "user",
"content": "Explain the importance of fast language models",
}
],
model="llama3-8b-8192",
)
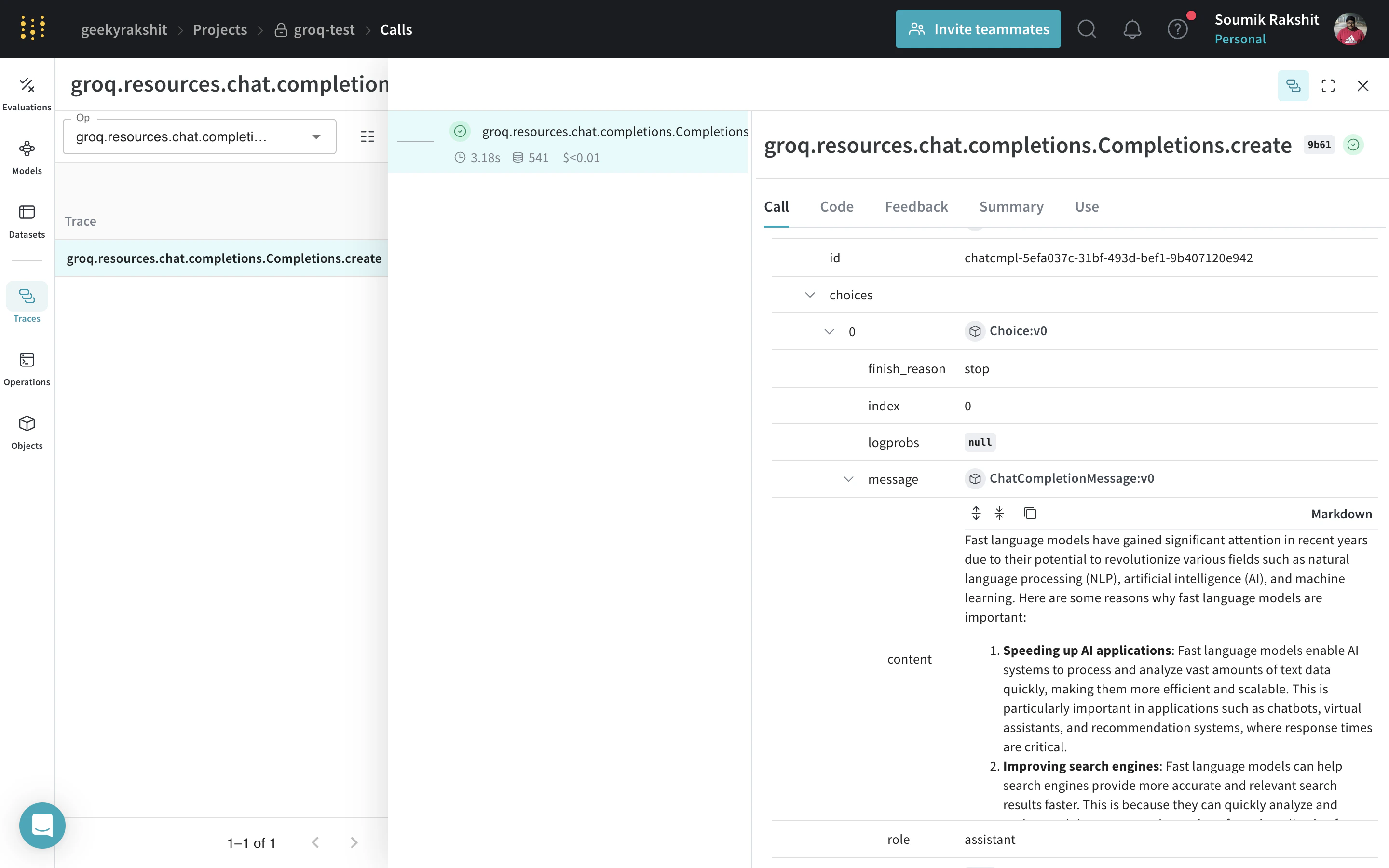 |
|---|
| 이제 Weave가 Groq 라이브러리를 통해 발생한 모든 LLM 호출을 추적해 로그로 남깁니다. Weave 웹 인터페이스에서 트레이스를 확인할 수 있습니다. |
@weave.op으로 감싸면 입력, 출력, 애플리케이션 로직을 캡처하기 시작하므로 데이터가 앱을 통해 어떻게 흐르는지 디버깅할 수 있습니다. op를 깊게 중첩해 추적하려는 함수들의 트리 구조를 만들 수 있습니다. 또한 실험을 진행하면서 git에 커밋되지 않은 임시 변경 사항까지 캡처할 수 있도록 코드를 자동으로 버전 관리하기 시작합니다.
@weave.op 데코레이터가 적용된 함수를 하나 만들기만 하면 됩니다.
아래 예시에서는 도시에서 방문할 장소를 추천하는 함수 recommend_places_to_visit가 있으며, 이 함수는 @weave.op으로 감싸진 함수입니다.
import os
import weave
from groq import Groq
weave.init(project_name="groq-test")
client = Groq(
api_key=os.environ.get("GROQ_API_KEY"),
)
@weave.op()
def recommend_places_to_visit(city: str, model: str="llama3-8b-8192"):
chat_completion = client.chat.completions.create(
messages=[
{
"role": "system",
"content": "You are a helpful assistant meant to suggest places to visit in a city",
},
{
"role": "user",
"content": city,
}
],
model="llama3-8b-8192",
)
return chat_completion.choices[0].message.content
recommend_places_to_visit("New York")
recommend_places_to_visit("Paris")
recommend_places_to_visit("Kolkata")
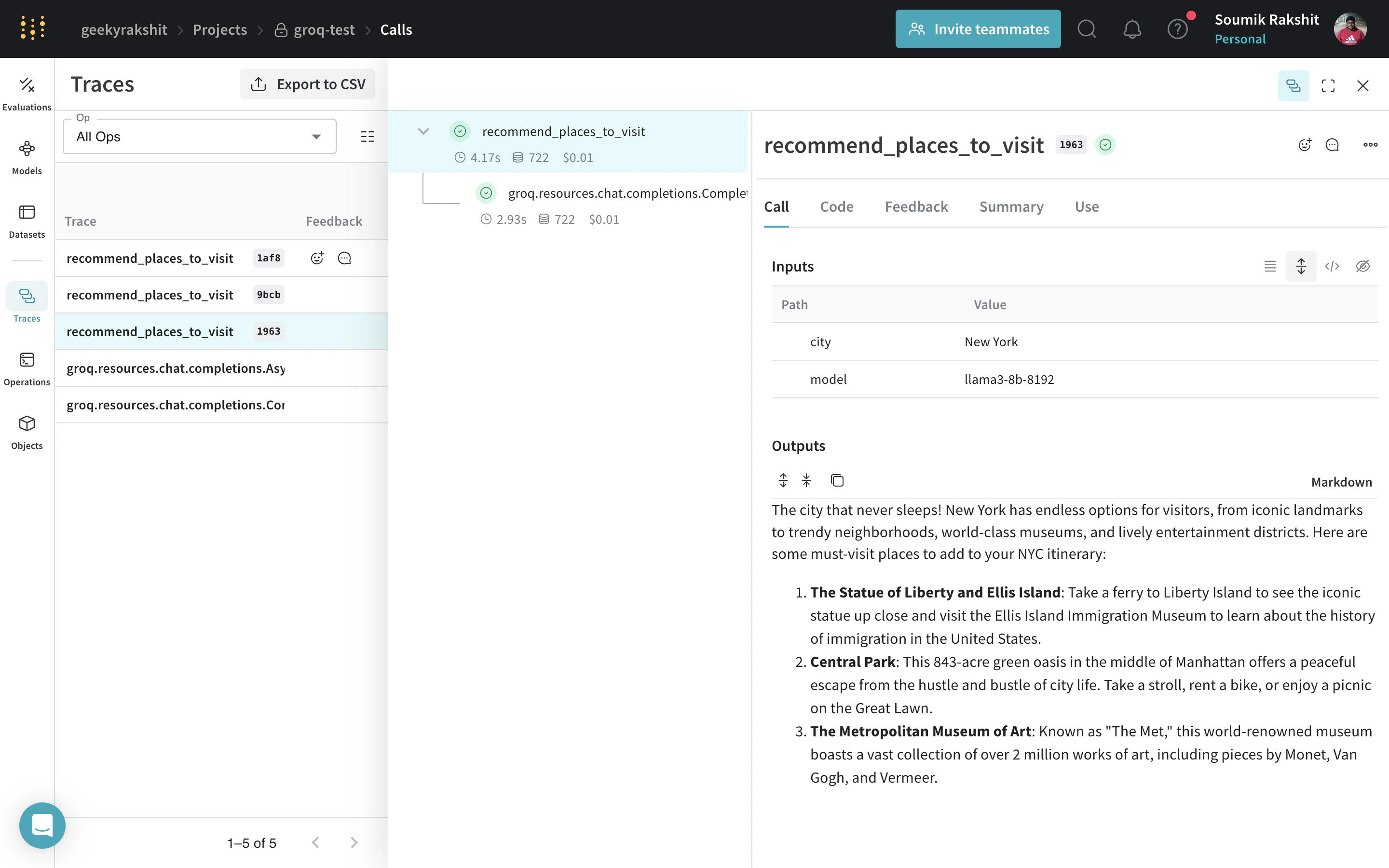 |
|---|
recommend_places_to_visit 함수에 @weave.op 데코레이터를 적용하면 입력과 출력, 그리고 함수 내부에서 이루어지는 모든 LM 호출이 추적됩니다. |
Model 클래스를 사용하면 시스템 프롬프트나 사용 중인 모델처럼 앱의 실험 세부 설정을 기록하고 구성할 수 있습니다. 이렇게 하면 앱의 서로 다른 반복 버전을 정리하고 비교하는 데 도움이 됩니다.
코드 버전 관리와 입력/출력 기록 외에도 Model은 애플리케이션 동작을 제어하는 구조화된 파라미터를 캡처하여 어떤 파라미터가 가장 잘 작동했는지 쉽게 찾을 수 있도록 해 줍니다. 또한 Weave 모델은 serve 및 Evaluation과 함께 사용할 수도 있습니다.
아래 예시에서는 GroqCityVisitRecommender로 실험해 볼 수 있습니다. 이 설정들 중 하나를 변경할 때마다 GroqCityVisitRecommender의 새로운 버전이 생성됩니다.
import os
from groq import Groq
import weave
class GroqCityVisitRecommender(weave.Model):
model: str
groq_client: Groq
@weave.op()
def predict(self, city: str) -> str:
system_message = {
"role": "system",
"content": """
당신은 도시에서 방문할 장소를 추천해주는 유용한 어시스턴트입니다
""",
}
user_message = {"role": "user", "content": city}
chat_completion = self.groq_client.chat.completions.create(
messages=[system_message, user_message],
model=self.model,
)
return chat_completion.choices[0].message.content
weave.init(project_name="groq-test")
city_recommender = GroqCityVisitRecommender(
model="llama3-8b-8192", groq_client=Groq(api_key=os.environ.get("GROQ_API_KEY"))
)
print(city_recommender.predict("New York"))
print(city_recommender.predict("San Francisco"))
print(city_recommender.predict("Los Angeles"))
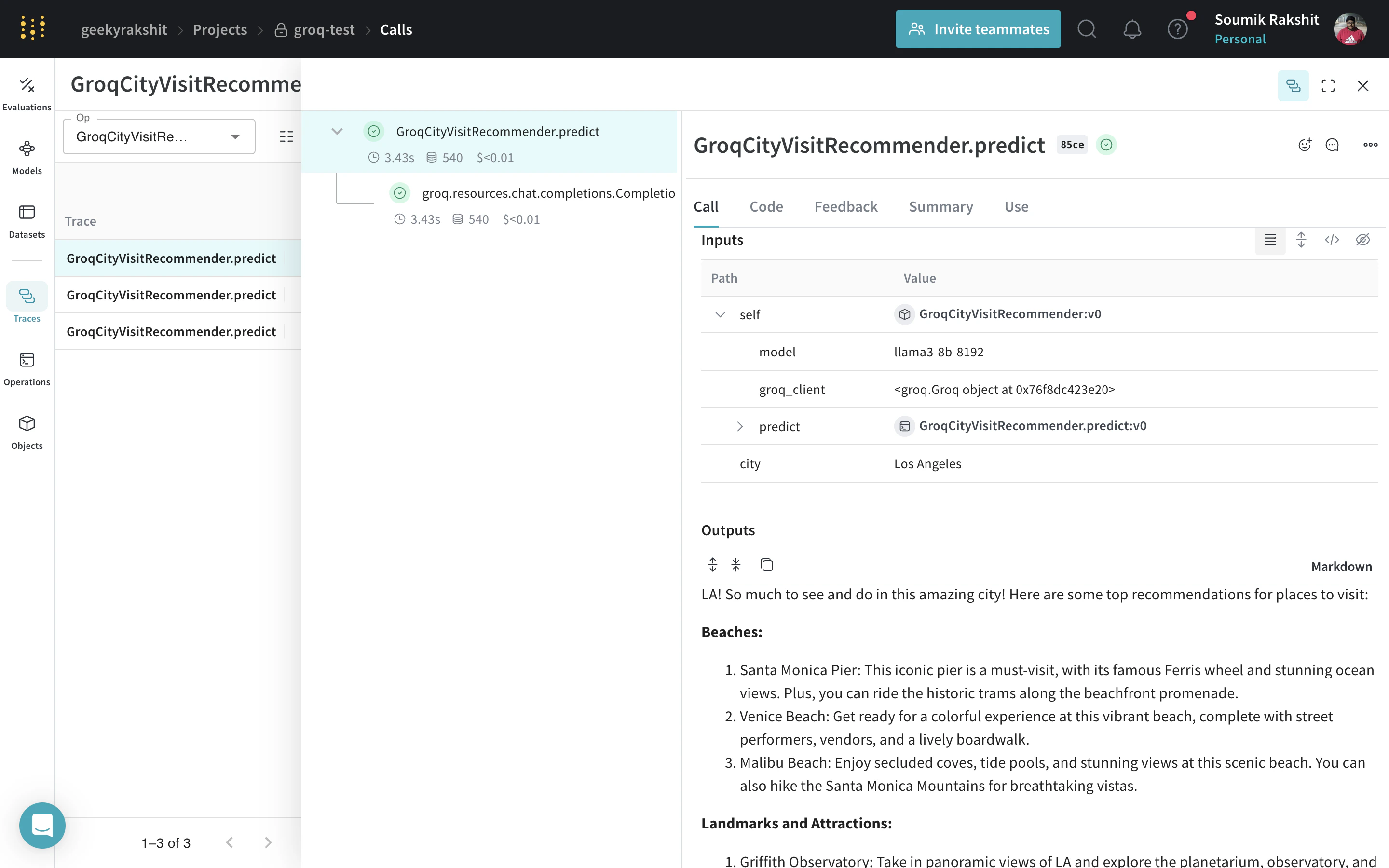 |
|---|
Model을 사용한 호출 트레이싱 및 버저닝 |
weave.Model 객체에 대한 weave reference가 있으면 fastapi 서버를 실행해 서빙할 수 있습니다.
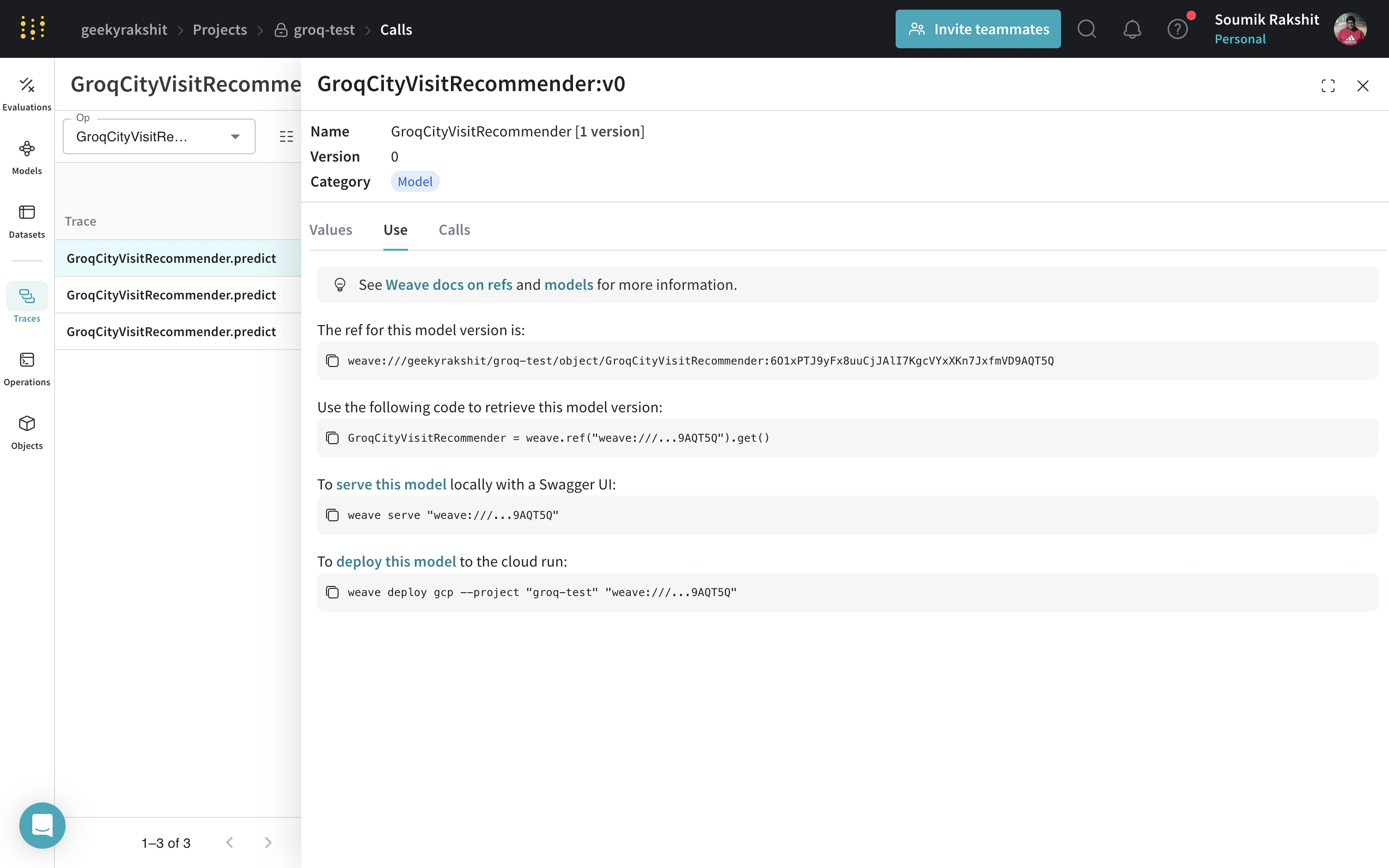 |
|---|
| 모델로 이동한 다음 UI에서 복사하여 어떤 WeaveModel이든 해당 weave reference를 확인할 수 있습니다. |
weave serve weave://your_entity/project-name/YourModel:<hash>